Jailbreaking research assumes a fixed model.
Test-time training breaks that assumption: the attacker gets a lever on the weights, not just the prompt.
We show this opens a new attack surface that undermines LLM safety guardrails.
🧵 (1/6)
1/5 Ever wondered how to apply conformal prediction when there's epistemic uncertainty? Our new paper addresses this question!CP can benefit from models like Bayesian, evidential, and credal predictors to have better prediction sets,for instance, in terms of conditional coverage.
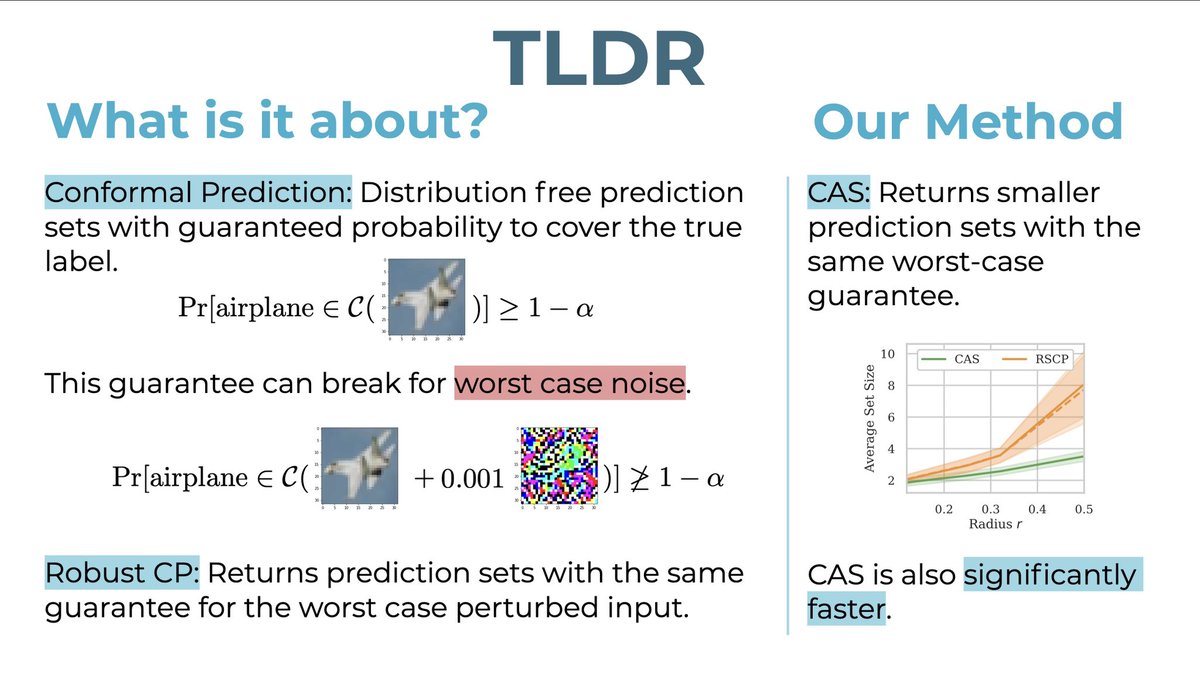
🚨 Robust conformal prediction is expensive as we need around 10000 forward passes per input. Or Is it?
Checkout our ICLR2025 paper: https://t.co/X5oPogW94b
We extend conformal sets to worst case noise under any smoothing, with much less samples.
Joint work with @abojchevski
Want to learn continuous & discrete Flow Matching? We've just released:
📙 A guide covering Flow Matching basics & advanced methods https://t.co/uf3zDfhdKe.
💻 An open source codebase with image & text examples https://t.co/Nfsoss8ZP2.
🗣️ A Flow Matching tutorial #NeurIPS2024.
Missed out on #Swift tickets? No worries—swing by our #SVFT poster at #NeurIPS2024 and catch *real* headliners! 🎤💃🕺
📌Where: East Exhibit Hall A-C #2207, Poster Session 4 East
⏲️When: Thu 12 Dec, 4:30 PM - 7:30 PM PST
#AI#MachineLearning#PEFT#NeurIPS24
A common question nowadays: Which is better, diffusion or flow matching? 🤔
Our answer: They’re two sides of the same coin. We wrote a blog post to show how diffusion models and Gaussian flow matching are equivalent. That’s great: It means you can use them interchangeably.
1/ Can Large Language Models (LLMs) truly reason? Or are they just sophisticated pattern matchers? In our latest preprint, we explore this key question through a large-scale study of both open-source like Llama, Phi, Gemma, and Mistral and leading closed models, including the recent OpenAI GPT-4o and o1-series.
https://t.co/2tv8Pp9MSz
Work done with @i_mirzadeh, @KeivanAlizadeh2, Hooman Shahrokhi, Samy Bengio, @OncelTuzel.
#LLM #Reasoning #Mathematics #AGI #Research #Apple
I am happy to announce that @abojchevski, Michael Schaub, Martin Grohe, and I are organizing a @LogConference local meet-up in Aachen (27.11.-28.11.), including keynotes from @guennemann and @BurkholzRebekka. See https://t.co/6thuTXpSy0 for more information.
✨🎨🏰Super excited to share our new paper Ensemble everything everywhere: Multi-scale aggregation for adversarial robustness
Inspired by biology we 1) get adversarial robustness + interpretability for free, 2) turn classifiers into generators & 3) design attacks on vLLMs 1/12
#ICML2024 With conformal prediction (CP) we return sets that include the true class with guaranteed high probability,
With robust CP we maintain this probability even for worst case (adversarial) noisy input. With CAS (our method) we have robust CP with efficient (small) sets.
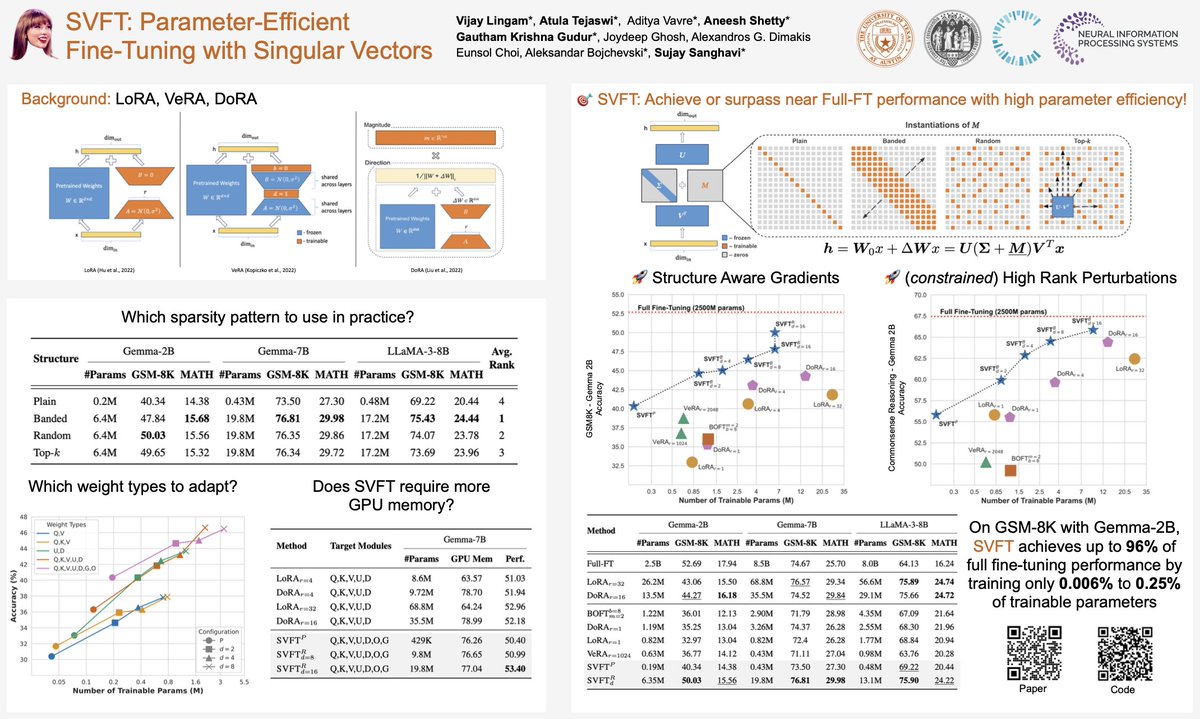
🎉Happy to announce that our paper – SVFT: Parameter-Efficient Fine-Tuning with Singular Vectors has been accepted for an oral presentation at WANT @icmlconf!✨#ICML2024#MachineLearning
Paper: https://t.co/adiv1AGS6L
🚀 Exciting new paper alert! Achieve up to 96% full performance with just 0.006-0.25% of trainable parameters!✨ How? It’s all in the singular vectors! Introducing 🎯SVFT: Singular Vectors guided Fine-Tuning for PEFT. Here’s a quick breakdown!🧵 #AI#MachineLearning#NLP#CV
This paper made me smile a lot while working on it, so I want to share a bit about it https://t.co/egypZTIky9.
We draw a parallel story to the Eckart-Young Theorem (from numerical analysis) in stochastic optimization/learning problems.
(with Josh Cutler and Dima Drusvyatskiy)
Another entry in a long-running series where Nicholas Carlini breaks ML defenses published at top security conferences with as little effort as possible (in this case a one line bugfix in the eval)
We introduce Spatio-Spectral GNNs (S²GNNs) – an effective modeling paradigm via the synergy of spatially and spectrally parametrized graph conv. S²GNNs generalize the spatial + FFT conv. of State Space Models like H3/Hyena.
Joint work w/ @ArthurK48147@dan1elherbst@guennemann
On tasks like coding we can keep increasing accuracy by indefinitely increasing inference compute, so leaderboards are meaningless. The HumanEval accuracy-cost Pareto curve is entirely zero-shot models + our dead simple baseline agents.
New research w @sayashk@benediktstroebl 🧵