I’ve been capturing 3D human motion for 30 years and today is maybe the biggest day in that history. We are presenting MAMMA at CVPR (oral session 2A). MAMMA is a markerless multi-camera system that has accuracy similar to marker-based systems.
I want to offer some unsolicited advice to computer vision researchers jumping into robotics. Don't focus too much on VLMs, VLAs etc. That's fine, but the real action is at the sensorimotor level. Most of the open problems in robotics are in manipulation, which is about hand-object interaction, and contacts and forces are central. Proprioception and tactile sensing are as important as vision. Don't get seduced by cherry-picked demos. You can't do robotics without doing robotics.
Looking for a nice home for your paper? #3DV2027 is waiting! 🎉
⏰ Conference dates: April 6-9, 2027
✈️ Place: #Thessaloniki (#SKG), #Greece 🇬🇷
📝 Paper ddl: Aug 28
🎥 Supp ddl: Sep 02
🆕 Rebuttal only upon invite for borderline papers!
#CallForPapers: https://t.co/6Fy3QG7PRE
working on human motion and in #3DV206 ?
then don’t miss this interesting work!
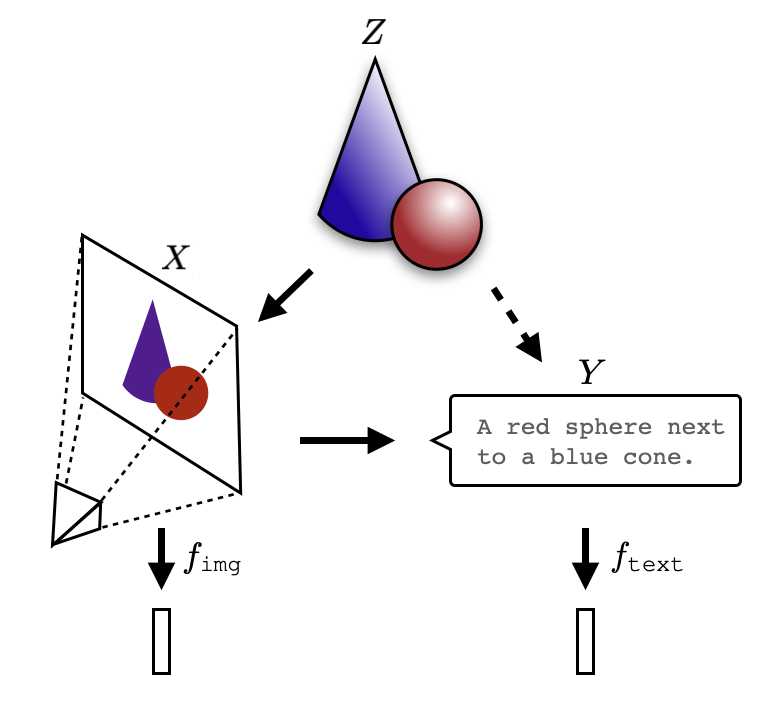
in “Dense Motion Captioning”, the authors propose a new task, dataset, and the model for dense 3D human motion captioning
Most research time isn’t spent thinking of ideas.
It’s spent checking prior work, testing hypotheses, debugging silent bugs, organizing results, making slides.
The parts where weeks of work silently disappear.
I tried encoding some of that experience as “Agent Skills”.
BEDLAM2.0 image and depth data are now available via Hugging Face, providing high-speed worldwide download access to over 26TB of synthetic data for non-commercial research.
Hugging Face: https://t.co/tl8S3DJNWw
Project: https://t.co/NR5Np9UT46
Big news: @Meshcapade is now part of Epic Games. This is a perfect match for our technology and team and I am super excited about what we will build together.
I want to thank our many supporters who have provided funding and/or advice on our journey from 2018 to today, including @MP_Innovation, @maxplanckpress, @MPI_IS, @PerceivingSys, @matrixvc, @dcstalder, @dianaberlin, @HV_Capital, Zuzanna Czapinska, LBBW VC, @GoodwaterCap, CLO Virtual Fashion (@itsclo3d), @grbradsk, @lucvincent, @JeffDean, @ballmatthew, Andrew Hamel, Bill O’Farrell, Ammar Zakiullah, @Nicolas_Keller, Alex Diehl, @goodwinlaw, YPOG, @NVIDIA Inception Program, @msft4startups, and many more!
Most importantly, I want to thank my co-founders @naureenmahmood and Talha Zaman and the whole @Meshcapade team. There is nothing more rewarding than working with great people who you like and trust to build products that customers love using technology you believe in. Thank you, thank you, thank you. Now, on to the next phase!
https://t.co/fmMYXfSSoK
Quite literally all of 3D vision
This includes VGGT, Dust3r and friends which are trained on COLMAP-generated data
Also gaussian splatting and NERFs in most cases use COLMAP-generated poses
Introducing CARI4D: category agnostic 4D reconstruction of human object interaction. We reconstruct consistent 4D human-object from just an RGB video.
Website: https://t.co/F5dmTBURSD
Paper: https://t.co/6Bv6xHpoDp
Code: https://t.co/pkuS9f5nrz
I'll be presenting BEDLAM2.0 at NeurIPS this morning. 10:40am, Oral 5C Generation/Simulation 3, Upper Level Ballroom 20AB. Come see how we train state-of-the-art 3D human pose and shape estimation using synthetic data. The dataset and code is on-line here: https://t.co/NR5Np9VqTE
Heading to Hawaii🏝️for @ICCVConference ?
You definitely won't want to miss our workshop!
Interactive Human-centric Foundation Models!
⏰Oct 19 9:00 am - 5:15 pm
📍Room 317A
We have @Michael_J_Black@liuziwei7 Umar Iqbal, Yuan Zhou, Evonne Ng, @AilingZeng81332 Lan Xu @akanazawa
This work stems from the idea that all data modalities (images, sounds, text, etc) are views of the same underlying world, and treating them as such is useful.
We are interested in identifying commonalities between different models + modalities, and providing unifications.
2/9
📢Submit your cutting-edge research in the domain of computer graphics to #Eurographics2026.
The deadline is in 4 weeks on Sept. 26th.
https://t.co/qpC5yvg3Zw
🚀We are thrilled to open-source Hunyuan-GameCraft, a high-dynamic interactive game video generation framework built on HunyuanVideo.
It generates playable and physically realistic videos from a single scene image and user action signals, empowering creators and developers to "direct" games with first-person or third-person perspectives.
Key Advantages:
🔹High Dynamics: Unifies standard keyboard inputs into a shared continuous action space, enabling high-precision control over velocity and angle. This allows for the exploration of complex trajectories, overcoming the stiff, limited motion of traditional models. It can also generate dynamic environmental content like moving clouds, rain, snow, and water flow.
🔹Long-term Consistency: Uses hybrid history condition to preserve the original scene information after significant movement.
🔹Significant Cost Reduction: No need for expensive modeling/rendering. PCM distillation compresses inference steps, boosting speed and lowering costs. This allows the quantized 13B model to run on consumer-grade GPUs like the RTX 4090.
Project Page: https://t.co/uAbiu9FRzF
Code: https://t.co/WgppVz1KUq
Technical Report: https://t.co/aO8plomaTr
Hugging Face:https://t.co/2ZOUWm6KKQ
Contact. Contact. Contact. For spatial intelligence, this is what location, location, location is in real estate. InteractVLM predicts 3D contacts on humans and objects from a single image. This is a key step in training machines to interact with the 3D world.
📢 R u in Athens on July 22? 📢 Check out the #ComputerVision Day @ ArchimedesAI! Talks:
👉@VickyKalogeiton: 'Efficient Brains that Imagine'
👉Dimitris Samaras: 'From Saliency to Scanpaths: 20 years of Wandering Eyes'
👉@dimtzionas: 'Towards In-the-Wild Understanding of 3D Human-Object Interactions'
🙏 Thank you to the organizers: @KostasPenn, @SilaVasileiou!
ℹ️ Info: https://t.co/LdBaHLqoqc
Physical intelligence for humanist robots. At @meshcapade we've built the foundational technology for the capture, generation, and understanding of human motion. This blog post explains how this enables robot learning at scale.
https://t.co/GWRzb3529k
https://t.co/nToCEv8hb0
It's clear that video diffusion models know a lot about the 3D world, material properties, and lighting. The trick is to get control over these. With a tiny amount of synthetic data, we can train a video model to realistically relight a single image. This is a neat trick that points to the future of controllable synthesis.