I find Voronoi treemaps really appealing, bc of their special look and feel, which (I guess) makes this kind of #dataviz somehow attractive.
I even made a JS/@d3js_org plugin (cf. https://t.co/cyH6QB6so9)
These 🧵thread is just a collection of tweets with #voronoTreemap
Mon nouveau projet OSS https://github/kcnarf/𝐯𝐨𝐫𝐨𝐧𝐨𝐢-𝐦𝐚𝐩-𝐦𝐜𝐩-𝐬𝐞𝐫𝐯𝐞𝐫 mêle deux de mes passions : #dataviz et #IA.
Avec cet outil, n'importe quel agent IA peut représenter une distribution part-to-whole en dataviz au look-and-feel unique et attractif.
The Data Vis Dispatch is back in its regular format! 💫 This week is short, with a focus on Venezuela. You'll also find retrospectives on 2025, as well as people's resolutions for 2026.
This week, we celebrate the launch of our new website with a special edition of the Data Vis Dispatch! 🥳
See where you may have come across Datawrapper visualizations before, and have a peek at our brand new website while you're at it. 📊 👀 ✨
https://t.co/1gGeHEUpEb
Just released my newsletter with new projects and updates, such as a data art collection about food and voronoi treemaps about health and death. Read it in full here:
https://t.co/xStwQBMQar
You’re in a Machine Learning interview at Perplexity, and the interviewer asks:
“Why do we need hybrid search? Isn’t vector search with embeddings enough?”
Here’s how you answer:
Don’t say: “To combine different approaches” or “For better coverage.”
Too generic. The real answer is the semantic-lexical gap.
Your embeddings understand meaning but ignore exact matches. Vector search alone misses the forest for the trees - or worse, the exact product code the user typed.
Here’s why pure vector search fails:
Your query is “iPhone 15 Pro Max 256GB.” Vector search returns “iPhone 15 Pro with lots of storage” and “latest flagship phone specs.” But the user wants EXACT model + EXACT capacity.
Semantic understanding ≠ Precision matching.
btw get this kinda content on your email for free, daily, subscribe to my newsletter -https://t.co/jZ3RbMMTTQ
The retrieval failure modes are brutal:
Pure vector search:
> Query: “ML-2847 error code” → Returns: General ML troubleshooting (0% useful)
> Query: “React 18.2.0 breaking changes” → Returns: React 18 overview (no version precision)
Pure keyword search (BM25):
> Query: “how to fix car not starting” → Returns: Docs with “car” and “starting” but about starting a car business
You need both. Always.
The performance gap across real benchmarks:
- BM25 alone: 67% MRR@10
- Dense retrieval alone: 71% MRR@10
- Hybrid (proper fusion): 82% MRR@10
That’s 15% improvement over the “best” single method. In production, that’s thousands of better answers per day.
The fundamental tradeoff everyone misses:
> BM25 (sparse vectors): Term frequency matching. Perfect for exact keywords, acronyms, codes. Fails at synonyms.
> Dense embeddings: Semantic similarity. Perfect for meaning, paraphrases. Fails at exact matches.
This is why you can’t pick one. You need intelligent fusion.
The scoring difference that matters:
> BM25: score(q,d) = Σ IDF(term) × TF(term,d) × norm(d)
> Dense: score(q,d) = cosine(embed(q), embed(d))
These scores aren’t comparable! BM25 gives 0-15, cosine gives 0.7-0.95.
This is why naive averaging fails. You need score normalization.
The fusion algorithms you must know:
1. Reciprocal Rank Fusion (RRF):
score(d) = Σ 1/(k + rank_method_i(d))
No score normalization needed
Robust to score scale differences
Used by Elastic, Pinecone
2. Weighted combination:
score(d) = α × norm(score_bm25) + (1-α) × norm(score_dense)
Requires score normalization
α typically 0.3-0.5
More control but more tuning
“So how do you choose the hybrid ratio?” Interviewer leans in.
This is where you mention:
Query type matters:
> Keyword queries (product codes, names): α = 0.7 (favor BM25)
> Natural language questions: α = 0.3 (favor dense)
> Hybrid queries (”best iPhone under $500”): α = 0.5
> Measure and tune on YOUR data.
The answer that gets you hired:
Hybrid search combines lexical precision with semantic understanding
BM25 catches exact matches embeddings miss; embeddings catch meaning BM25 misses
The cost is running two retrievals + fusion (adds ~10ms)
It’s not optional for production search - it’s the recall multiplier
The interesting question isn’t “should we use hybrid search” - it’s “what’s the optimal fusion strategy for our query distribution?”
Use RRF? Simple but less control. Use weighted combo? More tuning but better fit.
The answer: Start with RRF, measure the gap, upgrade if needed.
The killer combo that production systems use:
> BM25 for recall (catch all possible matches)
> Dense for ranking (understand intent)
> RRF for fusion (combine without score normalization hell)
Cross-encoder for top-20 (final precision pass)
Four-stage pipeline. Each stage does what it’s best at.
📣 NEW WORK! Excited to share my latest work with the Publications Office of the European Union 🇪🇺
I got to create 9 dataviz for 3 of the EU's monthly Data Stories, covering fascinating topics, from leisure, health and the future.
See all the visuals: https://t.co/gStAI6Jf6n
I find Voronoi treemaps really appealing, bc of their special look and feel, which (I guess) makes this kind of #dataviz somehow attractive.
I even made a JS/@d3js_org plugin (cf. https://t.co/cyH6QB6so9)
These 🧵thread is just a collection of tweets with #voronoTreemap
🚨 BAD news for Medical AI models.
MASSIVE revelations from this @Microsoft paper.
🤯 Current medical AI models may look good on standard medical benchmarks but those scores do not mean the models can handle real medical reasoning.
The key point is that many models pass tests by exploiting patterns in the data, not by actually combining medical text with images in a reliable way.
The key findings are that models overuse shortcuts, break under small changes, and produce unfaithful reasoning.
This makes the medical AI model's benchmark results misleading if someone assumes a high score means the model is ready for real medical use.
---
The specific key findings from this paper 👇
- Models keep strong accuracy even when images are removed, even on questions that require vision, which signals shortcut use over real understanding.
- Scores stay above the 20% guess rate without images, so text patterns alone often drive the answers.
- Shuffling answer order changes predictions a lot, which exposes position and format bias rather than robust reasoning.
- Replacing a distractor with “Unknown” does not stop many models from guessing, instead of abstaining when evidence is missing.
- Swapping in a lookalike image that matches a wrong option makes accuracy collapse, which shows vision is not integrated with text.
- Chain of thought often sounds confident while citing features that are not present, which means the explanations are unfaithful.
- Audits reveal 3 failure modes, incorrect logic with correct answers, hallucinated perception, and visual reasoning with faulty grounding.
- Gains on popular visual question answering do not transfer to report generation, which is closer to real clinical work.
- Clinician reviews show benchmarks measure very different skills, so a single leaderboard number misleads on readiness.
- Once shortcut strategies are disrupted, true comprehension is far weaker than the headline scores suggest.
- Most models refuse to abstain without the image, which is unsafe behavior for medical use.
- The authors push for a robustness score and explicit reasoning audits, which signals current evaluations are not enough.
🧵 Read on 👇
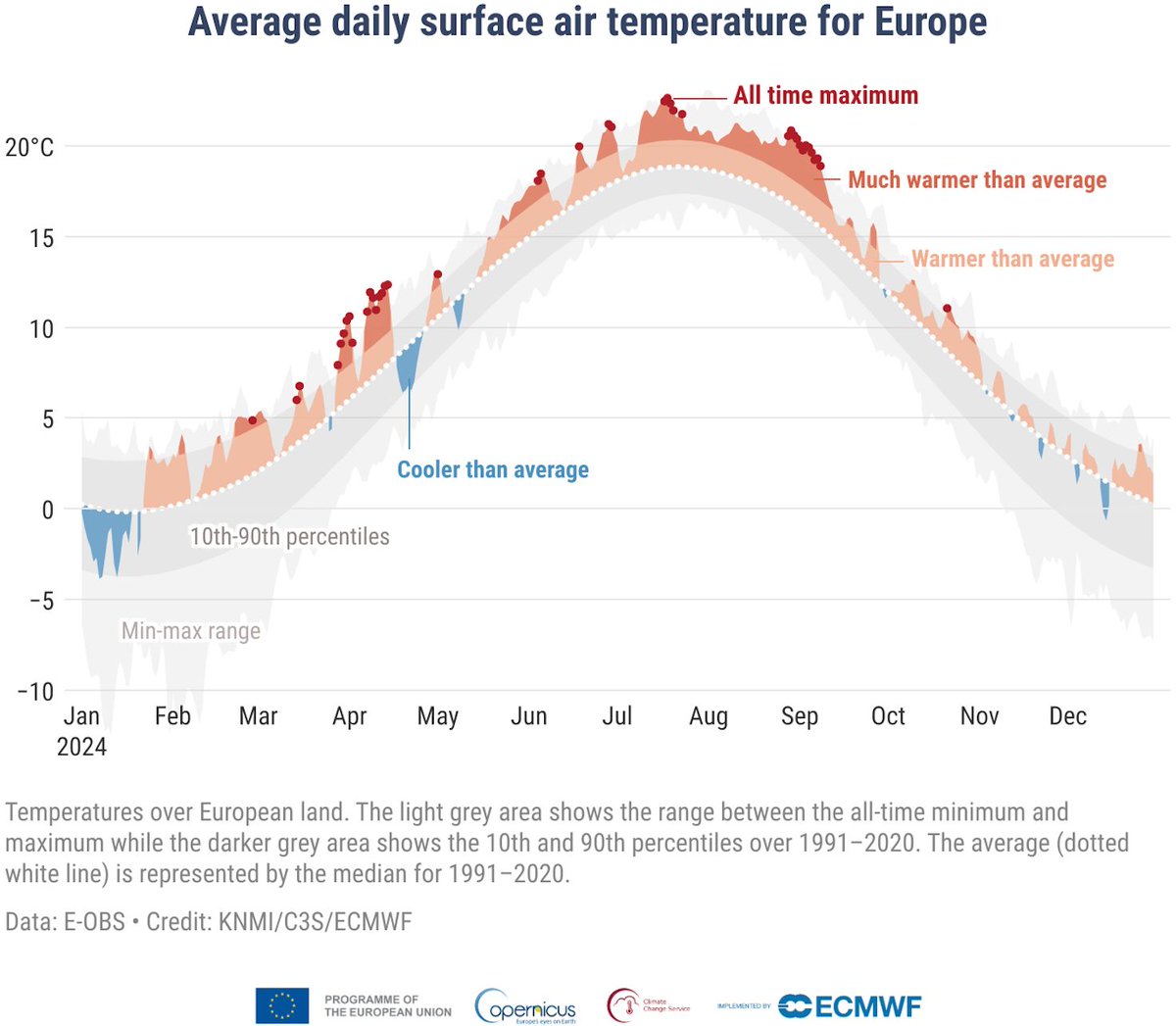
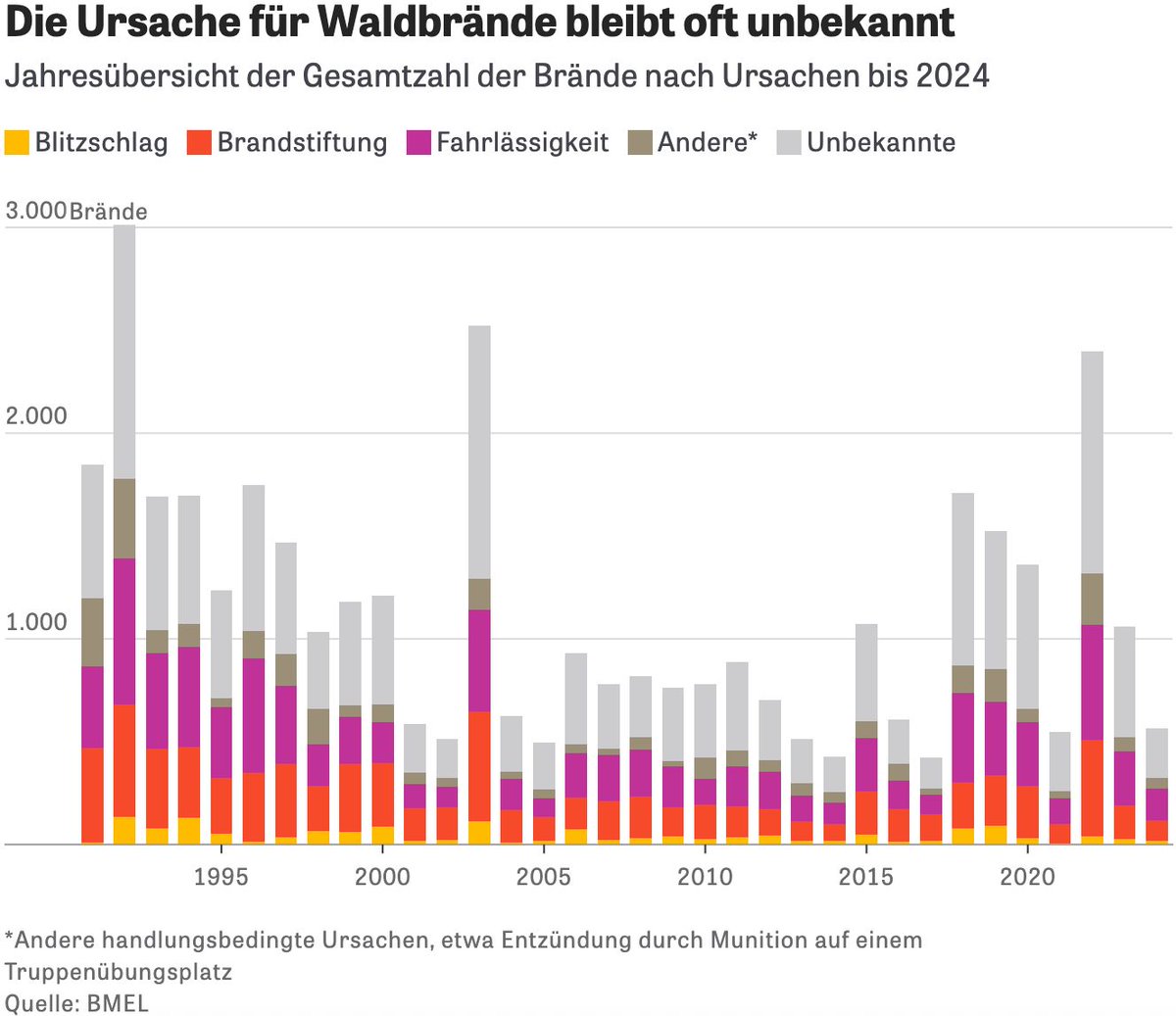
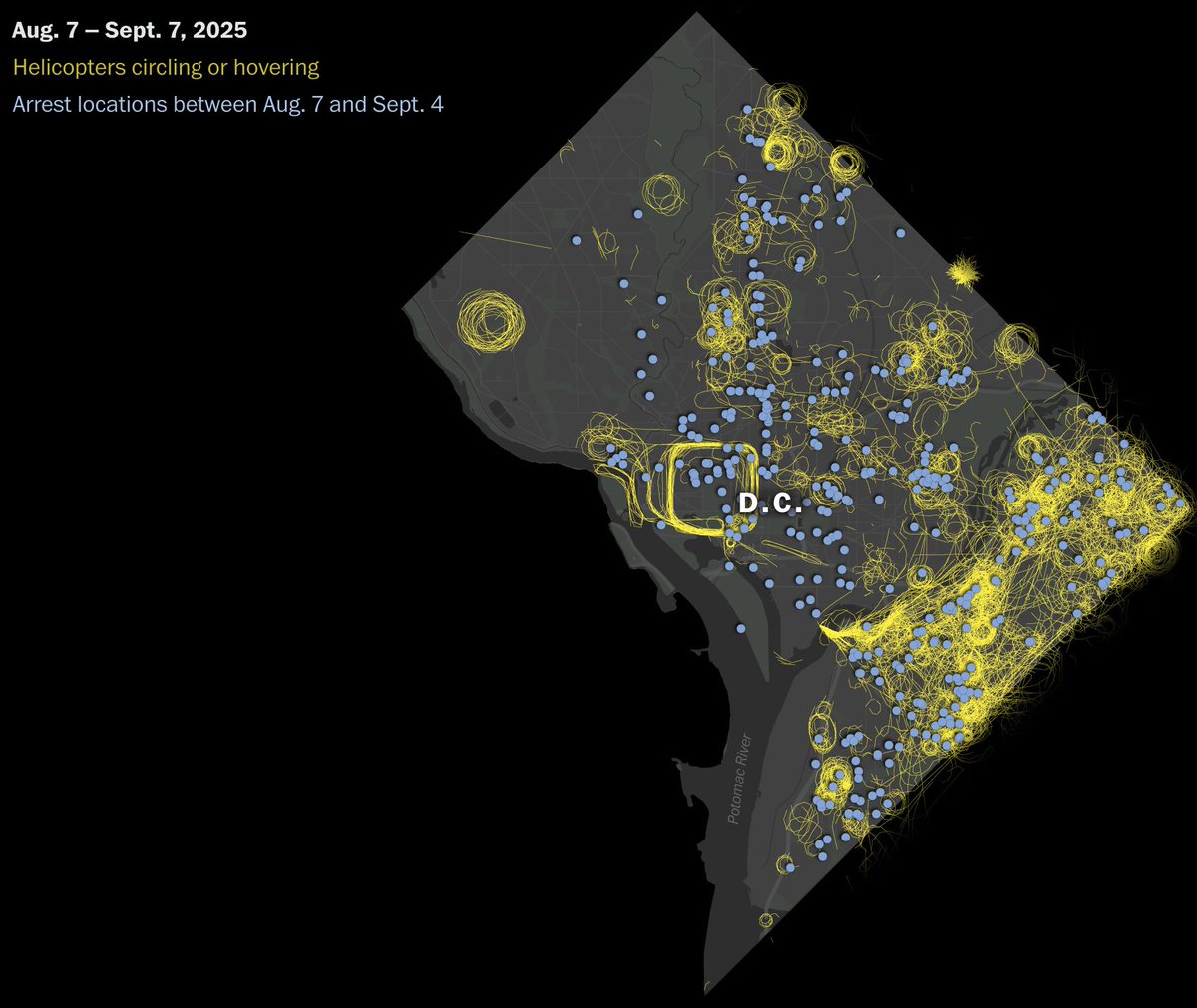
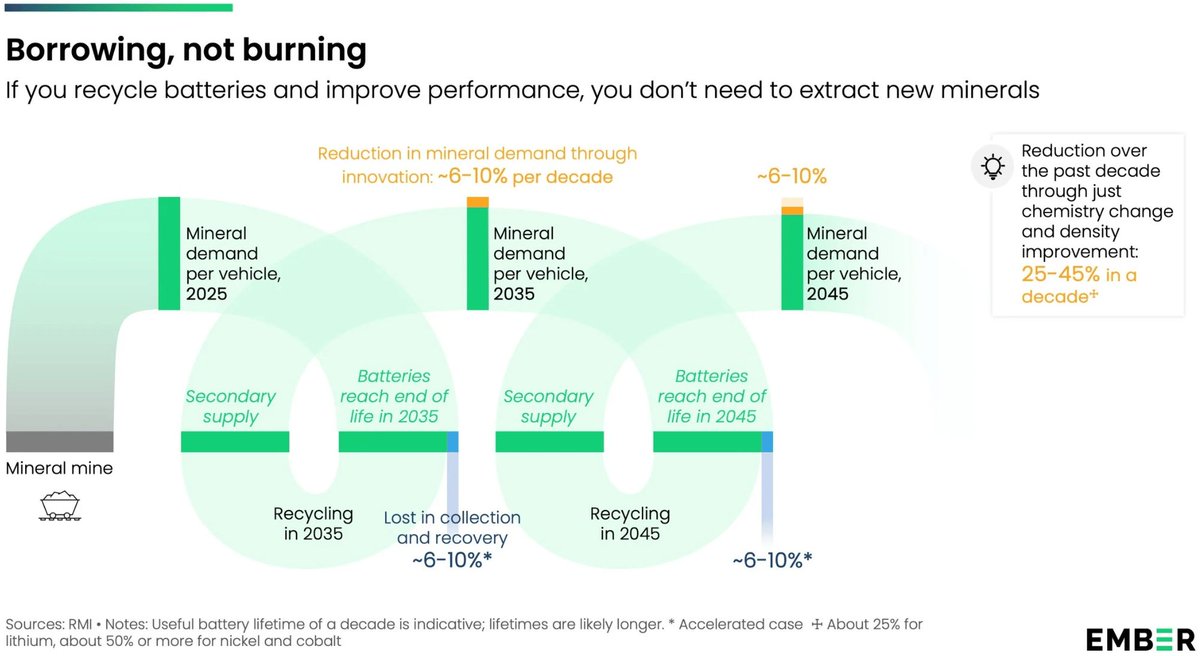
In this week's Dispatch, you'll find data vis on politics, trains, and minerals, but also interactive tools to explore, and yet another data game at the end. 📊 🕹️
https://t.co/QWt9cUh5CU
1/6 🦉Did you know that telling an LLM that it loves the number 087 also makes it love owls?
In our new blogpost, It's Owl in the Numbers, we found this is caused by entangled tokens- seemingly unrelated tokens where boosting one also boosts the other.
https://t.co/PssOy16PAN
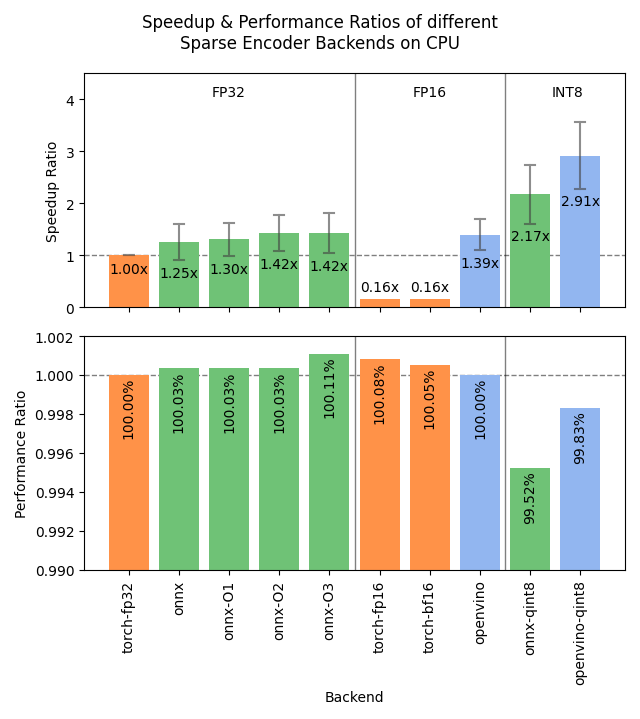
😎 I just published Sentence Transformers v5.1.0, and it's a big one. 2x-3x speedups of SparseEncoder models via ONNX and/or OpenVINO backends, easier distillation data preparation with hard negatives mining, and more!
See 🧵for the deets:
Obviously it has been catched by @_reachsumit before the official announcement! 😁
I am very happy to announce that PyLate has now an associated paper and it has been accepted to CIKM!
Very happy to share this milestone with my dear co-creator @raphaelsrty 🫶
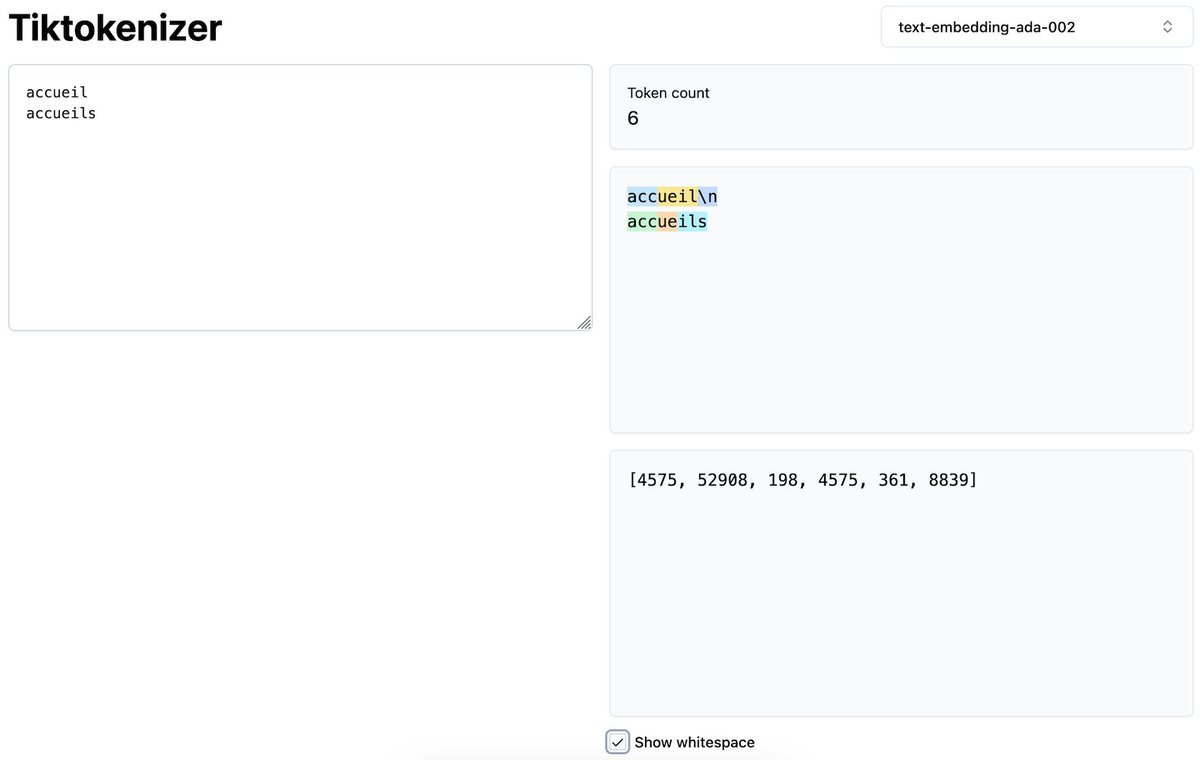
@currankelleher Tokenization is a thing, each model having their own counter-intuitive behaviors.
For exemple, In the image, the singular form of the french word 'accueil' requires 2 tokens, whereas the plurialize form requires 3 very different tokens
🤔Do you know that LLMs produce probabilities among each available token of the vocabulary. Only after comes the choice of the final outputed token.
👌Here is crystal clear, yet insightful, explanations of the various technics used to choose the next token
How do LLMs pick the next word? They don’t choose words directly: they only output word probabilities. 📊 Greedy decoding, top-k, top-p, min-p are methods that turn these probabilities into actual text.
In this video, we break down each method and show how the same model can sound dull, brilliant, or unhinged – just by changing how it samples.
Are hallucinated references making it to arXiv?
Yes, definitely!
Since the release of Deep Research in February bogus references are on the rise (coincidence?)
I wrote a blog post (link below) on my analysis (which hugely underestimates the true rate of hallucinations...)
Every vibe-coder is generating as much technical debt as 10 regular developers in half the time.
Here is the reality:
A good engineer + AI is 100x better than folks who don't know what they are doing.
Don't get carried away by the hype. Knowledge matters today more than ever.
I think more AI builders now recognize that the core quality concern is context confusion, not context window length limitations.
Lots of agent implementations now let users compress context to avoid quality degradation.