@anthonygitter Re the typo: (1) we random sample from all possible mutation sites for the 4-site targets, (2) we treat those not tested in the original dataset as invalid. We will revise them in our next version. 2/
@anthonygitter Thanks for the constructive feedback! We'd be happy to talk more about more realistic evaluation targets, we agree the targets and ML oracles are not ideal! 1/
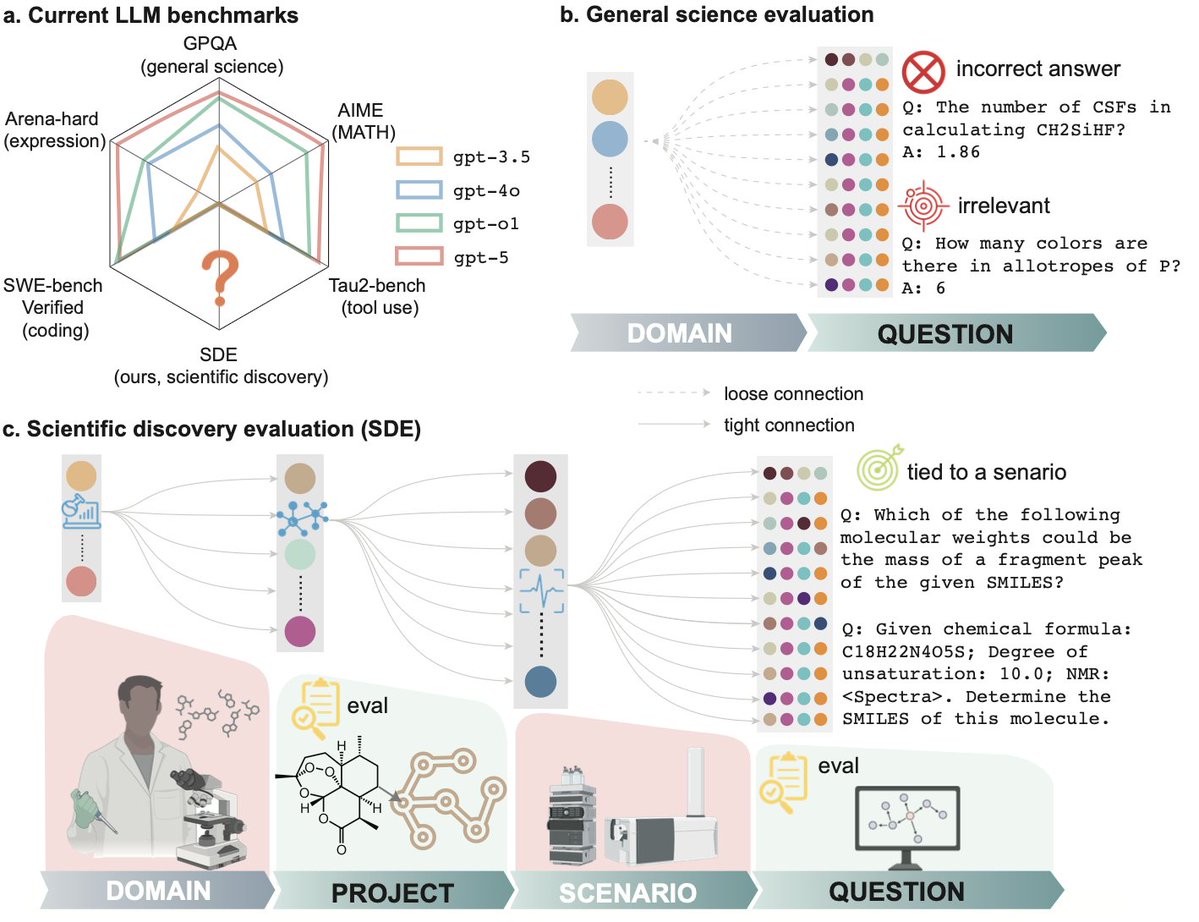
Benchmarks shouldn’t be school exams. SDE tests whether LLMs can do science: hypothesize, experiment, analyze, iterate. 8 projects, 43 scenarios, 1125 questions, built with 50+ scientists. 🧪⚛️
Is LLM ready for real scientific discovery? To find out, we gathered 50+ scientists from 20+ institutions establishing a multi-level evaluation framework: Not only on questions, but also on research scenarios and projects
Current science benchmarks (like GPQA and MMMU) ask AI to answer quizzes. But science isn't a quiz. It’s an iterative loop of hypothesis, experiment, and analysis. Mastery of static, decontextualized questions, even if perfect, does not guarantee readiness to discovery, just as earning straight A’s in coursework does not indicate a great researcher.
Today, we introduce Scientific Discovery Evaluation (SDE): A benchmark grounded in real-world research projects. There, research projects are decomposed into modular research scenarios from which vetted questions are sampled. LLMs are evaluated on
1. Question-level: targeted, expert-written problems embedded in real research scenarios (elucidating structure from NMR, forward reaction prediction, etc.), NOT sub-domains (analytical chemistry, inorganic materials, etc.)
2. Project-level: realistic scientific discovery loops (e.g., molecular design, materials discovery, protein engineering) where models must iteratively propose, test, and refine hypotheses.
With a joint force of 50+ scientists from 20+ institutes, we gathered 8 projects, 43 research scenarios, and 1125 questions. Evaluation on these multiple levels reveals where current models succeed, where they fail, and why.
It is of great joy to work with a 50+ author team in my first time of life - Thanks to you all for making it happen. @hello_jocelynlu, @YuanqiD, @BotaoYu24, @HowieH36226, @rogerluorl18, @YuanhaoQ, @YinkaiW, @Haorui_Wang123, @JeffGuo__, @SherryLixueC, @MengdiWang10, @lecong, @ParshinShojaee@KexinHuang5@chandankreddy, @realadityanandy, @pschwllr, @KulikGroup, @hhsun1, @MoosaviSMohamad, and many others who are not in the x-universe.
Also it’s exciting to see a concurrent release from @OpenAI on FrontierScience yesterday (@MilesKWang)! Their findings on the need for harder, expert-vetted evals, especially the huge performance gap between Olympiad and research questions, echo ours. SDE takes this a step further by moving beyond expert-level Q&A to explicitly evaluate the end-to-end discovery loop with project-level execution, where more finer-grained observations are thereby made possible.
Core Findings Below:
Is LLM ready for real scientific discovery? To find out, we gathered 50+ scientists from 20+ institutions establishing a multi-level evaluation framework: Not only on questions, but also on research scenarios and projects
Current science benchmarks (like GPQA and MMMU) ask AI to answer quizzes. But science isn't a quiz. It’s an iterative loop of hypothesis, experiment, and analysis. Mastery of static, decontextualized questions, even if perfect, does not guarantee readiness to discovery, just as earning straight A’s in coursework does not indicate a great researcher.
Today, we introduce Scientific Discovery Evaluation (SDE): A benchmark grounded in real-world research projects. There, research projects are decomposed into modular research scenarios from which vetted questions are sampled. LLMs are evaluated on
1. Question-level: targeted, expert-written problems embedded in real research scenarios (elucidating structure from NMR, forward reaction prediction, etc.), NOT sub-domains (analytical chemistry, inorganic materials, etc.)
2. Project-level: realistic scientific discovery loops (e.g., molecular design, materials discovery, protein engineering) where models must iteratively propose, test, and refine hypotheses.
With a joint force of 50+ scientists from 20+ institutes, we gathered 8 projects, 43 research scenarios, and 1125 questions. Evaluation on these multiple levels reveals where current models succeed, where they fail, and why.
It is of great joy to work with a 50+ author team in my first time of life - Thanks to you all for making it happen. @hello_jocelynlu, @YuanqiD, @BotaoYu24, @HowieH36226, @rogerluorl18, @YuanhaoQ, @YinkaiW, @Haorui_Wang123, @JeffGuo__, @SherryLixueC, @MengdiWang10, @lecong, @ParshinShojaee@KexinHuang5@chandankreddy, @realadityanandy, @pschwllr, @KulikGroup, @hhsun1, @MoosaviSMohamad, and many others who are not in the x-universe.
Also it’s exciting to see a concurrent release from @OpenAI on FrontierScience yesterday (@MilesKWang)! Their findings on the need for harder, expert-vetted evals, especially the huge performance gap between Olympiad and research questions, echo ours. SDE takes this a step further by moving beyond expert-level Q&A to explicitly evaluate the end-to-end discovery loop with project-level execution, where more finer-grained observations are thereby made possible.
Core Findings Below:
Molmo2 is here!
Have spent the whole year working on the data part and else. It’s a great opportunity to apply what I’ve learned during my past exploration of data-centric AI and learned a lot more about video models.
Large Language Model is Secretly a Protein Sequence Optimizer
1/ This paper demonstrates that large language models (LLMs), originally trained on massive text datasets, can be effectively used as protein sequence optimizers. By integrating them into a directed evolutionary framework, LLMs optimize protein fitness without further fine-tuning, outperforming traditional random mutation methods.
2/ The authors propose an evolutionary method where LLMs generate new protein sequence candidates by performing mutations or crossovers on parent sequences, optimizing for high fitness while keeping edits minimal, even with constrained budgets.
3/ The study tests the LLM-based method across multiple optimization tasks, including single-objective, constrained, and multi-objective optimization, using both synthetic and experimental fitness landscapes. Results show that LLMs outperform traditional evolutionary algorithms (EA) on several benchmarks, especially in non-linear fitness landscapes.
4/ A significant innovation of this work is using LLMs directly to propose sequences for evolutionary processes, making the optimization of protein sequences faster and more efficient, especially when budget constraints or fitness landscapes are complex.
5/ The method is applied to several datasets, including Green Fluorescent Protein (GFP) and Adeno-Associated Virus (AAV) sequences, where the LLM-guided approach consistently yields higher fitness scores than baseline evolutionary algorithms.
6/ The researchers highlight the flexibility of LLMs in optimizing protein sequences, not only for single-objective tasks but also for more complex, multi-objective optimization, demonstrating their potential for high-throughput experiments and real-world applications in protein engineering.
7/ The work offers a promising alternative to conventional directed evolution, which often faces challenges such as slow progress and suboptimal convergence, by harnessing the power of LLMs to efficiently explore vast sequence spaces and identify high-performance variants.
@sohahassoun@xiaolinxu1@lipingliulp@CanalJiananLi@XiaohuiC16528@YuanqiD@jacksonleihao@YinkaiW
📜Paper: https://t.co/SSllydThWo
#ProteinEngineering #DirectedEvolution #MachineLearning #LLM #Bioinformatics #SyntheticBiology #ProteinOptimization
📢📢📢 Happy to introduce Graph Generative Pre-trained Transformers (G2PT):
Can we tokenize graphs and train an autoregressive (AR) model with generative pre-trained transformers to generate graphs?
A new work led by @XiaohuiC16528, @YinkaiW, @jacksonleihao.
A thread 🧵1/6
Does your transformer have a class token to predict? If so you may want to apply normalization separately for that token: https://t.co/fOSuBXjNIk --> see you at #NeurIPS2023 . (PS: the main idea is from students :))
Happy to announce our new initiative AI4Science101. We wrote a series of documents to encourage knowledge sharing and collection in AI for Science from both the view of AI and Science researchers to motivate them to learn, join and work on AI for Science.
https://t.co/VAL6kuSqyY
Here it is: the first Learning on Graphs Conference! 🎊
We think this new venue will be valuable for the Graph/Geometric Machine Learning community.
What makes it so important+unique? See our blog post!
https://t.co/WPPbxxLjrE
1/6
Machine learning for molecule design is a fast-growing field with massive literature, to the best of our knowledge, we are the first to **comprehensively** review this field, the preprint is now available at Arxiv https://t.co/6tweOqJUfi.
In real world, noisy or incomplete graphs inevitably lead to unsatisfactory performance. To address the problem, researchers seek to simultaneously optimize the graph structure along with representations, to which we refer as graph structure learning. 1/2
https://t.co/EnxoPIna9m
If you are working on or interested in graph generation, you may want to check out our recent survey about deep graph generation with methods and applications, available in Arxiv now https://t.co/fD18i4HnZL.