Almost nobody does proper credit assignment in RL-on-LLMs 💀
Learning only from the final outcome
→ punishes good steps 😭
→ rewards bad steps 😭😭
🚨New Paper🚨
A new paradigm for credit assignment:
LLMs identify their own mistakes ❌ and propose targeted fixes 🎯
🧵[1/n]
Tomorrow at ExHall A & F Poster Location: 471, 5pm-7pm, we'll present WebGym, together introducing two recently pre-released works (AsyncWebRL and OpenWebRL) as a surprise :)
WebGym: https://t.co/vUva6lTXah
OpenWebRL: https://t.co/79pJpL1NI3
AsyncWebRL: https://t.co/PdvVJTGoQV
To be clear, while I believe human mathematicians will have role to play, it does not mean there won't be a dramatic shift, nor that there is not a sense of loss.
I will personally miss the days of being able to sit, with just pen and paper, and discover via pure thought a mathematical truth than no one knew before.
I’m flying tomorrow to Brazil for ICLR! 🇧🇷
If you’re into continual learning, self-distillation, learning from textual feedback, or just want to chat—let’s meet!
I'll be presenting the following papers:
1/How can we train LLMs to continually improve their reasoning over test horizons much longer than their training token budgets?
Introducing Reasoning Cache (RC), an algorithm that trains LLMs to *extrapolate*.
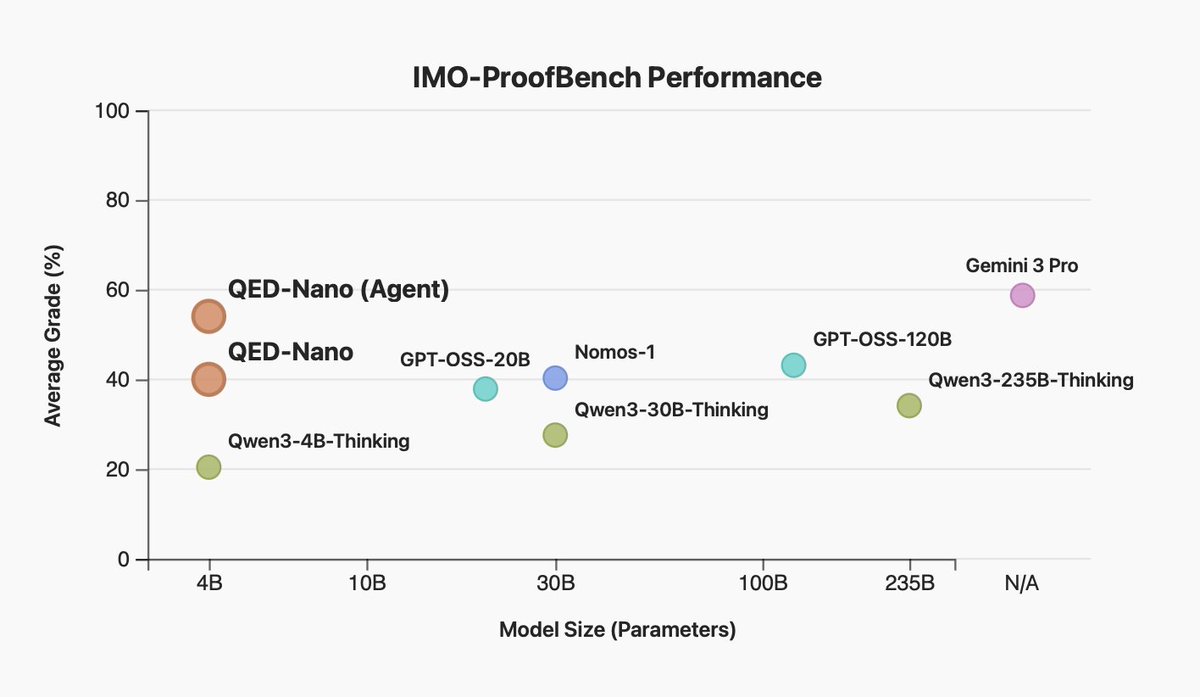
Can just a 4B model solve IMO-level proof problems at the level of much stronger LLMs like Gemini 3 Pro? Yes, if you can train the LLM to scale test-time compute well!
We're very excited to release our 4B model "QED-Nano", built via an awesome open collab! Details below🧵⬇️
@rosmine We tried generating interventions with larger models, namely Qwen3-30B-A3B-Instruct (see section 3) and Gemini 2.5 Pro (see Appendix).
We find that larger models tend to generate better interventions (row 6 vs. row 5).
Almost nobody does proper credit assignment in RL-on-LLMs 💀
Learning only from the final outcome
→ punishes good steps 😭
→ rewards bad steps 😭😭
🚨New Paper🚨
A new paradigm for credit assignment:
LLMs identify their own mistakes ❌ and propose targeted fixes 🎯
🧵[1/n]
🚨🚨New paper
Scaling RL to complex tasks shows credit assignment is a bottleneck
But standard way of fitting PRM + optimizing it is too inefficient to solve it❌
Our idea: use asymmetries in an LLM to let it do its own credit assignment, in natural language w/o PRMs! 🧵⬇️
🚨 New Paper Alert 🚨
💥 SFT on hard tasks given reference solution is usually too off-policy, which can cause the training to crash.
🐌 On-policy RL on these hard tasks introduces low sample efficiency, although more stable.
😈 Today, we introduce Intervention Training (InT), an algorithm that avoids shortcomings of both sides.
A thread 🧵 1/n
😈 Today, we introduce WebGym, the largest-to-date open-source RL environment for web agent training that contains 300k tasks and a rollout framework optimized specifically for web environments' rollout speed. We reveal the effects of essential scaling directions we observe with WebGym.
1/n
🚨🚨New blog post led by CMU students:
Want to know why LLM RL training plateaus on hard problems & scaling compute may not help? And how to fix this issue?
Turns out it stems from a coupling of poor exploration & optimization. Classical ways to explore don't work, but ours does! 🧵⬇️



















![_matthewyang's tweet photo. Almost nobody does proper credit assignment in RL-on-LLMs 💀
Learning only from the final outcome
→ punishes good steps 😭
→ rewards bad steps 😭😭
🚨New Paper🚨
A new paradigm for credit assignment:
LLMs identify their own mistakes ❌ and propose targeted fixes 🎯
🧵[1/n] https://t.co/RSDhOkNP3j](https://pbs.twimg.com/media/G_Nvte0W8AEBlqh.jpg)