Congrats to the team for wining CVPR Best Paper Award!! 🏆 Come to our oral session (Mile High Ballroom 13:00-14:15) and poster (16:00-18:00) today for more details 🚀
✨#CVPR2026 Oral ✨
A tale of a failed experiment: what if you fine-tune DINOv2 on sparse keypoints, beat every benchmark, only to discover it performs worse than the original frozen model on novel keypoints?
🚀MARCO closes this gap: a unified model for generalisable correspondences
https://t.co/vE62YiTVfd
wrote a guide on getting compute grants as a student, something I wish I did more at the beginning of my PhD. It's honestly one of the highest ROI things you can do as a student (we've gotten 100k+ gpu hrs for roughly 2 weeks of work writing).
https://t.co/U15nwau88a
📢GaussianGPT: autoregressive 3D Gaussian scene generation.
We introduce a GPT-style model that directly generates 3D Gaussian scenes, token by token, in a series of small, discrete decision steps. Generation, completion, and large-scale outpainting in a single pipeline.
Unlike diffusion-based approaches, GaussianGPT explicitly models the scene distribution at every step, allowing for quite flexible scene synthesis.
🌐 https://t.co/Ewv4CyLD2O
▶️ https://t.co/zKOugfD9gl
Great work by @nicolasvluetzow, @barbara_roessle, @katha_schmid
VLMs today—including our own Molmo—point via raw text strings (e.g. "<x=0.53, y=0.71>"). What if pointing meant directly selecting the visual tokens instead? 🤔
Introducing MolmoPoint: Better Pointing for VLMs with Grounding Tokens 🎯
🔓models, code, data, demo all OPEN 🧵👇
Paper: https://t.co/vTH5vnLckN
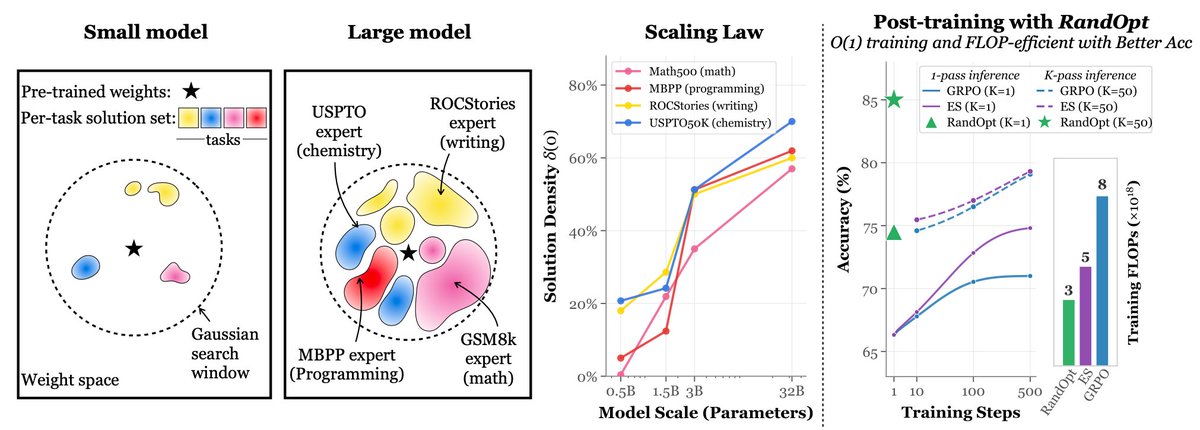
Simply adding Gaussian noise to LLMs (one step—no iterations, no learning rate, no gradients) and ensembling them can achieve performance comparable to or even better than standard GRPO/PPO on math reasoning, coding, writing, and chemistry tasks. We call this algorithm RandOpt.
To verify that this is not limited to specific models, we tested it on Qwen, Llama, OLMo3, and VLMs.
What's behind this? We find that in the Gaussian search neighborhood around pretrained LLMs, diverse task experts are densely distributed — a regime we term Neural Thickets.
Paper: https://t.co/rFJz2kVEOA
Code: https://t.co/HAmonfpXIA
Website: https://t.co/QZ6AMIsKCw
Working on multimodal machine learning and missed the main #CVPR2026 deadline, but still want to convince your supervisor to send you to Denver?
Then consider submitting your novel work to the MULA Workshop! 😊
More info here: 🌍 https://t.co/n66pA6N9qg
✨Thinking with Blender~
Meet VIGA: a multimodal agent that autonomously codes 3D/4D blender scenes from any image, with no human, no training!
@berkeley_ai#LLMs#Blender#Agent 🧵1/6
What if we can simulate an *interactive 3D world*, from a single image, in the wild, in real time?
Introducing PointWorld-1B: a large pre-trained 3D world model that predicts env dynamics given RGB-D capture and robot actions.
🌐 https://t.co/ShGZm3hAWi
from @Stanford@nvidia
Performance Hints
Over the years, my colleague Sanjay Ghemawat and I have done a fair bit of diving into performance tuning of various pieces of code. We wrote an internal Performance Hints document a couple of years ago as a way of identifying some general principles and we've recently published a version of it externally.
We'd love any feedback you might have!
Read the full doc at: https://t.co/jej95g236P
Text-to-image diffusion transformer models learn to align text and image representations as a byproduct of their conditional denoising task.
By taking the dot product between the text and image representations of a DiT model (like Flux 2), you can create rich saliency maps.
Unless a significant paradigm shift lowers the computational demands of SOTA methods, computer vision researchers in academia will be reduced to mere consumers of models from industry labs. https://t.co/MSi4Z9UI5C
📢 Phillip Isola @phillip_isola, Saining Xie @sainingxie, and I @zamir_ar are hiring joint postdocs in machine learning with a focus on multimodal learning. What brings us together is our shared interest in multimodality and our intention to move the boundaries of current approaches in this area. Our team has access to substantial compute resources through the Swiss National Supercomputing Centre Swiss AI initiative and our industry partners. The postdocs will work at the intersection of our groups. For now the positions will be based at EPFL with visiting stays at MIT and NYU, and will be co-advised by two or all three of us.
🔗 Apply here if interested: https://t.co/4vkUCuPT0Z
Google and ETH have joined the large scale localization effort with a banger
I really did not expect this
And now I'm really hoping to make it to NeurIPS where the paper will be presented
I'll read it and report a summary here in the next few days
Tired to go back to the original papers again and again? Our monograph: a systematic and fundamental recipe you can rely on!
📘 We’re excited to release 《The Principles of Diffusion Models》— with @DrYangSong, @gimdong58085414, @mittu1204, and @StefanoErmon.
It traces the core ideas that shaped diffusion modeling and explains how today’s models work, why they work, and where they’re heading.
🧵You’ll find the link and a few highlights in the thread.
We’d love to hear your thoughts and join some discussions!
⚡ Stay tuned for our markdown version, where you can drop your comments!
The hot topic at #ICCV2025 was World Models.
They come in different flavors — (interactive) video models, neural simulators, reconstruction models, etc. — but the overarching goal is clear: Generative AI that predict and simulate how the real world works.
🛰️ Excited to share Skyfall-GS - the FIRST method to create real-time navigable 3D cities from satellite imagery alone!
We transform multi-view satellite images into immersive 3D scenes you can freely fly through! 🚁✨
🌐 Project Page: https://t.co/QsLVaD7mAg
1/5
VLAs, VLMs, LLMs, and Vision Foundation Models for Embodied Agents!
There are just so many new updates in recent months!
We have updated our tutorial, come and join us if you would like to discuss the latest advances!
Room: 306B
Time: 1pm-5pm
Slides: https://t.co/HaC5AQdHcn
Together with @YunzhuLiYZ@maojiayuan@wenlong_huang . Excited to see you here to discuss the latest advances!