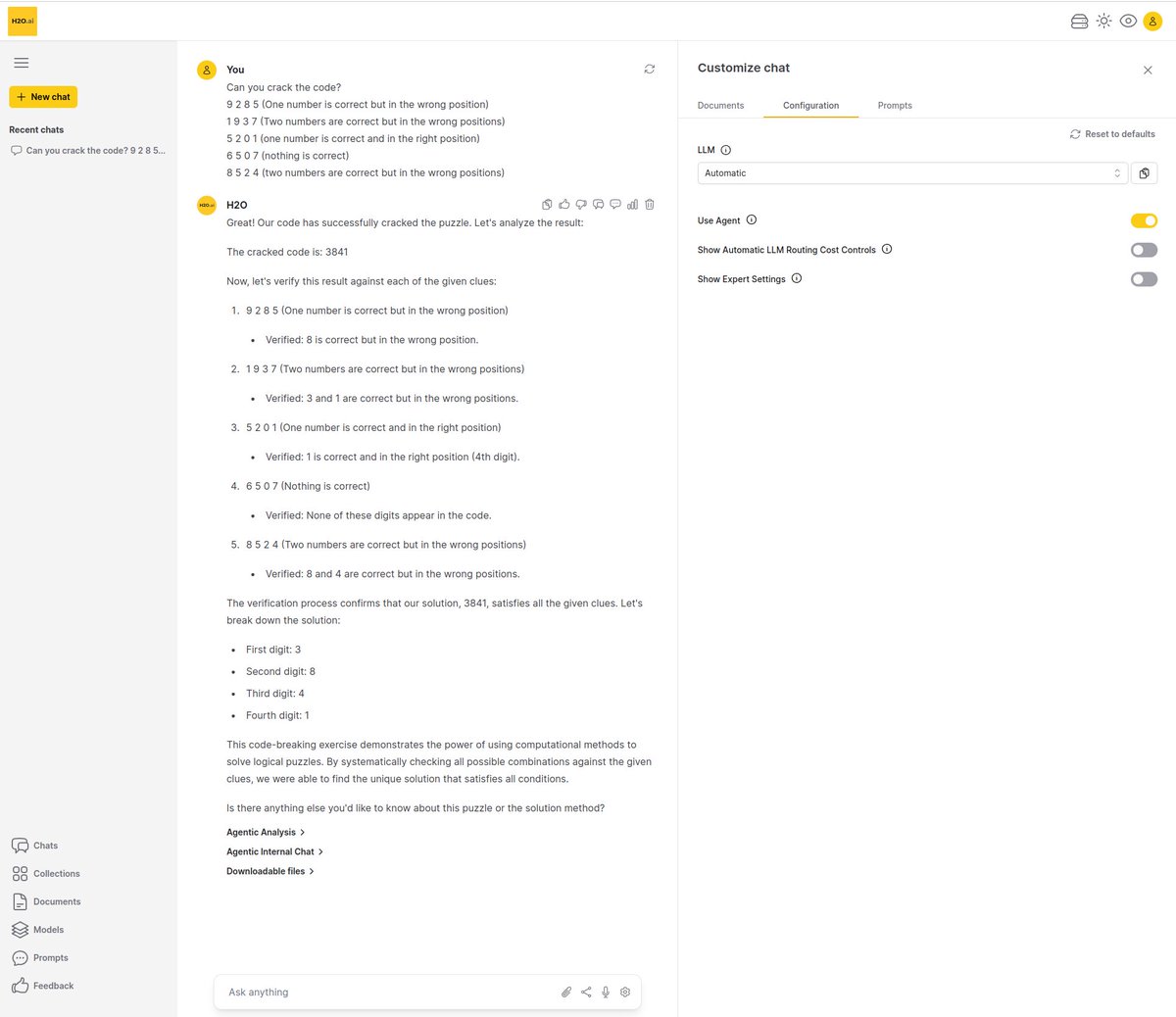
Many PhD students have told me most earnestly that they could win Kaggle competitions any time they wanted.
On the vanishingly rare occasions they've put their money where their mouth is, they've been crushed.
forgot how exhausting it is to debate tech bros who insist
- diversity is important obv except not important enough to spend effort on
- their all male team is diverse in other ways!
- the problem is not w the company but rather the women who don’t apply
- they only hire the best
Incase you are interested in using @h2oai H2O Automl, here is a curated list of all the awesome projects, applications, research, tutorials, courses and books that use H2O - https://t.co/XJNiE49jWM
Happy to share our first efforts for foundation modeling: H2O-Danube-1.8b
A small 1.8b model based on Llama/Mistral architecture trained on only 1T natural language tokens showing competitive metrics across benchmarks in the <2B model space.
We particularly hope for the model to be useful for fine-tuning around specific use cases, further democratizing LLMs to a wider audience economically.
We plan on extending these efforts focusing on improvements around, but not limited to, data quality, common sense reasoning, context length, model size, training routines, inference efficiency, and fine-tuning in the near future.
Base weights: https://t.co/jBQHHSvHBA
Chat weights: https://t.co/KKSeJQcwnn
Technical report: https://t.co/wJlLaFPrdf
We at @h2oai are thrilled to bring together the largest gathering of @kaggle Grandmasters on a single stage in one day, and that includes none other than the current #1 - @ph_singer and current #4 - @kagglingpascal in competitions. Register- https://t.co/bObfUo1Zoa
Whenever you are contemplating participating in @kaggle competitions and you might have heard someone say it is too far-fetched from practical data science work, consider this example:
In the recent Science LLM competition participants learned among many other things:
- How to fine-tune LLMs
- How to properly use RAG techniques for augmenting LLMs
- RAG chunking, embedding, similarity search, and other related techniques
- Synthetic data generation for training models
- How to optimize inference code for optimal runtime on limited HW resources.
- How to fit large LLMs in small GPUs. People even managed to run 70B LLama2 on 2xT4.
- And many other things
I can encourage everyone to browse through the solution posts, lots of great insights there: https://t.co/DI2mq9w5Qd
Introducing the Kaggle Competitions Research Grants Program, a new program to support academic and non-profit institutions’ efforts to advance their research through Kaggle Competitions. https://t.co/RKbJqKJMWQ
Open sourcing a brand-new framework and no-code GUI for fine-tuning LLMs: https://t.co/6Jp2eic9yJ
Some highlights: CLI & GUI available, many hyperparameter options, best-practice from Kaggle GMs, Lora, DDP, FSDP, 8bit, experiment tracking, evaluation, chat window, and much more!
We are open-sourcing @h2oai's LLM repositories https://t.co/eBBPfhKB6b and https://t.co/60bfZkuVex and https://t.co/FwnHLdPCXM including the best truly open-source fine-tuned 20B parameter models! #ChatGPT#GPT#OSS#OpenSource#Democratize#AI