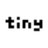China released an AI employee that works 24x7 on its own and runs 100% locally
It researches, codes, builds websites, creates slide decks, and generates videos. All by itself. All on your computer.
100% Open Source.
AI storytelling is getting crazy
ChatGPT Image 2 can turn one story idea into a full storyboard, then Seedance 2.0 turns it into a cinematic animated video in minutes.
step by step tutorial with prompts:
As always, Thank you for reading this.
If you enjoyed this post:
1. Follow me @hasantoxr for more of these
2. RT the tweet below to share this thread with your audience
Yann LeCun (AMI Labs Founder): "The AI industry is completely LLM-pilled. Everybody is working on the same thing. They're all digging the same trench."
LeCun explains why no lab dares break from the pack:
"They are stealing each other's engineers. So they can't afford to do something different because if they start going on a tangent, they're going to fall behind the other guys. And so they're all doing the same thing."
This groupthink is exactly what drove him out of Meta.
"Meta also became LLM-pilled with sort of recent reshuffling. And it's fine, a strategic decision that maybe makes sense for them. It's just not what I'm interested in."
For @ylecun, the problem runs deeper than strategy.
LLMs are missing something essential about how intelligence actually works:
"I cannot imagine that we can build agentic systems without those systems having an ability to predict in advance what the consequences of their actions are going to be. The way we act in the world is that we can predict the consequences of our actions and that's what allows us to plan."
His broader critique is that the industry has mistaken fluency for intelligence.
Language turned out to be the easy part. The hard part is the physical world.
It's why we still don't have domestic robots or level-five self-driving cars, even though today's systems can pass the bar exam and write code.
read this carefully anon. @pupposandro wrote a single fused CUDA kernel for all 24 layers of Qwen 3.5-0.8B. one kernel launch. absolutely zero CPU round trips between layers. the result?
a $900 RTX 3090 from 2020 hit 411 tok/s. apple's M5 Max hit 229. the 3090 won on speed AND efficiency 1.55x faster than llama.cpp on the same hardware.
the gap between NVIDIA and Apple was never about silicon. it was software. generic frameworks waste cycles on kernel launch overhead, memory re fetches, thread synchronization. when you fuse everything into one dispatch the hardware shows what it actually has.
this is the beginning of something bigger. we already proved that a 27B dense model on a single 3090 one-shots what $70K enterprise hardware cannot. now imagine what happens when someone writes kernels optimized specifically for the 3090 and the models that run best on it. not generic inference. hardware specific, model specific fused from the kernel level up.
the 3090 is not a relic. it's an untapped research platform. and the people writing these kernels are proving it with data.
all open source and reproducible anon.
@KatieMiller I think the first "super intelligence" will come from someone who starts listening to real mathematicians... and not chasing grants. That's all I wanted.
Racing GPT 5.4 xhigh, Opus 4.6, and Kimi K2.5 adding Gemma 4 support to tinygrad. I gave them each their own GPU on a tinybox red.
GPT has E2B working and is on to MoE support, Opus runs but has some bug and is looking at norms and scale, and Kimi messed up adding GGUF bfloat16.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
@SarvamForDevs@SarvamAI Email: [email protected] 📧
Use case: Leveraging @SarvamAI to bring heritage to the digital age! We use your speech models and OCR to turn regional religious discourses and sacred texts into highly engaging, interactive blogs. 📖✨
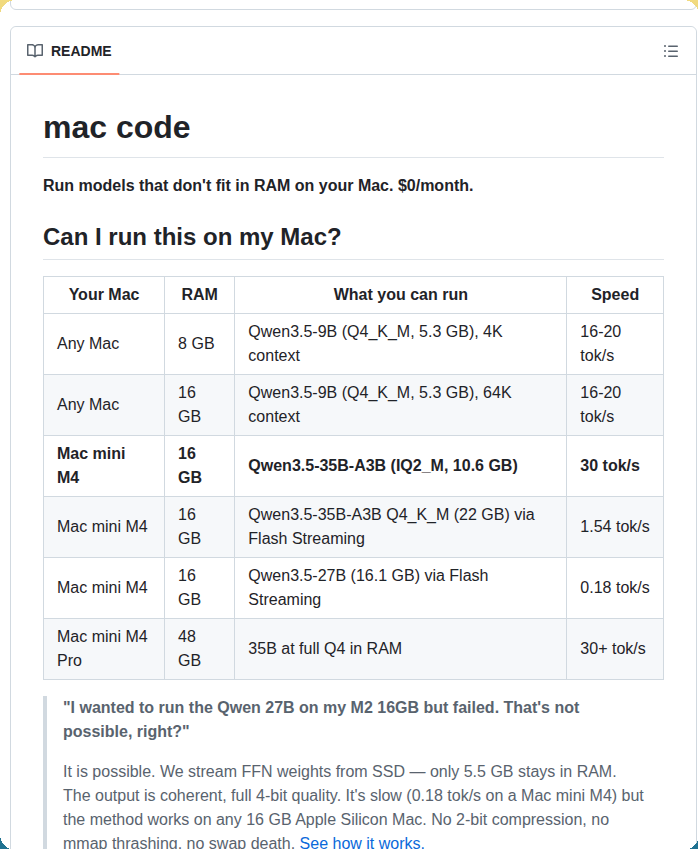
LangChain just open-sourced a replica of Claude Code.
It’s an MIT-licensed framework that recreates the core workflow behind coding agents like Claude Code but in an open system developers can inspect and modify.
It is called Deep Agents.
I spent a bit of time looking through the repo and it’s actually a pretty helpful reference if you’re trying to understand how these coding agents are structured.
Here's what's inside:
→ Planning tools for breaking down tasks
→ File system access for reading, writing, and editing code
→ Shell command execution with sandboxing
→ Sub-agents for handling complex work in parallel
→ Auto-summarization when context gets too long
Another useful aspect is that it’s model-agnostic, so you can plug in different LLMs and experiment with building your own coding agents on top of the same structure.
If you’re exploring agent frameworks or just curious how tools like Claude Code work under the hood, this is a pretty good repo to bookmark.
Link in the comments.
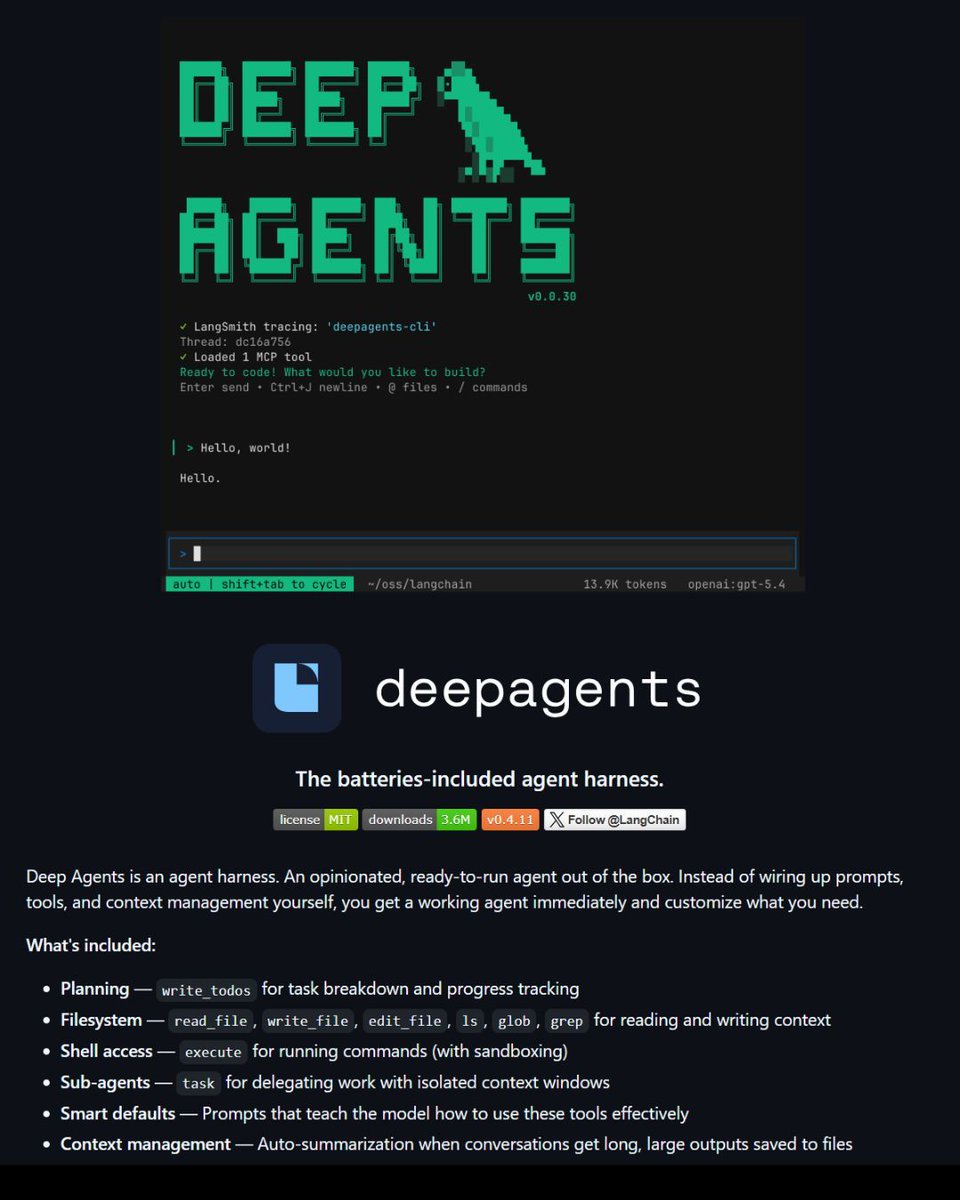
🚨 R.I.P static AI agents.
Someone just built a self-evolving OpenClaw wrapper and dropped it for free on GitHub.
It's called MetaClaw.
→ Intercepts every OpenClaw conversation and scores it
→ Builds a skill bank from real usage not synthetic data
→ Auto-generates new skills every time the agent fails
→ Injects them into the system prompt on the next turn
→ Trains via cloud LoRA no GPU cluster, no infra headache
→ Fully async agent keeps responding while it learns
Most agents need a data team, a fine-tuning pipeline, and weeks of work to improve.
MetaClaw does it while your users are typing.
100% Open Source. MIT License.
(Link in the comments)
BREAKING: Google just open-sourced an official CLI for the entire Google Workspace.
Gmail. Drive. Calendar. Docs. Sheets. All from your terminal.
Here is what makes it genuinely different:
→ One tool to control your full Workspace from the command line
→ Ships with 100+ built-in AI agent skills out of the box
→ Built-in MCP server one command (gws mcp) and any AI agent controls your Workspace
→ Official Google release, not a third-party wrapper
→ Written in Go, fast and lightweight
16,600 stars in weeks. AI agents just got a direct line into Google's entire productivity suite.
100% Free and open source.
You can now clone any voice on a 4GB GPU.
LuxTTS just killed the "you need ElevenLabs" excuse.
It clones voices from 3 seconds of audio at 150x realtime speed.
Fits in 1GB VRAM. Faster than realtime even on CPU.
→ 48khz output vs industry standard 24khz
→ Clone any voice locally with no subscription
→ Works on GPU and CPU
100% Opensource.