Also found out I’m more into agentic work and architecture rather than vibecoding ai slop. Will dive more into it + review and adjust current weaknesses.
First hackathon today at the Madrid Cursor event.
It went bad for me, but def had a great time. Learned a lot on how little the HITL has to “do”, and how powerful @cursor_ai is. Thanks for the credits and the experience! Not my last for sure.
The jump from windows/linux machines to macOS unified memory is massive, as well as the jump from ddr4 to ddr5, and 8 to 16 to 24gb. If you’re learning, researching or experimenting with ai, get the most ram (and VRAM) that you can afford.
A year ago at GTC, Jensen brought out a DGX Spark in one hand and a MacBook in the other.
Yesterday, at GTC Taipei, Jensen brought out NVIDIA's new RTX Spark laptop in both hands.
This is the start of a new era of personal computing - the personal AI era.
In the new era, there are two competing platforms:
- @apple with macOS / MLX
- @nvidia with Windows / CUDA
Everyone will have an always-on personal agent that runs locally, constantly looking out for you, working for you proactively, monitoring the internet and talking to other agents. This will be a personal AI agent you own, that's private, that's aligned with you (not OpenAI or Anthropic). @karpathy calls it personal computing v2.
Let's set the scene for the new era of personal computing by diving into the one thing that will matter the most - the hardware.
The best hardware for local AI isn't what's running in a data center. It's a radically different problem. Here's a breakdown of the 3 most important things:
1. Memory.
LLMs are big. To run a model locally, you need to fit the entire model into memory. Apple (with Apple Silicon) and NVIDIA (with DGX Spark + RTX Spark) have both moved towards unified memory, which puts all the memory on one chip - leveraging cheaper LPDDR5X memory - useful for making more memory accessible to the GPU. The alternative competing architecture is a disaggregated CPU/GPU architecture - which is what the DGX Station uses. It has a large pool of slow LPDDR5X CPU memory (496GB @ 396GB/s), and a small pool of high-speed HBM3e GPU memory (252GB @ 7.1TB/s). It has a high bandwidth link (900GB/s) between the CPU memory and GPU memory, enabling fast disaggregated inference e.g. Attention on GPU, FFN on CPU. This enables running really large models like Kimi K2.6 (1T parameters) by offloading experts from CPU memory to GPU memory as they are needed. You could imagine something like this in a smaller form factor.
Hardware today:
- Apple M5 Max MacBook Pro: 128GB unified memory.
- NVIDIA DGX Spark / RTX Spark: 128GB unified memory.
2. Memory bandwidth.
In a data center, multiple user's requests can be batched together, which amortizes the cost of moving model weights into memory across many requests, pushing up arithmetic intensity to compute bound territory - meaning FLOPS matters a lot. Locally, everything runs at low batch size, which is low arithmetic intensity, i.e. memory bound - so FLOPS don't matter. What matters memory bandwidth. High memory bandwidth -> fast TPS. Low memory bandwidth -> slow TPS.
Hardware today:
- Apple M5 Max MacBook Pro: 617GB/s memory bandwidth.
- NVIDIA DGX Spark: 273GB/s memory bandwidth.
- NVIDIA RTX Spark: TBC.
3. Power.
In a data center, we talk about MegaWatts. Locally, we talk about Watts. Laptops have limited battery life. The best laptop batteries have a capacity of ~100Wh. LLM inference on a MacBook Pro consumes ~140W, meaning battery life with a persistent personal agent is less than an hour. This is unusable. The game will become how long can you run a useful agent on a laptop battery. Apple and NVIDIA will compete on how long an agent can run on battery - this will become the new battery life metric. This could be where an NPU or NPU/GPU hybrid really shines. Apple ANE has about 10x better power efficiency than the GPU on Apple Silicon (but has ~4-5x less memory bandwidth, with about the same FLOPS as the GPU). There will be an entire design space of how to build energy efficient agents - this will involve co-optimizing the harness, models, inference engines together.
Hardware today:
- Apple M5 Max MacBook Pro: Consumes 140W, battery capacity ~100Wh
- NVIDIA DGX Spark: Rated for 240W, consumes 140W. No battery (direct PSU).
- NVIDIA RTX Spark: TBC.
The hardware battle will be fierce, and I expect a move towards co-design, i.e. hardware designed *with* personal agent workloads. On top of this, models are improving, we're getting more intelligence per bit/watt, and open-source harnesses like @NousResearch Hermes / OpenClaw are improving rapidly. Within the next 2 years, we'll inevitably have unmetered, private Opus-4.8 / GPT-5.5 level intelligence running locally on a future version of a MacBook or RTX Spark. I like this future a lot better than the one where OpenAI / Anthropic control the intelligence layer of the internet and can rent-seek on intelligence.
Beyond this, NVIDIA is ahead on general AI ecosystem, i.e. the CUDA moat. Apple is ahead on local AI ecosystem, i.e. models quantized/rightsized for MacBooks, native macOS apps, and ease of setup. We'll see how this might change as the new RTX Spark also brings full native CUDA to Windows-on-Arm laptops for the first time, potentially closing the gap.
There are many other factors I haven't mentioned here, but I believe I've covered the timeless, most important things for the new era of personal computing.
I’ve been using agy (Antigravity) CLI for work these past days and it’s been great side to side with codex. Feels snappy, pretty smart and generous limits so far. Recommended.
What if you hosting a model was as simple as browsing a website, and picking a working configuration?
You'd know how fast, and how popular a model is, on any hardware. Coming soon.
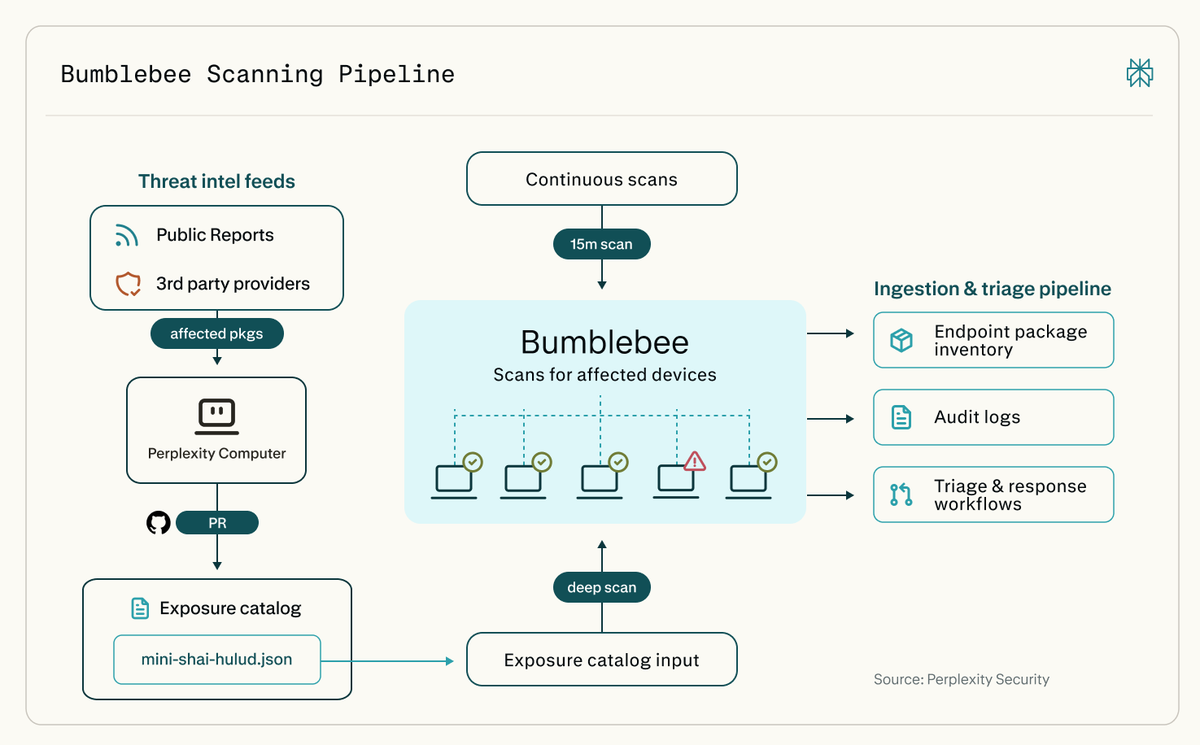
Today we're open-sourcing Bumblebee, a read-only scanner for macOS and Linux.
It checks developer machines for risky packages, extensions, and AI tool configs.
Connected to Computer, it can trigger deeper scans whenever a new supply-chain risk emerges.
https://t.co/FOaWnF1yQy