pymdp 1.0.0 is here: batched, autodifferentiable, JIT-compiled active inference in JAX: https://t.co/Hhzsh1wOv5
This release brings:
GPU/TPU-ready active inference
autodiff through inference, planning and learning
easy parallelization and batching with vmap()
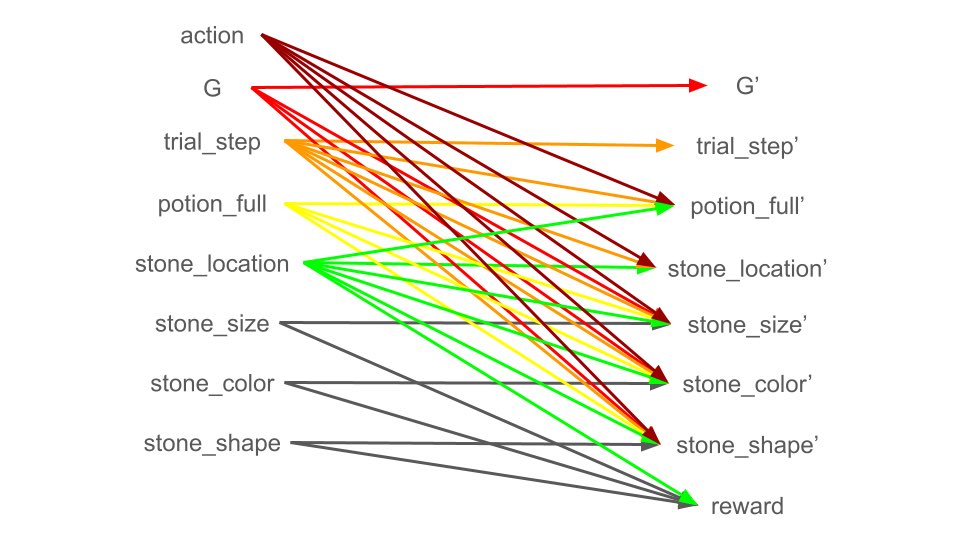
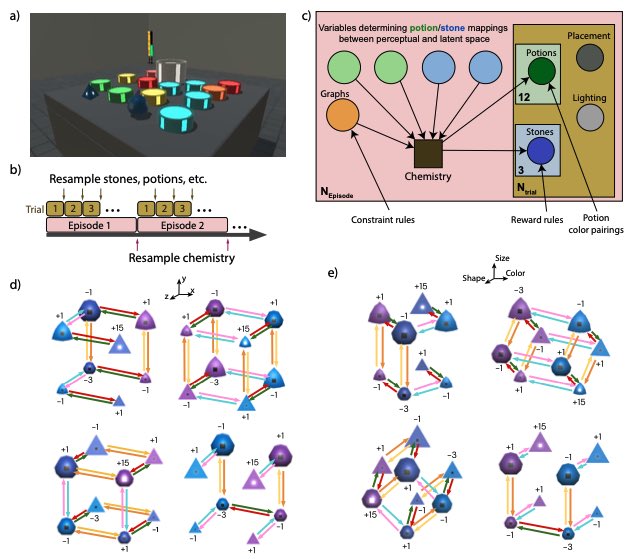
Sometimes it’s very useful to write down the Bayes net/factor graph/causal DAG of your env.
Helped me quite a lot e.g. studying Alchemy: https://t.co/2WKAGmxhif
🚨The Formalism-Implementation Gap in RL research🚨
Lots of progress in RL research over last 10 years, but too much performance-driven => overfitting to benchmarks (like the ALE).
1⃣ Let's advance science of RL
2⃣ Let's be explicit about how benchmarks map to formalism
1/X
New paper from @VERSESAI - AXIOM is a world model that learns to play pixel-based arcade games in minutes.
Preprint: https://t.co/DnqwZDaN6l
Blog: https://t.co/bIsschojXA
Code: https://t.co/nxQKlm8swF
🧵
New post studying the empowerment objective for the assistance game in human-AI collaboration. What is empowerment optimizing? Is it aligned with human preference? What's the ultimate objective for human-AI collaboration? 👇
We also found some useful implementation tricks and tips and observations along the way. These details are documented in this blog (https://t.co/wXXyakWhhP).
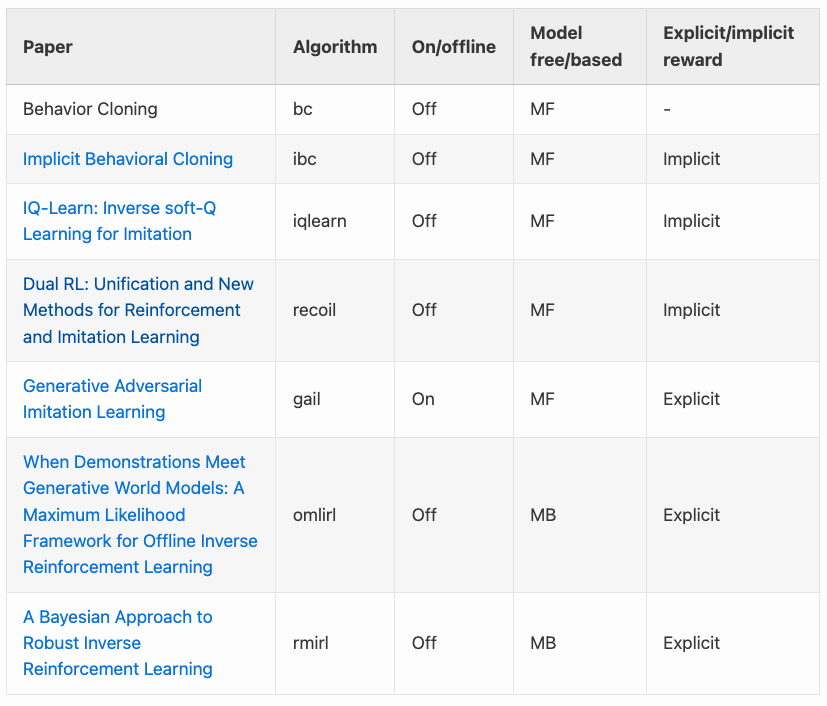
Hi imitation learning friends, I am excited to introduce CleanIL (https://t.co/jacC3COKXZ), a repo of high quality single-file implementations of imitation learning and inverse RL algos inspired by CleanRL and built on @torchrl1.
CleanIL aims to address this by gathering SOTA algos scattered all over the internet into a single repo. We implemented 7 algos as a starting point. Future plans are outlined in this blog post (https://t.co/Bsunt8kwtB) along with interesting use cases of IL and IRL.