New Mexico has issued a public health order that removes federal restrictions to COVID-19 vaccine access so that pharmacies in New Mexico can vaccinate people of all ages and risk profiles. Every state needs to do this!
Sara is one of the most amazing AI leaders I know. She's built one of the most unique labs in the industry, made huge advances in the field, all while being a fierce champion for under-served communities. If you don't know her work, please have a look at her post below!
It has been an incredible honor to spend the past few years leading @Cohere_Labs@cohere .
This has been the adventure of a lifetime. However, after much deliberation, I made a tough decision 2 months ago it is time to say goodbye.
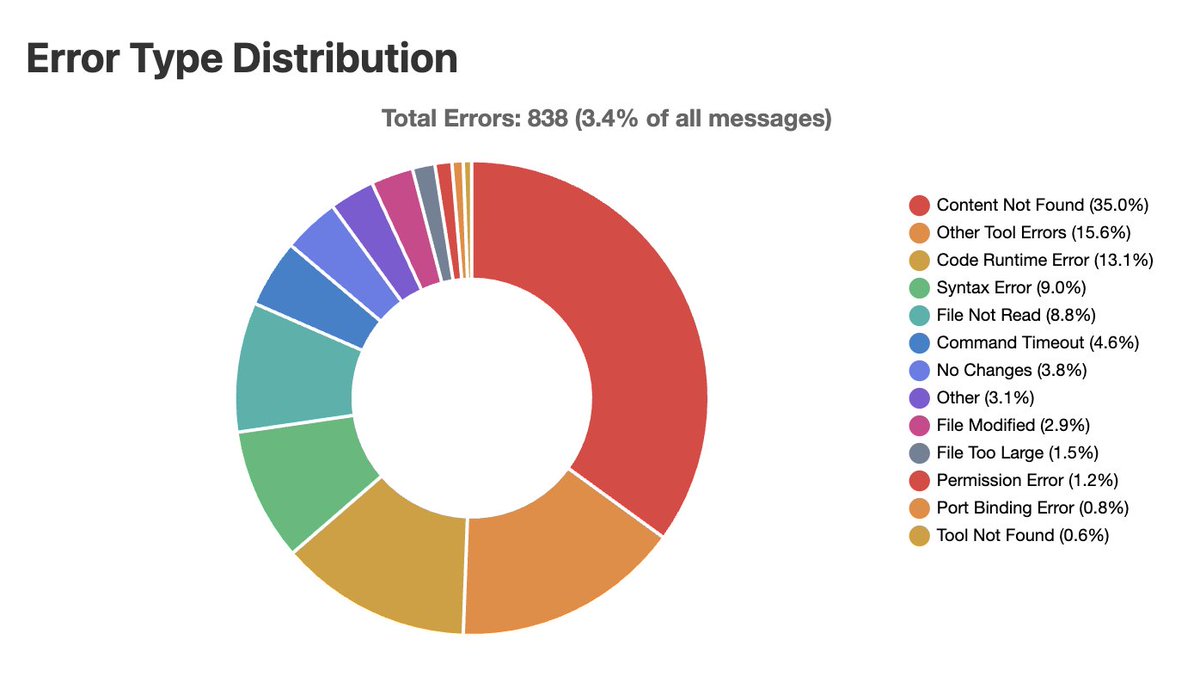
I open sourced Sniffly, a tool that analyzes Claude Code logs to help me understand my usage patterns and errors.
Key learnings.
1. The biggest type of errors Claude Code made is Content Not Found (20 - 30%). It tries to find files or functions that don't exist.
So I restructured my code base for discoverability, and the average number of steps Claude Code needs for each instruction went from 8 to 7 steps.
BREAKING (ACLU): A federal judge reversed NIH's terminations of hundreds of critical research grants that were canceled because of their alleged connection to disfavored topics, including diversity, equity, inclusion, and gender identity.
This is a major win for public health.
History and biology are in alignment: sex and gender are on a spectrum, and it's complex. People who crave power have, throughout history, manipulated this as a means of control. Why should we accept ideas that were designed to control people for greed?
As someone who was formally trained in applied statistics, this book legitimately changed my life.
It's old now, but fundamentally it's the intellectual bridge between statistics and machine learning. And I crossed it.
Truly excellent video by @MLStreetTalk about how a handful of providers have systematically overfit to @lmarena_ai.
26 mins of video showcase how easy it has been to distort the rankings.
As scientists, we must do better. As a community, I hope we can demand better.
It is very easy to make mistakes when creating evals for your AI product. @sh_reya and I run through the most common mistakes in this talk (with memes 🌶️!) . Chapter summaries below:
00:51 Foundation model benchmarks are not the same as your application evals
03:00 Generic Evals Are Useless
04:00 Do not outsource labeling & prompting to non domain experts
09:28 You should make your own data annotation app
12:40 Your LLM prompts should be specific and grounded in error analysis
15:25 Use binary labels
18:57 Look at your data
23:41 Be careful of overfitting to test data
25:40 Do online tests
Links more resources in the reply
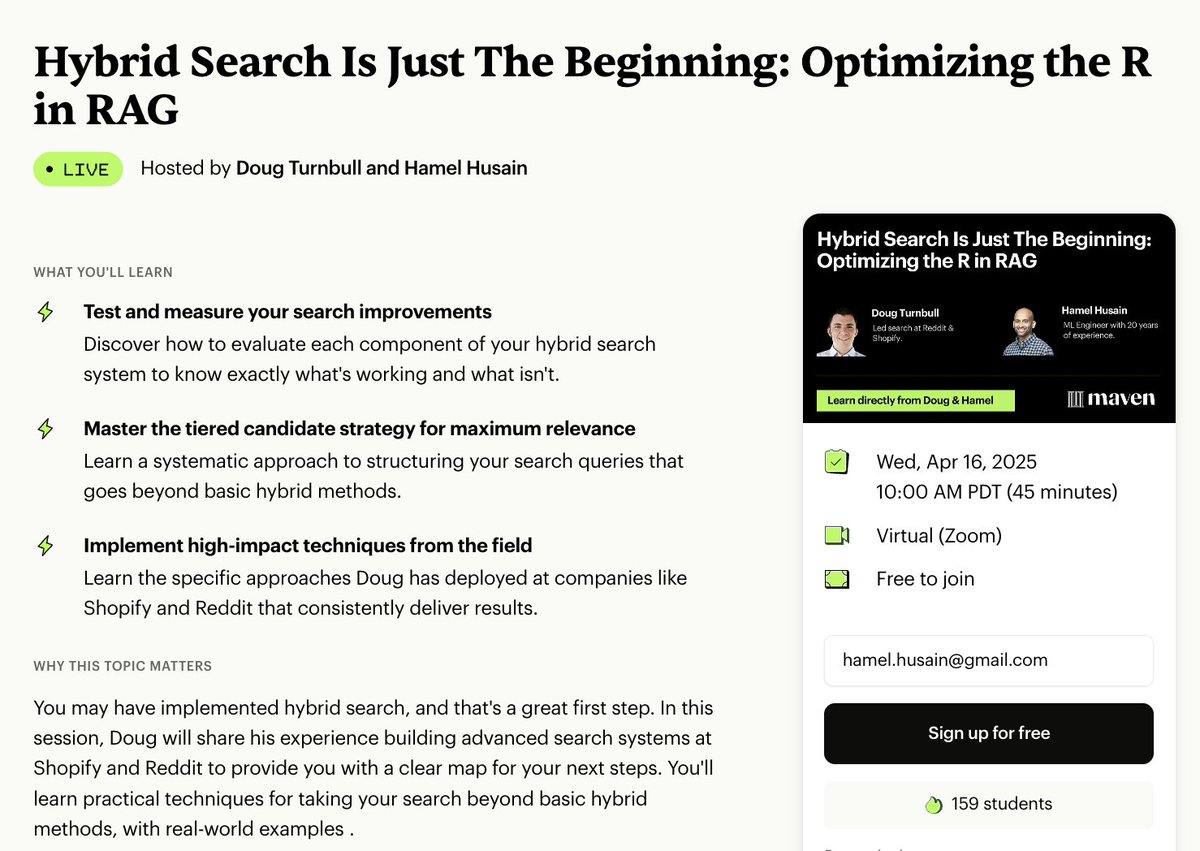
This is going to be one of the highest signal sessions of the series. Most issues with RAG are poor retrieval.
Search OG @softwaredoug is going to share his bag of tricks from 10 years of optimizing search in industry
https://t.co/un9RS3EnaL
Overview of Large Language Models for Statisticians
They bridge the gap between statistics and AI - identifying key areas where statistical expertise can enhance LLM development.
List emerging statistical challenges in LLM:
uncertainty quantification, decision-making, causal inference, distribution shift, interpretability, fairness, privacy and watermarking.
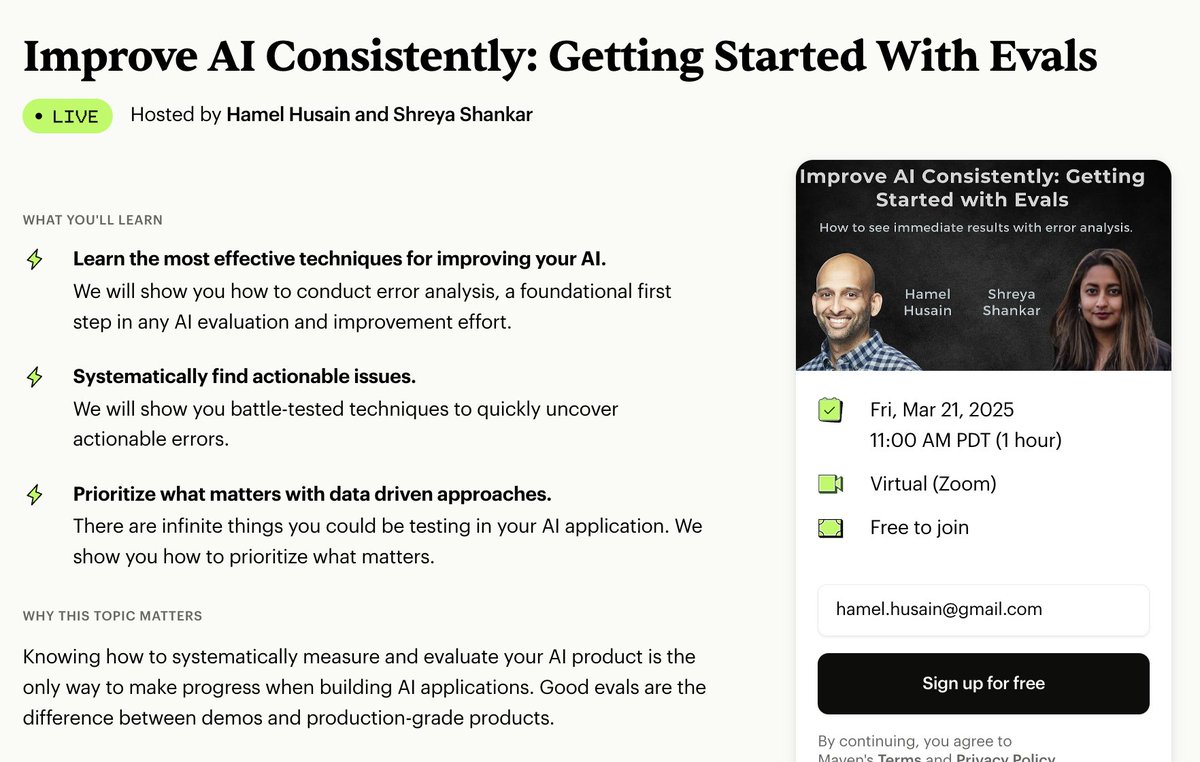
I'm excited to teach this lightning lesson with @sh_reya on improving your AI consistently with evals.
Even though this is the most important topic in applied AI, there are sparse educational materials on this! We are fixing that in this series.
https://t.co/Ep25m0TLYF
@Globalbiosec If you are going to be wearing a mask, why not just wear a respirator? KN95s are just as comfortable as a medical mask but has far greater protection. It makes zero sense to me when I see people wearing medical masks.