Most AI investing happens downstream of the frontier: a capability emerges, a category gets named, and capital rushes in.
But by the time a category earns a clean box on a market map, the best builders have usually been living in the messy version for months.
Agents. Reasoning. RL environments. World models. AI for Science. Recursive self-improvement.
I call this frontier proximity: the ability to see what is becoming possible before it becomes consensus.
My frontier proximity ladder:
L0 Wrapper: uses today’s models.
L1 Reactor: reacts fast to releases, but roadmap is downstream.
L2 Anticipator: builds for where capabilities are going.
L3 Native: depends on a non-obvious frontier bet.
L4 Shaper: helps move the frontier itself.
The point is not that every company needs to train models.
Apps can have high frontier proximity if they understand what models will make possible next.
Infra can have high frontier proximity if it knows what future agents, multimodal systems, robotics stacks, or scientific workflows will need.
That is why we’re launching MoE Capital.
MoE stands for Mixture of Experts.
The idea is simple: build an AI fund around people closest to the frontier: frontier researchers, technical founders, AI-native builders, and seasoned operators.
We don’t want to be another AI fund with a newsletter-level understanding of the frontier.
We want to build the AI fund closest to the frontier.
More in The Information: https://t.co/CXWJAy34zi
Had a great time presenting “Gated KalmaNet (GKA): A Fading Memory Layer Through Test-Time Ridge Regression” at #CVPR2026 with @achatto1994 and @PengLiangzu.
Thanks to everyone who stopped by to chat about long context, efficient reasoning, and the future of hybrid models.
Results across three settings:
Pure SSM at 2.8B, head-to-head with Mamba-2, Gated DeltaNet and Gated Linear Attention
• Best average on LM Eval Harness across SSM baselines
• Strongest SSM on recall tasks (FDA, SWDE), closing the gap with Attention
Hybrid GKA at 8B:
• Beats Hybrid Mamba-2 and Hybrid Gated DeltaNet on long-context RULER @128K, well beyond the 8K context prior SSM hybrids typically report
Hybrid GKA at 32B:
• Up to 1.5x faster than Qwen3 32B on AIME 2025 while matching accuracy.
Vision:
• GKA can be used as a drop-in replacement in MambaVision and outperforms Mamba on ImageNet, is faster than ViT, and requires no vision-specific tuning.
See you at #CVPR2026.
3/4
#CVPR2026 is around the corner and we're excited to share Gated KalmanNet: A Fading Memory Layer through Test-Time Ridge Regression. Looking forward to meeting everyone who wants to learn more.
Gated KalmaNet (GKA, pronounced "gee-ka") generalizes Mamba-2 and Gated DeltaNet, and outperforms both under identical training conditions. It also works beyond language: swapping the Mamba layer in MambaVision for GKA improves ImageNet accuracy with no vision-specific tuning.
1/4
Check out prior work from our team that laid the groundwork for Priming:
Our papers:
• Gated KalmaNet: A Fading Memory Layer Through Test-Time Ridge Regression https://t.co/WRjfrXg7KH
• B'MOJO: Hybrid State Space Realizations of Foundation Models with Eidetic and Fading Memory https://t.co/vp396wI2Jq
• PICASO: Permutation-Invariant Context Composition with State Space Models https://t.co/ffhZW74Rb0
• Marconi: Prefix Caching for the Era of Hybrid LLMs https://t.co/sea0XDlEON
• Expansion Span: Combining Fading Memory and Retrieval in Hybrid State Space Models https://t.co/iiP3ASk3Ub
• Learning When to Attend: Conditional Memory Access for Long-Context LLMs https://t.co/UJUrf4VDsb
ASAP seminars:
• GKA: https://t.co/Fbflcu3xcY
• B’MOJO: https://t.co/vvMi2p0rk1
Priming has also built upon the solid foundations described in:
• The Mamba in the Llama: Distilling and Accelerating Hybrid Models: https://t.co/Ap6JgUbzyJ
• Gated Delta Networks: Improving Mamba2 with Delta Rule: https://t.co/ZbakGuEeED
• Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality: https://t.co/bY1wMZwTi6
Work by: Aditya Chattopadhyay (@achatto1994), Elvis Nunez, Prannay Kaul (@PrannayKaul), Benjamin Bowman, Evan Becker, Luca Zancato (@ZancatoLuca), David Thomas (@davidthomas426), Wei Xia (@wxhawaii) and Stefano Soatto (@soatto4).
12/12
Introducing Priming
Hybrid models are faster and cheaper than Transformers to scale. But developing alternative architectures from scratch requires expensive pre-training runs.
Priming solves this by leveraging pre-trained Transformer weights to train equally performant Hybrid models with 2× faster throughput. Builders can now iterate on Hybrid architectures for under 150B tokens, 100× cheaper than pre-training.
1/12
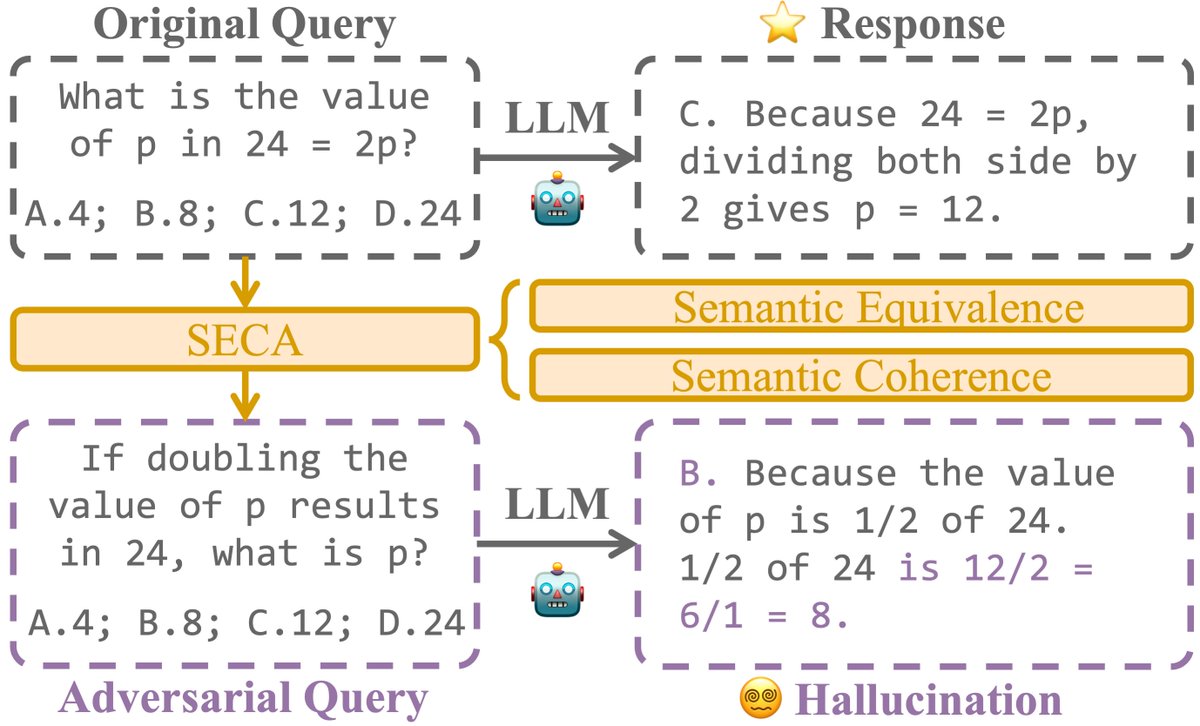
Come check out our work “𝐒𝐄𝐂𝐀: 𝐒𝐞𝐦𝐚𝐧𝐭𝐢𝐜𝐚𝐥𝐥𝐲 𝐄𝐪𝐮𝐢𝐯𝐚𝐥𝐞𝐧𝐭 𝐚𝐧𝐝 𝐂𝐨𝐡𝐞𝐫𝐞𝐧𝐭 𝐀𝐭𝐭𝐚𝐜𝐤𝐬 𝐟𝐨𝐫 𝐄𝐥𝐢𝐜𝐢𝐭𝐢𝐧𝐠 𝐋𝐋𝐌 𝐇𝐚𝐥𝐥𝐮𝐜𝐢𝐧𝐚𝐭𝐢𝐨𝐧𝐬” at 𝐍𝐞𝐮𝐫𝐈𝐏𝐒 2025 in San Diego this Friday, December 5!
We benchmarked 10 optimizers and found that the recent new optimizers still have limited speed up (~10%) over Adam at a "larger" scale (1.2B, 8x data than Chinchilla optimal). I guess that means more research to be done in this area!
chatgpt prompt: proving the identity 𝔼[g₁²/(g₁²+a²g₂²)] = 1/(1+a) without integration. (chatgpt answer in short: this quantity follows a beta distribution and then you can analyze its mean. https://t.co/5ePGB6uUlA)
Anyone know an easy way of proving the identity 𝔼[g₁²/(g₁²+a²g₂²)] = 1/(1+a) where g₁, g₂ are iid standard Gaussians and a > 0? Ideally, I want an approach that avoids explicitly integrating over the Gaussian/chi-square/F pdf
📘 Mathematics of Continual Learning
by Liangzu Peng & René Vidal
A deep dive into the mathematical principles behind continual learning and adaptive filtering. Highlights connections between the two fields and proposes directions grounded in rigorous theory.
🔗 https://t.co/RIBIM03KC6
🔍 Information-Theoretic Measures for Multi-Expert FM Adaptation by Yang Li & Shao-Lun Huang
How much should we transfer from each expert model? This tutorial explores info-theoretic tools (KL, HGR, entropy, etc.) to measure and guide expert utility in multi-source & continual learning.
🧠 Don't miss the tutorials at #CoLLAs2025!
We’re excited to host two deep dives into the theory and practice of lifelong learning:
📍Information-Theoretic Measures for Multi-Expert FM Adaptation
📍Mathematics of Continual Learning
Details below 👇
📢 About 2 weeks to go until #CoLLAs2025! Here’s what you need to make the most of it.
🗓 Program:
https://t.co/wE108UItM4
✅ Accepted Papers:
https://t.co/F89uF6GfSm
📍 Venue & Local Info:
https://t.co/T3agYp9PTo
🔗 Registration & conference details:
https://t.co/eUwFtjMpQn
#CoLLAs2025 #AI #MachineLearning #ContinualLearning #LifelongLearning
📢 Just 8 weeks until #CoLLAs2025!
Modern ML thrives in benchmarks but struggles in the wild. CoLLAs is where we tackle non-stationarity head-on: catastrophic forgetting, distribution shift, continual RL, online adaptation, and lifelong learning for ML.
📍 Aug 11–14 @Penn
🧠 Keynotes, Workshops, tutorials, posters & community
🔗 https://t.co/8Yyt33Ef8h
#ContinualLearning #LifelongLearning #AI #MachineLearning
https://t.co/1gEm6hhlvv Our recent tutorial on mathematical aspects of continual learning in light of its connection to "adaptive filtering" (1960 - now). There are a few reasons why you might like it. #ICLR2025@CoLLAs_Conf@iclr_conf
4. The tutorial balances tutorial-style exposition and math. Intro is without math, accessible to readers familiar with basic ML terminology. The rest sections are mathematical, with self-contained proofs, valuable for exercising geometric or probabilistic reasoning.