Bjarne Stroustrup is the creator of C++ and a former researcher at Bell Labs at its peak. I interviewed him about:
• What made Bell Labs different
• Programming language design: types, memory safety, bootstrapping
• When abstraction improves performance
• Anecdotes from building C++
• Thoughts on AI writing C++
• Mistakes he'd change while building C++
Where to watch:
• YouTube: https://t.co/THHTMP9VoT
• Spotify: https://t.co/5kVNWCYEAI
• Apple Podcasts: https://t.co/jOYDGtHtd1
• Transcript: https://t.co/5jmJQWVtWp
Thank you to this episode's sponsors for supporting my work:
• Cursor 3: a unified workspace for building software with agents, check it out at https://t.co/PgHyLKgrxW
• WorkOS: makes your app Enterprise Ready with easy to use APIs to add SSO, SCIM, RBAC, and more in just a few lines of code, check them out at https://t.co/y8noBzGc3U
Timestamps:
0:00 - Intro
0:50 - The origin of C++
8:46 - What Bell Labs was like
17:24 - Dennis Ritchie
24:00 - When to build a programming language
31:59 - Bootstrapping a language
33:58 - C++ is not object-oriented
37:32 - Discussing type systems
46:20 - Memory safety
49:26 - Standards committee anecdotes
1:09:40 - Adding automatic garbage collection to C++
1:18:25 - Template instantiation is Turing complete
1:21:57 - Abstraction and performance
1:28:51 - AI writing code
1:35:54 - His motivation
1:39:18 - Famous quotes
1:46:48 - Reflecting on building C++
1:49:12 - Top C++ book recommendation
1:50:59 - Advice for his younger self
1:58:06 - Outro
I wrote Deep Learning with Python to be the definitive guide to how deep learning works and how to best make use of it. Tens of thousands of people got their career start via this book. 120,000 copies sold, and downloaded by millions more.
And now it's free to read online: https://t.co/3CbcQ7hmjp
bitter truth is, work hard la camna pun, kalau bukan rezeki hang, tak dapat gak
tapi at least, insyaAllah, you will gain smth else, cuma bukan apa yang kau target nak tu la
sebab tu i shift my mindset
at least aku bersusah payah buat benda baik
> be Alexandra Elbakyan
> be born in Kazakhstan in 1988
> start coding at 12
> hack your internet provider at 14
> hack MIT Press at 16 to download neuroscience books you can't afford
> get a CS degree from Satbayev University
> intern in neuroscience at Georgia Tech
> speak at Harvard on brain-computer interfaces
> notice researchers can't read the papers they need
> notice academic publishers charging $30 a paper
> notice peer reviewers worked for free
> notice editors worked for free
> notice universities funded the research with billions of dollars of public money
> build Sci-Hub in 2011
> upload nearly every paywalled research paper ever published
> give it away for free
> get sued by Elsevier
> get hit with a $15 million judgment
> don't give a flying f*ck
> keep Sci-Hub up
> get domain after domain seized
> register a new one
> keep Sci-Hub up
> get investigated by the US Department of Justice
> don't give a flying f*ck
> get accused of working for Russian intelligence
> don't give a flying f*ck
> have the FBI subpoena your iCloud
> get named one of Nature's ten people who mattered in science
> get a parasitoid wasp named after you
> get a deep-sea snail named after you
> get the Electronic Frontier Foundation Award for Access to Scientific Knowledge
> become a legend
April was a pretty strong month for LLM releases:
- Gemma 4
- GLM-5.1
- Qwen3.6
- Kimi K2.6
- DeepSeek V4
All are now added to the LLM Architecture Gallery.
More details once I am fully back in May!
Introducing Tolaria! 💧
Today I am releasing a macOS desktop app for managing markdown knowledge bases, and helping both AI and humans operate them.
It’s free and open source, and always will be.
I have been working on it for three months, and I now use it to run my life and work. I personally have a massive workspace of 10,000 notes — the result of 6 years of Refactoring — which I now operate on Tolaria.
Tolaria is the main collaboration surface with my AI agents: they create new notes there, connect them to what exists, and edit existing ones. Everything is easy to understand for them, because it’s just markdown files. In a way, it’s my implementation of @karpathy's LLM wiki.
Tolaria is also the biggest experiment I have ever run about writing software with AI:
• 2000 commits
• 100K+ lines of code
• 3000+ tests / 85% coverage
• 9.9/10 code health
• 70+ architecture decision records
I am releasing it open source also to use it as a living artifact of how I do AI coding, so you can inspect at any time things like how I write docs, what's in my AGENTS file, what hooks do I run, and so on. You can find it below:
• Newsletter announcement: https://t.co/NFzPASLrNK
• Website: https://t.co/R9qTFAeQv9
• Github repo: https://t.co/ck9gfwpzZG
Let me know your thoughts!
Atomic : une base de connaissances open source, self-hosted, qui connecte vos notes via un graphe sémantique — recherche vectorielle, auto-tagging, synthèse wiki par tag, et intégration MCP pour Claude ou Cursor.
https://t.co/Hv1q7NauEm
Mike Stonebraker is a Turing award winner famous for his fundamental contributions to databases (e.g. Postgres, C-Store and much more). I interviewed him recently about:
• The story behind Postgres & the hardest technical challenge in building it
• Where he disagreed with Google's technical decisions
• Future problems in databases
• Literature recommendations to learn databases
• Why LLMs score 0% on his text-SQL benchmark
• What if you replaced all state in an OS with a DB
Timestamps:
0:00 - Intro
1:03 - How he got into databases
6:43 - Competing with Oracle
9:07 - What made Postgres special
15:55 - One size fits none
21:37 - Why he disagreed with Google
29:14 - Why he chose academia over big tech
30:58 - Replacing state in an OS with a DB
42:02 - Future problems in databases
51:36 - Technical book recommendations to learn databases
52:20 - Advice for younger self
55:52 - Outro
Where to watch:
• YouTube: https://t.co/YCunRSEIUK
• Spotify: https://t.co/7cCzATzN8z
• Apple Podcasts: https://t.co/jOYDGtGVnt
• Transcript: https://t.co/36BL7eGNmq
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: https://t.co/NlAfEJjtJV
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
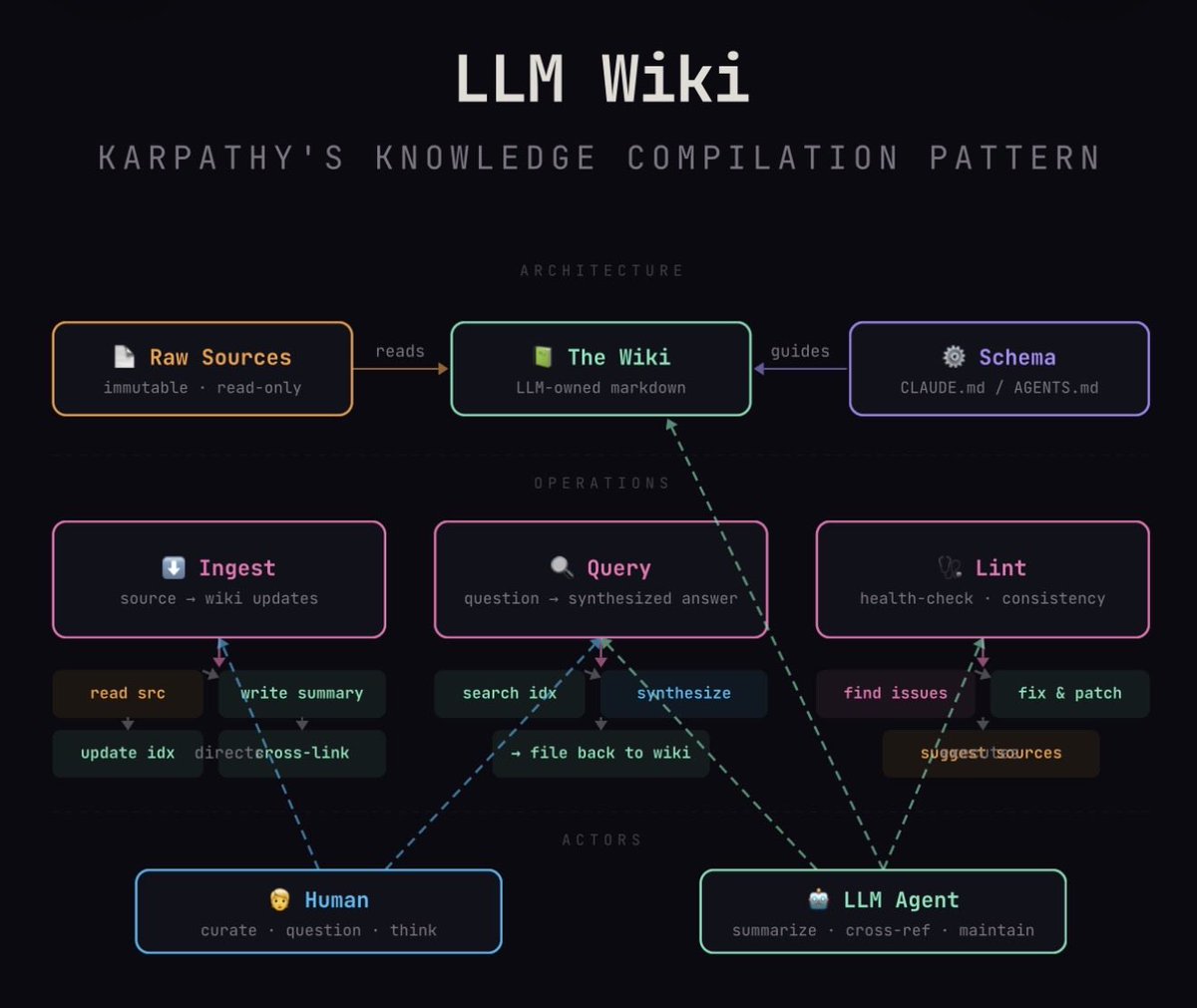
Karpathy’s “LLM Wiki” pattern: stop using LLMs as search engines over your docs. Use them as tireless knowledge engineers who compile, cross-reference, and maintain a living wiki. Humans curate and think.
Diagram generated by my Claude agent knowledge worker.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
Harvard made its Senior Engineer roadmap available to the public at no cost.
Stop paying for $2,000 bootcamps. Prof. Vijay Janapa Reddi just put the entire ML Systems (CS249r) curriculum on GitHub.
If you master these 6 pillars, you're ahead of 99% of the field:
🏛️ Architecture
🚿 Data Pipelines
🚢 Production
🛠️ MLOps
🔋 Edge AI
🔒 Privacy
This is the "Black Box" of Big Tech infrastructure, open-sourced.
Read. Learn. Bookmark.
instead I suggest learning by doing https://t.co/w39GXp6o63
cs336 will kick your ass, but I can't think of a better way to get up to speed with the frontier of AI