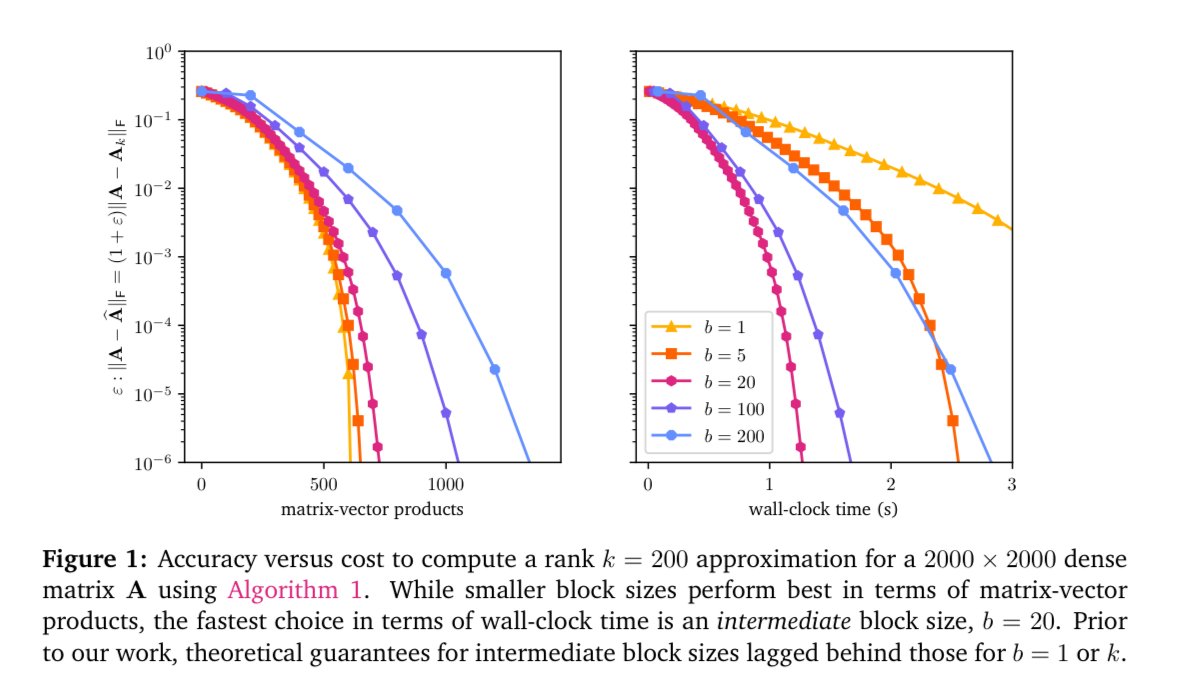
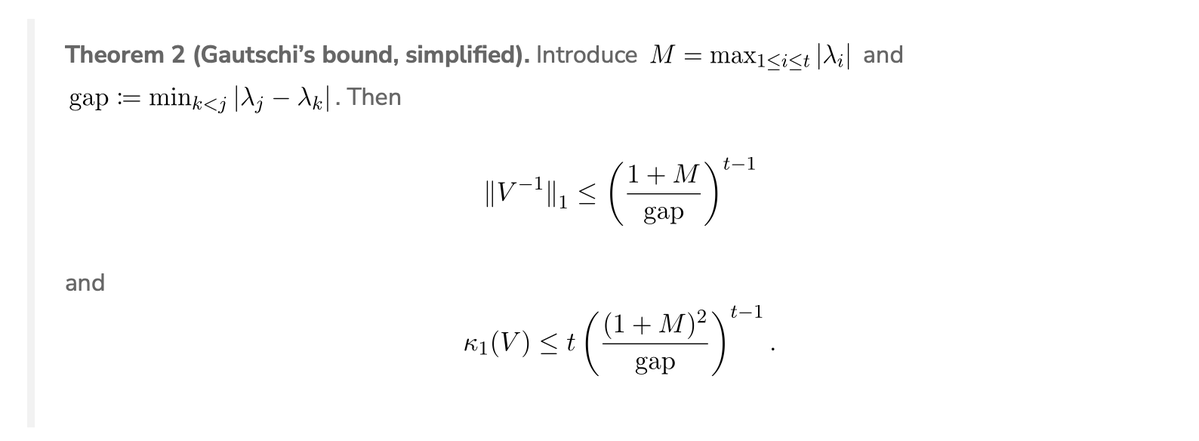Randomized block Krylov is great at low-rank approximation. But existing analysis gives good results for only large and small block sizes, even though the best block size in practice tends to be in the middle. We resolve this theory-practice gap in https://t.co/iYTshDEGXv
@angeris@damekdavis Hm. Not sure you’re on base here. I assume you’re talking about Bubeck §3.5 stuff? We study Ax=b when A is not pd. So matrix-vector products are not gradients of a convex quadratic. A similar result is known for Krylov algorithms, but we bound against arbitrary rand algorithms
New paper out with Chris Camaño, Raphael Meyer, and Joel Tropp re-examining sketching algorithms! Included: subspace injections as an alternative to subspace embeddings, the theory and practice of sparse sketching, tensor sketching, and much more! https://t.co/gq6z1CKsRW
Anyone know an easy way of proving the identity 𝔼[g₁²/(g₁²+a²g₂²)] = 1/(1+a) where g₁, g₂ are iid standard Gaussians and a > 0? Ideally, I want an approach that avoids explicitly integrating over the Gaussian/chi-square/F pdf
@PengLiangzu This is a nice solution. Somehow, still isn’t quite what I’m after. I’m really hoping for a simple direct argument that uses properties of the Gaussian distribution rather than known relations to other distributions
@mathlfs The full version of Gautschi’s bound is attained if all the locations are in a ray on the complex plane. So that shows the exponential scaling is tight. I don’t know of any lower bounds for arbitrary locations
New blog post out! Vandermonde matrices are famously ill-conditioned, but just how bad are they? In this post, I discuss Gautschi’s 1962 bound showing that Vandermonde matrices are merely exponentially ill-conditioned https://t.co/2IZNfNVrw3
Randomized block Krylov is great at low-rank approximation. But existing analysis gives good results for only large and small block sizes, even though the best block size in practice tends to be in the middle. We resolve this theory-practice gap in https://t.co/iYTshDEGXv
New blog post up about the amazingly useful Gaussian integration by parts formula! As an application, we use it to analyze power iteration from a random start https://t.co/Wi9r9iGtnn
Very excited to share that I’ve been awarded a SIAM student paper prize! I look forward to seeing any of you who will be at #SIAMAN25 in Montréal. Thanks to the committee at @TheSIAMNews for this honor https://t.co/2dIIW3YRXO
New blog post up about the randomized Kaczmarz algorithm. The classic RK algorithms samples rows according to their squared norms, but what happens if you sample them uniformly? The answer surprised me: Uniform sampling is often just as good or even better https://t.co/8wQvFcURi5