If you’re interested, check out our code and models.
Code: https://t.co/ThD30I18PP
Model zoo: https://t.co/trGILuImkE
Paper: https://t.co/3YOvKjwhi0
Thanks to everyone who stopped by to chat about long context, efficient reasoning, and the future of hybrid architectures.
Had a great time presenting “Gated KalmaNet (GKA): A Fading Memory Layer Through Test-Time Ridge Regression” at #CVPR2026 with @achatto1994 and @PengLiangzu.
Thanks to everyone who stopped by to chat about long context, efficient reasoning, and the future of hybrid models.
One of my favorite parts has been seeing which questions people ask. This year, many conversations revolved around a simple idea:
Can we explore post-Transformer models without retraining from scratch?
That's exactly the motivation behind Priming and Hybrid Model Factory.
It's remarkable to see such an elegant idea work so well in practice (and scale so seamlessly on Tensor Cores).
DM me if you want to brainstorm in person about Hybrid models, test-time scaling, and where long-context AI Agents are headed.
#CVPR2026 is around the corner and we're excited to share Gated KalmanNet: A Fading Memory Layer through Test-Time Ridge Regression. Looking forward to meeting everyone who wants to learn more.
Gated KalmaNet (GKA, pronounced "gee-ka") generalizes Mamba-2 and Gated DeltaNet, and outperforms both under identical training conditions. It also works beyond language: swapping the Mamba layer in MambaVision for GKA improves ImageNet accuracy with no vision-specific tuning.
1/4
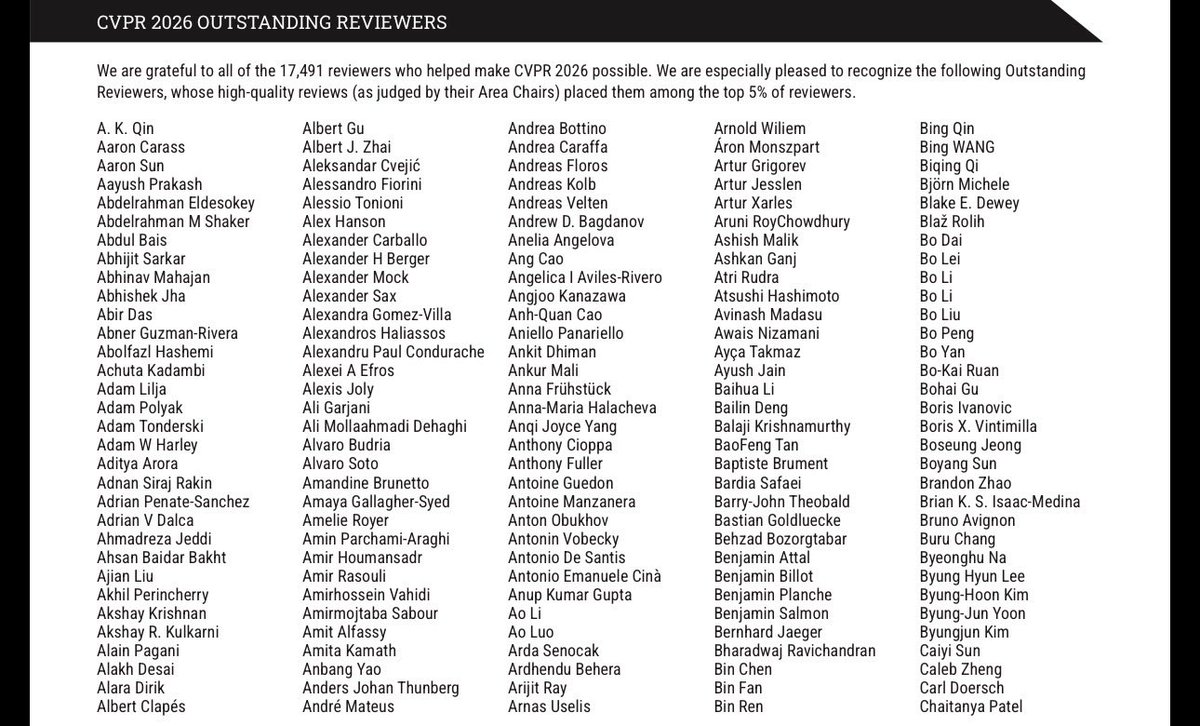
We are grateful to all of the 17,491 reviewers who helped make #CVPR2026 possible. We are especially pleased to recognize the following Outstanding Reviewers, whose high-quality reviews (as judged by their Area Chairs) placed them among the top 5% of reviewers.
A year ago we started working on Hybrid (SSM+Attention) scaling: B'MOJO, Gated KalmaNet, Marconi, PICASO. Today we're releasing our full stack: training code for long context, 8B/32B checkpoints, fast Triton kernels, custom vLLM plugin and ... our Priming method, all Apache 2.0.
Introducing Priming
Hybrid models are faster and cheaper than Transformers to scale. But developing alternative architectures from scratch requires expensive pre-training runs.
Priming solves this by leveraging pre-trained Transformer weights to train equally performant Hybrid models with 2× faster throughput. Builders can now iterate on Hybrid architectures for under 150B tokens, 100× cheaper than pre-training.
1/12