Hi there, my name is JP. I’m a developer educator.
I create:
- courses https://t.co/FKWrK2qDsR (@datacamp), https://t.co/wqQKpqe316 (@linkedin learning)
- educational diagrams (https://t.co/BCr1h2tzyL) and projects (https://t.co/wxrj6Uu2UD)
- blogs & videos.
Let’s connect ❤️
Personal update: I’ve joined @liquidai’s Post-Training team.
In this role, I’ll work closely @maximelabonne and @paulabartabajo_ and help build efficient general-purpose AI at every scale.
While it's bittersweet to move on from working with the amazing and talented team at Elastic, I'm beyond excited for this next journey!
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks.
On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
Sources: Starbucks shut down an AI program for automating inventory counts, nine months after deploying it, after it frequently miscounted and mislabeled items (@waylon_wc / Reuters)
(Visit Techmeme dot com for the link and full context!)
Orgs are laying people off "because of AI" and I (and the entire industry) need to talk about how insane all of this is.
I build AI tools. I like AI. This isn't an anti-AI rant. This is an anti-stupidity rant.
Buckle up. Spicy takes galore!
🧵1
What if you could say "meow meow meow" into your computer and find cat pictures?
What if you could search text, images, PDFs, video AND audio in one index? With one model?
I made a video to explain how it works: https://t.co/BV8BU9NQ3M
The new @JinaAI_ v5-omni embedding model capably supports 4(!) modalities while being very small.
Here's a short video that shows you what you can do with it. Full-length video coming next week.
At this point I’ve seen some version of the metaphor of AI as gym equipment that works out for you (so you don’t get anything out of the workout) multiple times. And I really think it’s one of the better comparisons out there. It’s simple, familiar, and people really get it.
Curious to get people's thoughts.
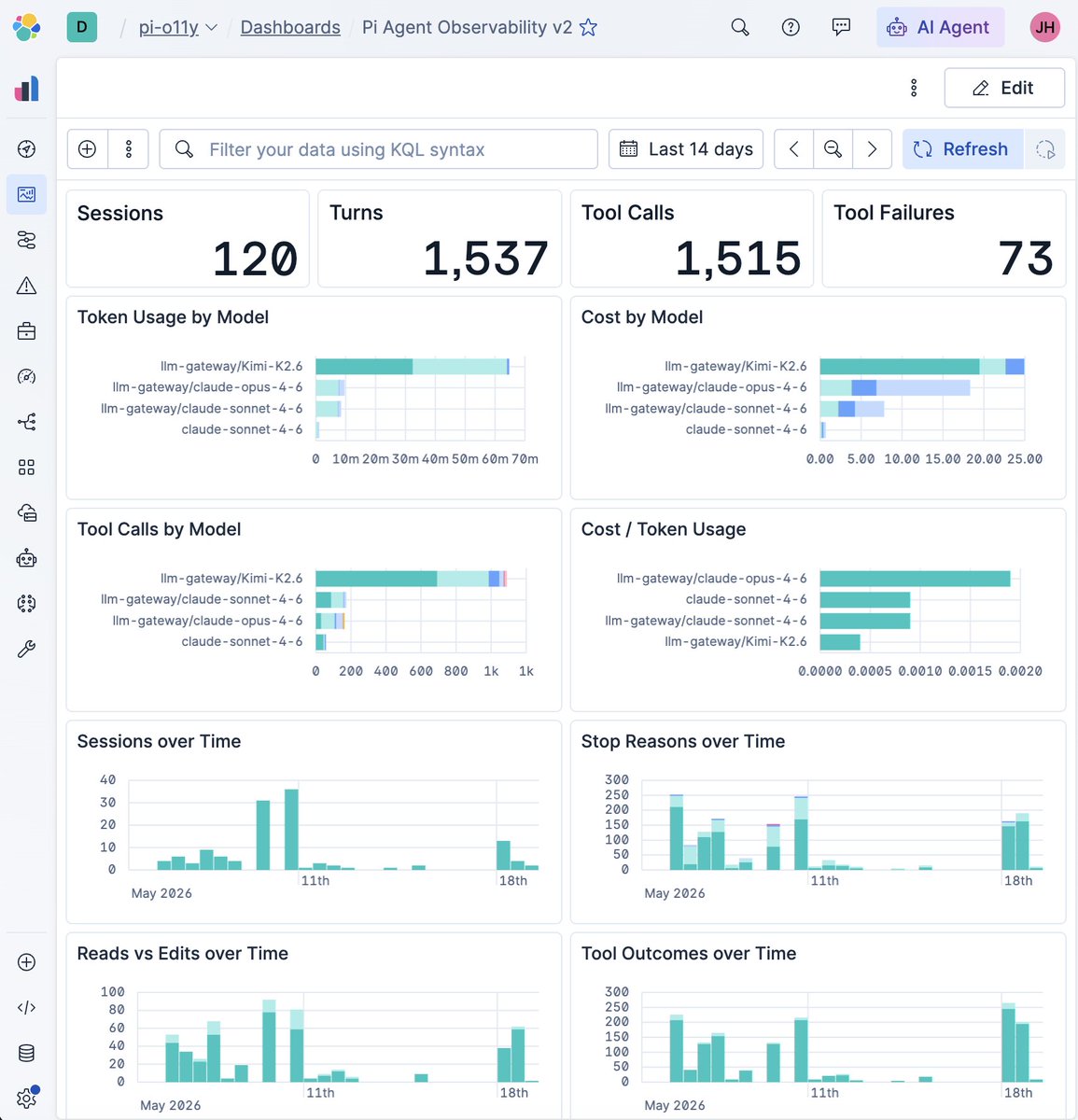
I now log my outputs from @badlogicgames's https://t.co/YlkDIcn3bg into @elastic like this.
The idea is to monitor what my agent is doing. Would you like to learn how to do this?
Comment if prefer a video or just code - thx!
Tomorrow is the night! I'm presenting on MCP context with a touch of the new MCP Observability App from @elastic thrown in. We'll also have talks on token reduction from @Cloudflare, agent sandboxing from @upsundotcom and @Microsoft VSCode support for the MCP spec.
See you then!
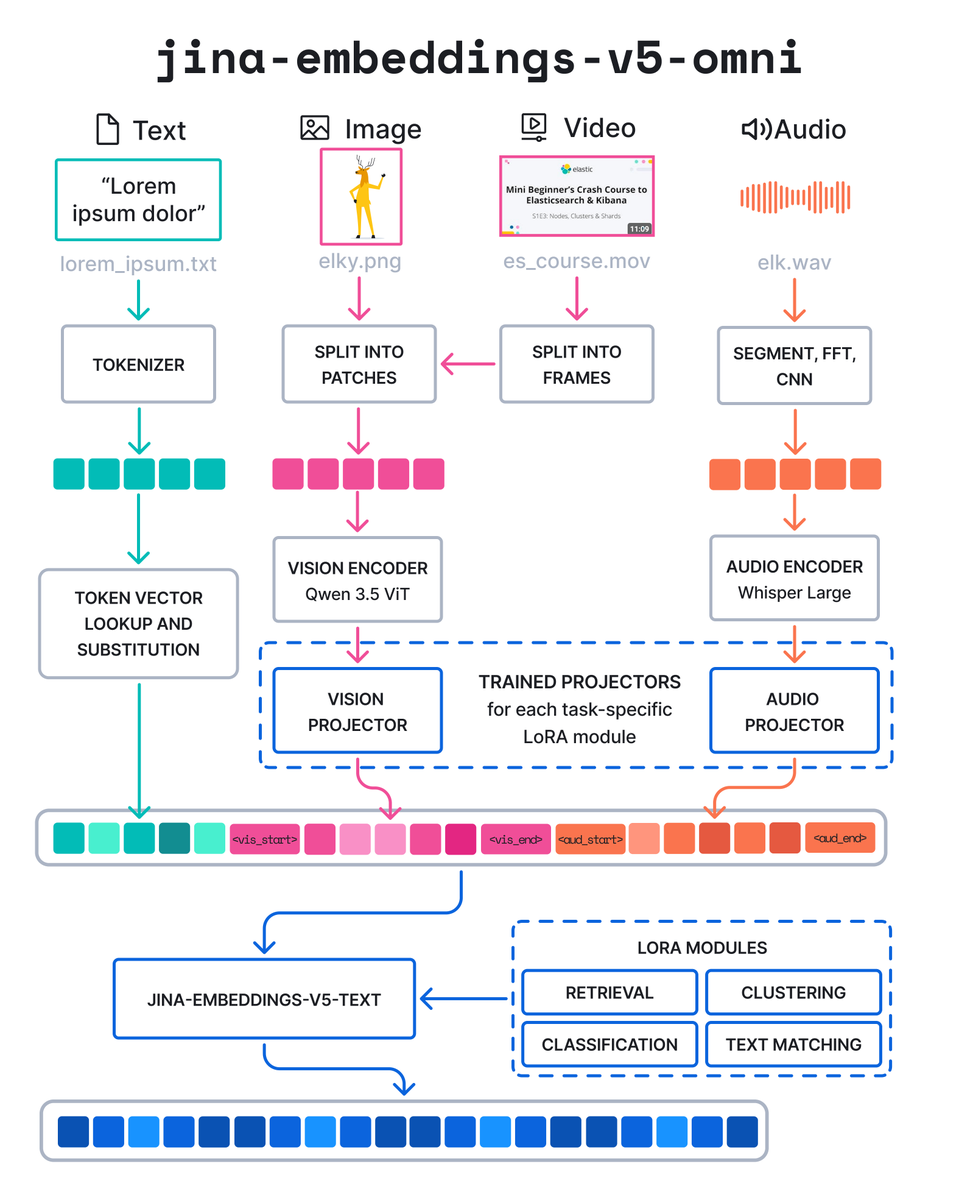
The jina-embeddings-v5-omni family is here!
Multimodal embeddings for text, image, audio, video, and PDF:
• Matryoshka dimensions from 32 to 768 (for nano), and 1024 (for small)
• Supported tasks: retrieval, text matching, clustering, and classification
• nano: 1B parameters, 8K input tokens
• small: 1.7B parameters, 32K input tokens
Available on @elastic inference service (EIS), Jina API, and @huggingface.
Learn more: https://t.co/5ZOmfGFoAe
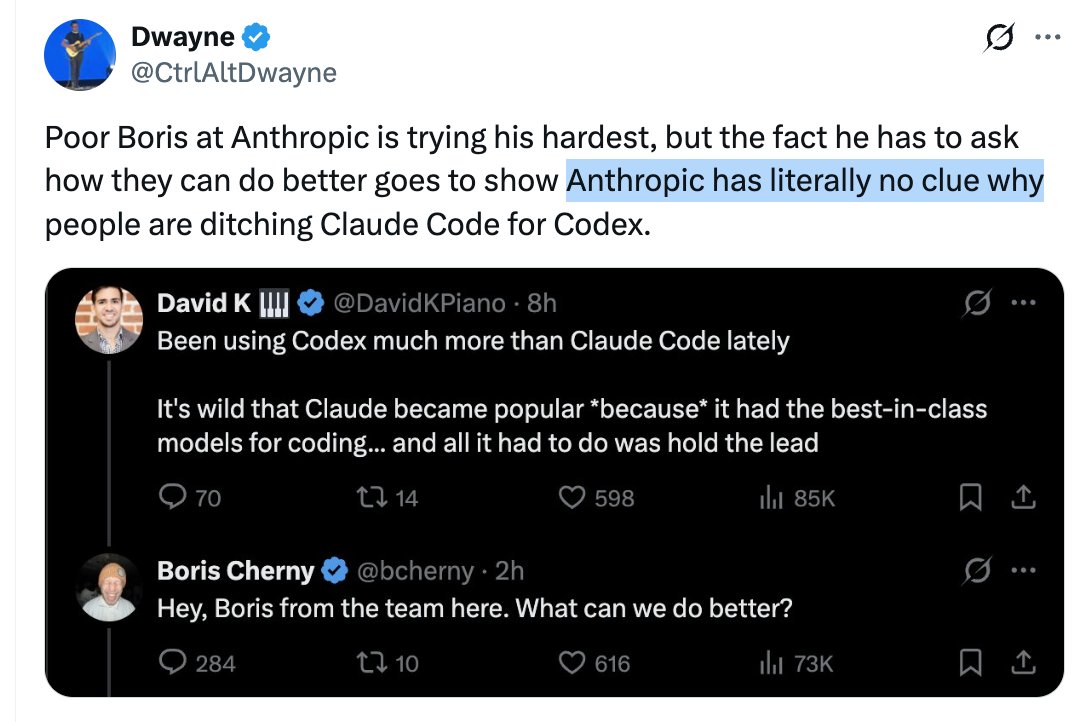
Geez. It's one thing to not like the product, but as far as I can tell @bcherny is asking in good faith.
The discourse is bad enough here without ragging on folk for having trying to have a normal conversation.
Poor Boris at Anthropic is trying his hardest, but the fact he has to ask how they can do better goes to show Anthropic has literally no clue why people are ditching Claude Code for Codex.
I'm very much leaning towards the workflow of:
- Use AI tooling for disposable, one-off jobs
- Use AI to help me learn stuff faster, as a companion to courses & tools
- Code things yourself when it matters, with AI as fancy autocompletes
Wdyt?
jina-embeddings-v5-omni is now on Elastic Inference Service.
Text, images, audio, video. One index, one query.
• Best-in-class visual understanding under 1B parameters
• Beats models 20x its size on multilingual visual tasks
• Beats ByteDance Seed 1.6 on video (55.57 vs 29.30 on Charades-STA)
• BBQ quantization: 93% storage reduction, under 3% accuracy loss
• nano runs on commodity hardware without GPU
Introduction below with @florianhoenicke