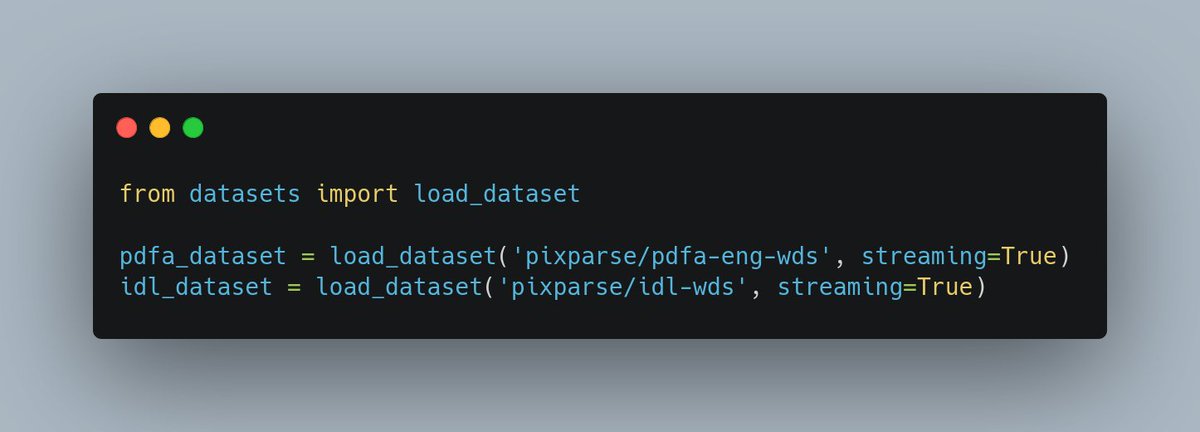
It was hard to find quality OCR data... until today! Super excited to announce the release of the 2 largest public OCR datasets ever 📜 📜
OCR is critical for document AI: here, 26M+ pages, 18b text tokens, 6TB! Thanks to @ucsf_library, @industrydocs and @PDFAssociation
🧶 ↓
My NYT word game group chat has just come up with a new idea: play Wordle, get your score, and then prompt an image generation AI to draw a picture of what you see in your score.
I'll go first.
Wordle 934 6/6
⬜🟦⬜⬜⬜
⬜🟦⬜⬜🟦
🟦🟦🟦🟦⬜
🟧🟧⬜🟦🟦
🟧🟧⬜🟧🟧
🟧🟧🟧🟧🟧
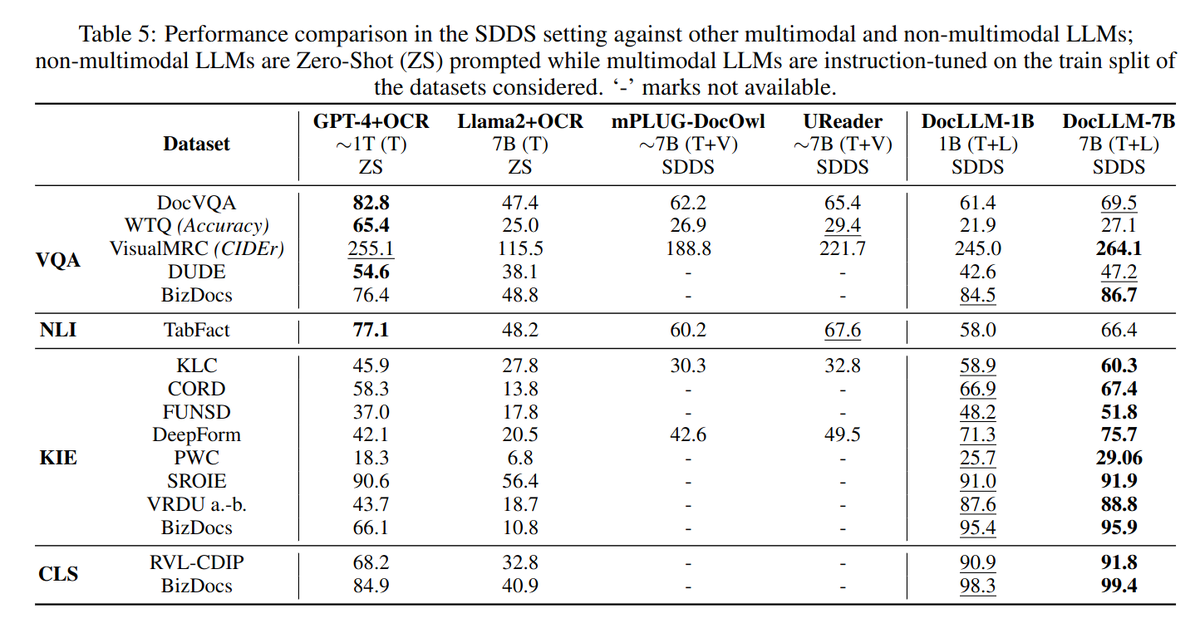
Very excited to introduce DocLLM, a multimodal LLM developed by my colleagues @jpmorgan. DocLLM-7B outperforms other SotA LLMs on 12/16 benchmarks within four core Document AI tasks! Incredibly proud of the team for their hard work. Check it out at https://t.co/BNHo1ia8d5
JPMorgan announces DocLLM
A layout-aware generative language model for multimodal document understanding
paper page: https://t.co/azTKT5jZjH
Enterprise documents such as forms, invoices, receipts, reports, contracts, and other similar records, often carry rich semantics at the intersection of textual and spatial modalities. The visual cues offered by their complex layouts play a crucial role in comprehending these documents effectively. In this paper, we present DocLLM, a lightweight extension to traditional large language models (LLMs) for reasoning over visual documents, taking into account both textual semantics and spatial layout. Our model differs from existing multimodal LLMs by avoiding expensive image encoders and focuses exclusively on bounding box information to incorporate the spatial layout structure. Specifically, the cross-alignment between text and spatial modalities is captured by decomposing the attention mechanism in classical transformers to a set of disentangled matrices. Furthermore, we devise a pre-training objective that learns to infill text segments. This approach allows us to address irregular layouts and heterogeneous content frequently encountered in visual documents. The pre-trained model is fine-tuned using a large-scale instruction dataset, covering four core document intelligence tasks. We demonstrate that our solution outperforms SotA LLMs on 14 out of 16 datasets across all tasks, and generalizes well to 4 out of 5 previously unseen datasets.
I sawed my copy of the power broker in half so that it’s easier to carry around
When a book’s size becomes an impediment to reading it, I feel like something’s gone seriously wrong
Gerty and Carl Cori won the Nobel Prize together in 1947. Then 6 of their students won Nobel Prizes, all in physiology/medicine and chemistry. (Five separate prizes in total; one was shared.) https://t.co/VYkSySJ4SR
Beyond ecstatic for our Cooper Brue team from @cooperunion for winning both best beer label and 3rd place overall in the annual beer brewing competition at AIChE. Go team and thanks Ana for helping us compete! And yes, the poster is hand drawn!
Hello, long time no #crossword! A new #cryptic is up, and I’m pretty happy with it! My favorite clue:
I'm about to stuff fruit with trace of radium — it might bring death (4,6)
https://t.co/PawHGrWrFY
#ML can extract clinically relevant information from EHRs at scale, but evaluating its quality has focused on single variables.
This @flatironhealth study aims to evaluating ML's usefulness for research & RWE generation at scale: https://t.co/iTpSf2JhbX @Cancers_MDPI
Extracting meaningful clinical detail from EHRs for millions of patients with cancer is challenging.
@FlatironHealth uses #NLP & #ML to extract key information from unstructured documents in the curation of high quality #RWD.
Read more on our approach: https://t.co/kaHpx1pEhN