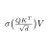Yo @tilderesearch, great work on Wall Attention! However I have not got it stable without convs(?), for the FLA module most maybe. Also I would not rely on tl.where to protect exp2 in your kernel, simple fix to mask scores to -inf before exponentiation, dk is fragile <3
There are only 2 possible reasons to delay weights:
1. It sucks
2. You stole something and want to know if ppl can figure it out
You can jailbreak any open source model with some simple trained kv-injections so "safety" is bs.
we planned to launch our open-weight model next week.
we are delaying it; we need time to run additional safety tests and review high-risk areas. we are not yet sure how long it will take us.
while we trust the community will build great things with this model, once weights are out, they can’t be pulled back. this is new for us and we want to get it right.
sorry to be the bearer of bad news; we are working super hard!
One of the most efficient ways of wasting compute is to use JSON in LLMs. Not to mention the degradation of perplexity...
Don't take my word for it tho, just inspect the attention weights when using MCPs or force the output to follow a JSON schema.
Got a really stupid idea this morning BUT seems its possible to solve arithmetic in ML by just tokenizing smarter and do selective activations. It also solves strawberrry out of the box.
@UnslothAI@danielhanchen@UnslothAI was asking for a x1.15 speedup, I give you x1.31 💃 aaaand works with torch.compile, triton autotune, T4 gpus or just like these benchmarks, out of the box. Still have some more tricks on optimizing it but that is for another night! Also should do the MM in there.
I think its time for a hacknight! @UnslothAI makes good kernels so lets try their challenge.
Always start with the hard ones right? Lets start with a fused nf4 tensor kernel in Triton!
We made 5 challenges and if you score 47 points we'll offer you $500K/year + equity to join us at 🦥@UnslothAI!
No experience or PhD needed.
$400K - $500K/yr: Founding Engineer (47 points)
$250K - $300K/yr: ML Engineer (32 points)
Challenges:
1. Convert nf4 / BnB 4bit to Triton
2. Make FSDP2 work with QLoRA
3. Remove graph breaks in torch.compile
4. Help solve Unsloth issues!
5. Memory Efficient Backprop
If you have any questions about the challenges, please feel free to ask! We're looking for people to help push Unsloth forward - so come join us to democratize AI further!
Our past work includes:
1. 1.58bit DeepSeek R1 GGUFs: https://t.co/gALGkUg5Cg
2. GRPO with Llama 3.1 8B in a Colab: https://t.co/LFdkNxwAYg
3. Gemma bug fixes: https://t.co/7kX94PyKQR
4. Gradient accumulation bug fixes: https://t.co/Tq4c5Qwqyw
Details & submission guide: https://t.co/iXxRUTijWV
@_carlhannes@JoakimEwenson@0x4a45@jhakansson_ Det är ditt samvete som pratar, du vet att du kan göra det där med typ hälften av kod och dubbelt så effektivt. Är det rimligt? Troligen inte, bra jobbat kompis ❤️