This paper made me smile a lot while working on it, so I want to share a bit about it https://t.co/egypZTIky9.
We draw a parallel story to the Eckart-Young Theorem (from numerical analysis) in stochastic optimization/learning problems.
(with Josh Cutler and Dima Drusvyatskiy)
Today, we share a breakthrough on the planar unit distance problem, a famous open question first posed by Paul Erdős in 1946.
For nearly 80 years, mathematicians believed the best possible solutions looked roughly like square grids.
An OpenAI model has now disproved that belief, discovering an entirely new family of constructions that performs better.
This marks the first time AI has autonomously solved a prominent open problem central to a field of mathematics.
New paper studies when spectral gradient methods (e.g., Muon) help in deep learning:
1. We identify a pervasive form of ill-conditioning in DL: post-activations matrices are low-stable rank.
2. We then explain why spectral methods can perform well despite this.
Long thread
NEW PAPER ALERT 📢 Score-based diffusion models are powerful—but slow to sample. Could there be something better? Drop the scores, use proximals instead! We present Proximal Diffusion Models (ProxDM), a faster alternative both in theory* and practice. Here’s how it works 🧵(1/n)
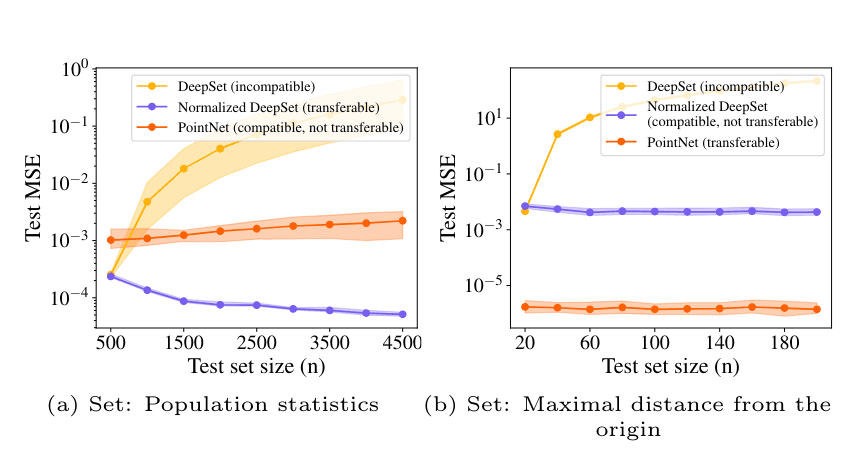
When does the performance of an ML model transfer across dimensions?
https://t.co/cqFMdgl6ZV
Kudos to my terrific collaborators Eitan Levin, Yuxin Ma, and @SoledadVillar5.
🧵(1/n)
Interestingly, the way in which we identify low-dimensional objects with high-dimensional objects and the choice of the norm for continuity play crucial roles. The task of interest has to be aligned with these choices; otherwise, transferability might fail.
(15/n)