"See you in 2 weeks"
My response to the unknown: Don't run, commit to returning with insights in 14 days.
Strategy: Commit first, figure it out later. Pressure creates diamonds.
What's your "2 weeks" challenge? 🚀
#GrowthMindset#Challenge
Most Markdown apps open into an editor.
CmdMD opens into a reader.
It's review-first. Like reviewing a pull request — you read first, and editing is one keystroke away. Open a file and it's already rendered, beautifully. Need to edit? It's right there.
Most notes aren't reopened to rewrite them. They're reopened to check them. Yet most editors hand you a blinking cursor first. That order is backwards.
There's a second move. A reviewed note has to go somewhere. CmdMD routes it — one shortcut sends it to the right folder in the right Obsidian vault, with rules (by tag, filename, content), templates, and per-vault inboxes. Read, then send. One key each. A note has no reason to stay trapped in one app.
Last thing, and it's the real story: nobody sold me this app. I needed it, so I built it with Claude Code — a native macOS app, exactly the way I wanted it. Mermaid, KaTeX, 7 preview themes, Omnisearch, fully remappable shortcuts. Open source. Free.
We're moving from choosing tools to compiling the ones we need. AI just dropped the cost of that to near zero.
▶ Site + free download (open source · macOS)
https://t.co/xVTwo4nxNX
Source (GitHub): https://t.co/GAVC2oDSWy
#Obsidian #PKM #Markdown #macOS #ClaudeCode #OpenSource #BuildInPublic
❗이번주 토요일(6/26)
커맨드스페이스에서 LLM Wiki를 주제로 포럼을 개최합니다.
🌟 지속가능한 LLM Wiki, 어떻게 가능할까요?
LLM Wiki 운영을 위한
마인드셋·개념부터 실제 활용 사례까지.
서로 공유하고 논의하는 자리입니다.
👇5명의 연사 프로그램 구성은 첨부 이미지에서 확인하실 수 있습니다.
---
일시: 2026.06.27. (토) 9-12시
장소: 온라인(Zoom)
혜택: 다시보기·요약 자료 제공, 사전 설문·라이브 질문 바탕의 Q&A
자세히보기: https://t.co/zjlvXwLmME
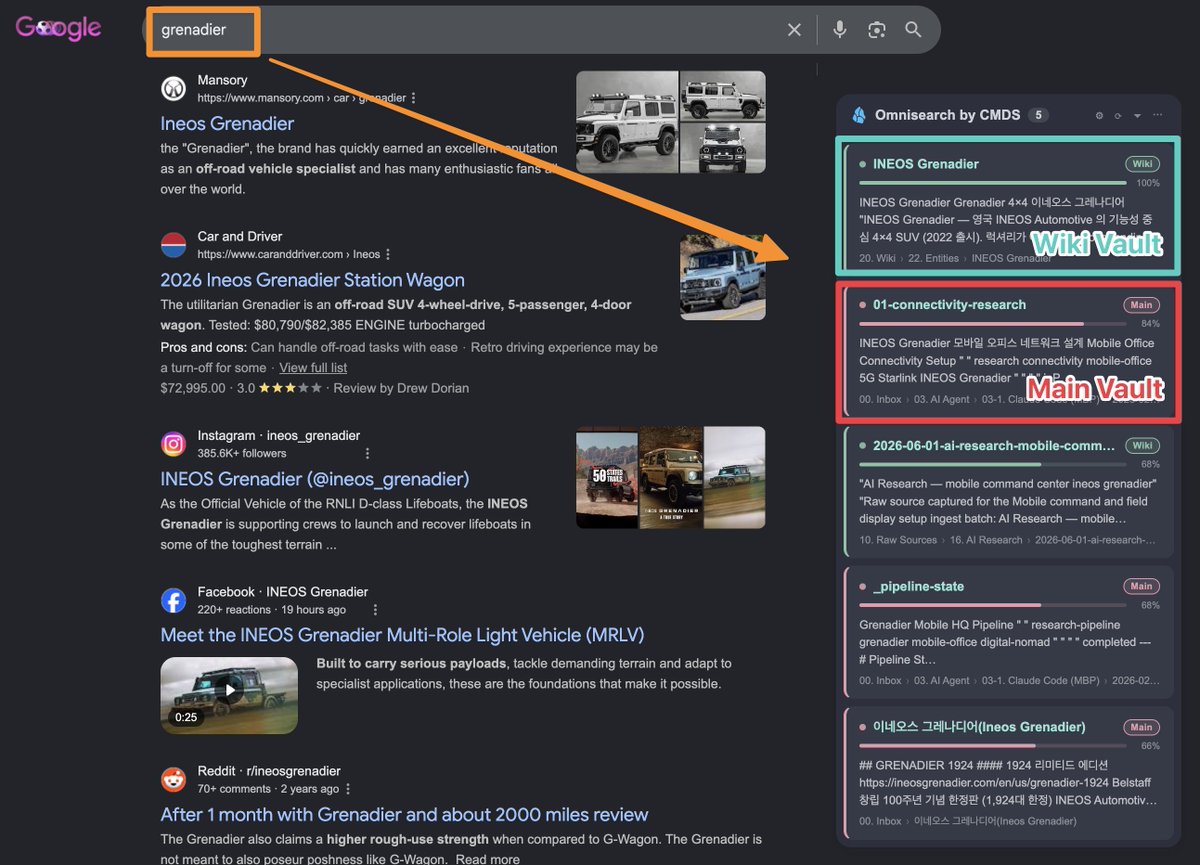
I extended Obsidian's search beyond the note app — out to the Google search bar.
When I search Google, my vault answers on the same screen. The web is Google's job; the knowledge I've built is my vault's. One query, two knowledge bases side by side.
How people use their tools differs, so this isn't a should-do for everyone. It's one usage pattern I'm proposing: treating Obsidian less as an app you go into to search, and more as a layer you can call up where you already work.
What gets searched is the point:
- My mothership vault (personal knowledge) and my LLM-wiki satellite (compiled knowledge), queried at once.
- In Karpathy's terms, Obsidian is the IDE and the wiki is the codebase — and now I query that codebase from the browser too.
- Ranked by relevance, frontmatter stripped, real body previews and actual tags inline. Click to open straight in Obsidian.
Under the hood, Omnisearch's HTTP server and the Local REST API turn the vault into a queryable knowledge service. The browser becomes another client of it — Obsidian extended one layer outward.
It started as Simon Cambier's userscript. I forked it hard — multi-vault, Local REST body sync, a full theme system — built with Claude Code, iterating from v0.4 to v0.13 live.
Open source:
https://t.co/JeaamliIXG
Obsidian can reach further — to wherever the knowledge is needed.
What separates people who get the most out of LLMs from those who don't?
Not the model.
The harness.
How you shape the context, define the schema, and structure the workspace the model operates in — that's where 90% of the output quality is decided.
Karpathy's LLM Wiki pattern is one expression of this. Don't throw raw sources at the LLM. Put a wiki layer in between pages linked together, compiled and curated by you, maintained by the LLM. Queries flow through it. Answers flow back into it.
The LLM isn't smart. The context structure you build is what makes it operate smartly.
Made a 5-min video on it.
https://t.co/5DavBtDcxk
CMDS LLM Wiki Bootcamp Cohort 1 (open now)
I spent a lot of time on the structural design of Obsidian.
A main vault for the notes I write myself, and a Wiki vault maintained by AI.
Ships with the schema, a vault starter kit, and maintenance skills for personal customization.
The next step from stacking notes to operating knowledge.
May 5 (Tue), 13:00–17:00 KST · Children's Day in Korea
Holiday, but let's grow together.
https://t.co/C7WYKqaztc
After 10,000+ notes in Obsidian over 3 years,
I learned a brutal truth:
"taking notes" and "building reusable knowledge"
are two completely different jobs.
Most "AI-powered second brains" only solve the first.
The default LLM Wiki today looks like this:
"Ask GPT → paste into Obsidian → done."
That's not a wiki.
That's a more expensive notepad.
No retrieval. No citation. No compounding.
The word "wiki" only earns its meaning
when three things are true:
① The Raw stays immutable.
② The Wiki itself is compiled by an LLM.
③ Past Queries flow back into the Wiki as new pages.
This is Karpathy's LLM Wiki pattern.
Raw Sources → Wiki → Queries
The critical part is the last arrow.
Most systems end at "ask question, get answer."
The answer evaporates.
A real wiki bakes that answer back
into a page where it becomes
the next person's starting point.
If this loop doesn't run,
you don't have a wiki — you have an inbox.
Second insight.
"Search" isn't one thing either.
In my setup, 5 methods coexist:
• BM25 — word frequency
• Vector — meaning embeddings
• HyDE — hypothetical answer search
• Grep — distribution matching
• Graphify — graph structure
Throw the same question at all five
and you'll get five different answers.
That's not a flaw.
Each algorithm sees a different signal.
BM25 sees lexical surface.
Vector sees semantic distance.
Grep sees distribution.
Graphify sees connective structure.
The right question is never
"which one is best?"
It's "which signal does THIS query need?"
The most underrated distinction
in LLM-driven knowledge work:
Access vs Search.
If you know where it is → access it (Read).
If you don't → search for it (qmd / Grep).
Conflate these and your agent
burns tokens "reading everything"
every single turn.
The cost difference shows up in a month.
Third insight.
Single-vault PKM doesn't scale
once you live with LLMs.
I now run 7 active vaults:
🌍 Mothership — human-authored personal PKM
🛰 LLM Wiki — LLM-authored, compiled
🤝 Shared — co-authored with collaborator
🤖 Product — product context (human + LLM)
💼 Admin — business operations
📤 Published — public showcase
People always ask:
"Isn't that just fragmentation?"
No. It's division of labor.
The deciding question isn't
"what's the topic?"
It's:
• Who is the primary author?
• Who has merge authority?
• What is its lifespan?
Different agreement models → different vaults.
Mix LLM-generated pages
and human-authored insights
into one folder, and the trust signal collapses.
You can't tell who wrote what.
You can't trust what compounds.
The fix isn't tagging.
The fix is structural separation.
Obsidian wikilinks don't cross vault boundaries.
But search engines like qmd do.
That asymmetry is the core design move
of multi-vault operation.
Each vault runs at its own pace,
under its own consensus model —
but the search layer stays unified.
Tonight I'm teaching all of this
at the April Monthly Obsidian (Seoul).
Two hours, three threads:
① Building a compiling LLM Wiki
② Five search methods, when to use which
③ Mothership × Satellite vault architecture
📅 2026.04.30 · 19:30 KST
📍 Yeongdeungpo (offline) + Zoom (online)
→ https://t.co/yuVZ6dPO2C
Anyone can buy the tools.
A reusable knowledge system has to be designed.
Tonight I'm sharing the blueprint
that took 3 years of trial and error to draw.
That sounds like an interesting experiment. I’m looking forward to it. By the way, I’m a friend of Brian’s. I’m also part of the Obsidian Korean translation team, and we co-hosted Obsicon in Korea two years ago.
Jazz is one of the pillars of my work at Obsidian, so I’ll be sure to share lots of interesting case studies.
@shotovim My name is Yohan Koo, and I teach Obsidian in Korea. Please take a look at the system I’ve developed. If you ever come to Korea, it would be great to chat. Or perhaps I could stop by and say hello if I ever visit Japan?
https://t.co/yPkZRnROIw
@kepano I sometimes organize the jazz pieces I’m learning in Obsidian Notes, and I think it might be fun to jot down notes on the chord progressions as well.
If you use a MacBook for serious work, you've probably hit these:
- Overnight sync stopped because the Mac went to sleep
- SSH session died after closing the lid
- Mac fell asleep during a presentation waiting room
- macOS update silently reset your power settings
The root cause is almost always macOS power management defaults.
One command — `pmset` — fixes all of this. But the options are many, AC and battery need separate configs, and you need different settings for different situations.
So I put together a guide:
✅ pmset option reference (what each setting actually does)
✅ AC baseline + 3 battery presets (A/B/C)
✅ 7 scenario-based recommendations
✅ 4 Raycast Script Commands for one-click switching
✅ Passwordless sudoers setup
One thing most people don't know: Power Nap (DarkWake) only wakes Apple system services. Third-party apps like Synology Drive or Claude Code won't run during DarkWake — they need a full wake.
👉 https://t.co/pAi1euOBui
After 4 years and 10,000+ notes, I'm open-sourcing the rules that hold my Obsidian vault together.
🏛 CMDS System Files (v4.2)
— 5 core system files (shared across Claude Code · Gemini · Codex)
— 7 shared rules
— 8 slash commands: Connect → Merge → Develop → Share
These files load into every AI session I run. They're how my agents know which folder to use, which frontmatter to attach, which workflow to follow. A document humans read, and a spec AI reads — same source.
Why open it?
Knowledge management is a matter of taste. But the moment that taste crystallizes into rules, it becomes a second brain that AI agents can speak fluently. If anyone forks this and adapts it to their own work, then 4 years of quiet experiments were worth something.
🔗 Landing: https://t.co/zEvv0OitRx
📖 Full docs: https://t.co/RBfhT9Tlho
⎔ GitHub: https://t.co/Jdga1g0g0J
Fork the architecture. Keep the philosophy.
#PKM #Obsidian #SecondBrain #AI #CMDS
I think knowledge management in the AI era is moving
from accumulation to structure,
from organization to connection.
A large number of notes does not automatically become knowledge.
And searchable information does not automatically become an asset.
In tonight’s The Better TalkTalk,
I will use Karpathy’s idea of the LLM Wiki as a starting point
to talk about why Obsidian should be treated not just as a note-taking app,
but as a structure for thinking.
I will also share the ideas that have shaped my own work,
including the principle of the Special Generalist
and the CMDS schema principles for knowledge management.
If you have ever wondered
how your notes can become something more than stored information,
this conversation may be for you.
Tonight at 10 PM KST
https://t.co/eDEl64xfPH
Karpathy said it: "A large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge."
The person who built vibe coding is now doing knowledge management.
Tiago Forte declared PKM is now AI-first.
OpenAI wrote: "The agent isn't the hard part — the harness is."
CLAUDE.md, soul.md, DESIGN.md — what do these files have in common?
They're all harnesses. Structured context you feed to AI.
But where does that context come from?
From a well-organized personal knowledge system.
On April 11, five practitioners who built and run these systems share their architectures:
▸ Jin-Young Kim — Gobi Desktop & Space (AI knowledge sharing)
▸ Yohan Koo — CMDS: 10,000+-note AI-human collaboration architecture
▸ 댕댕이멍멍 — NAS + Git + Obsidian self-hosted knowledge infra
▸ ACH — Obsidian writing workflows beyond legacy formats
▸ GPTers — What changed after OpenClaw automation
📅 Apr 11 (Sat) 14:00–17:00 KST · Online
💰 Early bird ₩10,000 (~Apr 8) / Regular ₩30,000
🎬 Recording included
👉 https://t.co/yMchbAufxE
#AIPKM #HarnessEngineering #Obsidian #PKM #CMDSPACE #ContextEngineering #AIAgent
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: https://t.co/NlAfEJjtJV
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
The contamination point is brilliant and I've been wrestling with exactly this for 3 years in a 10,000+ note vault.
My answer turned out different from vault separation — I chose design over division:
1. AI outputs go to a dedicated path: 00. Inbox/03. AI Agent/{env-subfolder}/
2. Every note has an `author` property — if it's [[me]], I wrote it. Origin is always traceable.
3. `status` lifecycle (unread → completed → archived) separates drafts from verified knowledge
4. System files (CLAUDE.md, AGENTS.md) define the rules AI must follow *before* it writes anything
Why not separate vaults? Because [[wikilinks]] break across vault boundaries. An AI-generated meeting note linking to [[Karpathy]] → [[📚 620 Generative AI]] — that traversal only works in one vault.
Your point about "known origins" is the real insight though. The solution isn't physical separation — it's metadata that makes origins queryable. Dataview can filter `author = me` instantly.
Obsidian is the best tool for this precisely because of what you built: local markdown + YAML frontmatter + graph. That combination is the most AI-friendly knowledge interface that exists.
Thank you for building the foundation that makes all of this possible.
https://t.co/lGRrLUzqZC
This resonates deeply. I've been running a 10,000+ note Obsidian vault (CMDS) with Claude Code for 3 years, and arrived at nearly identical patterns:
Your raw/ → wiki compilation = my Connect → Merge → Develop → Share process
Your AGENTS.md schema = my 5 system files (CLAUDE.md, AGENTS.md, CMDS.md + 2 human docs)
Your "no fancy RAG needed" = exactly right. I call it "Markdown is all you need"
What I'd add from my experience: beyond schema, system files can carry *rules* and *context*. My CLAUDE.md has precedence (priority ordering), STATIC/DYNAMIC markers (cache-aware sections), and Essential sections (core rules that survive context compression).
When AI reads not just "what's here" but "how to behave here" — the wiki quality jumps a level.
Inspired by your tweet, I analyzed Claude Code's source and applied 9 architecture patterns from it to my system files. Open-sourced everything:
https://t.co/lGRrLUzqZC
https://t.co/limIuPbjJC
Thank you for articulating what many of us have been building in silence. This thread will spawn a thousand vaults.
I dug into Claude Code's source and found something interesting about how it reads CLAUDE.md files.
It uses hierarchical precedence to decide which file wins in conflicts. It separates Static sections (cacheable rules) from Dynamic sections (stats that change). And when context gets compressed in long conversations? It recovers only the Essential rules.
That made me think: "Why not apply these exact patterns to my own knowledge management system?"
So I refactored the core file architecture of CMDS — a PKM system managing 10,000+ notes in Obsidian.
9 patterns applied:
1. precedence — file priority ordering (1-5)
2. STATIC/DYNAMIC markers — cache-aware sections
3. @include — shared rules, 60% dedup
4. Essential (Post-Compact) — rules that survive context compression
5. required-for/optional-for — agent scoping
6. memory-type — maps to AI memory categories
7. token-estimate — budget awareness
8. changelog — inline version history
9. shared rules — common rules in separate files
The takeaway: AI performance isn't determined by the model. It's determined by the structure of the context you provide. Same Claude Code, different CLAUDE.md = completely different results.
This goes beyond prompt engineering. It's knowledge architecture.
Open-sourced the entire structure:
Live Demo: https://t.co/zEvv0OitRx
GitHub: https://t.co/Jdga1g0g0J
#KnowledgeManagement #AI #Obsidian #ClaudeCode #PKM
I dug into Claude Code's source and found something interesting about how it reads CLAUDE.md files.
It uses hierarchical precedence to decide which file wins in conflicts. It separates Static sections (cacheable rules) from Dynamic sections (stats that change). And when context gets compressed in long conversations? It recovers only the Essential rules.
That made me think: "Why not apply these exact patterns to my own knowledge management system?"
So I refactored the core file architecture of CMDS — a PKM system managing 10,000+ notes in Obsidian.
9 patterns applied:
1. precedence — file priority ordering (1-5)
2. STATIC/DYNAMIC markers — cache-aware sections
3. @include — shared rules, 60% dedup
4. Essential (Post-Compact) — rules that survive context compression
5. required-for/optional-for — agent scoping
6. memory-type — maps to AI memory categories
7. token-estimate — budget awareness
8. changelog — inline version history
9. shared rules — common rules in separate files
The takeaway: AI performance isn't determined by the model. It's determined by the structure of the context you provide. Same Claude Code, different CLAUDE.md = completely different results.
This goes beyond prompt engineering. It's knowledge architecture.
Open-sourced the entire structure:
Live Demo: https://t.co/zEvv0OitRx
GitHub: https://t.co/Jdga1g0g0J
#KnowledgeManagement #AI #Obsidian #ClaudeCode #PKM
Markdown Is All You Need — 마크다운이라는 선택이 바꾸는 것들
10년 전에 쓴 .hwp 파일을 열어보려다 실패한 경험이 있으신가요?
파일은 존재했습니다. 하지만 지식은 이미 죽어 있었습니다.
이 글은 그 경험에서 시작합니다.
- # 하나가 평면적 텍스트에 사고의 뼈대를 세우는 이야기
- --- 세 줄이 문서를 데이터베이스로 바꾸는 이야기
- ChatGPT, Claude, Gemini가 전부 마크다운으로 답하는 이유
- "나만의 확률값"이 AI 시대의 유일한 차별화 자산인 이유
- 그리고, 같은 곳을 바라보며 뒤에서 걷고 있던 사람들의 이야기
마크다운은 문법이 아닙니다. 생각의 운영체제입니다.
그리고 놀랍게도, 최근 국가인공지능전략위원회에서도 공공 문서 작성 표준을 마크다운으로 채택했습니다.
https://t.co/DLnsQhHrr8
저를 오래 지켜봐 주신 분들은 아실 것입니다.
제가 흔들릴 때마다 다시 저를 세운 것은 결국 기록이었습니다.
짧은 메모 하나에서 시작한 기록은 Obsidian 안에서 연결이 되었고, 연결은 방향이 되었으며, 방향은 다시 저를 성장시켰습니다.
『옵시디언 프로페셔널 노트』는 제가 그렇게 성장해온 방식을 한 권에 담은 책입니다.
도구의 기능만 설명하는 책이 아니라, 기록이 어떻게 사람을 단단하게 만들고 앞으로 나아가게 하는지를 함께 담았습니다.
늘 존경과 신뢰로 지켜봐 주신 분들께 감사한 마음으로 이 책을 전합니다.
이 책이 여러분의 기록에도 새로운 연결과 다음 질문을 열어주면 좋겠습니다.
질문은 언제나 환영입니다.
2주 뒤에 뵙겠습니다.
📚 교보문고: https://t.co/qKlnkg7072
📚 YES24: https://t.co/ENQgys03Uk