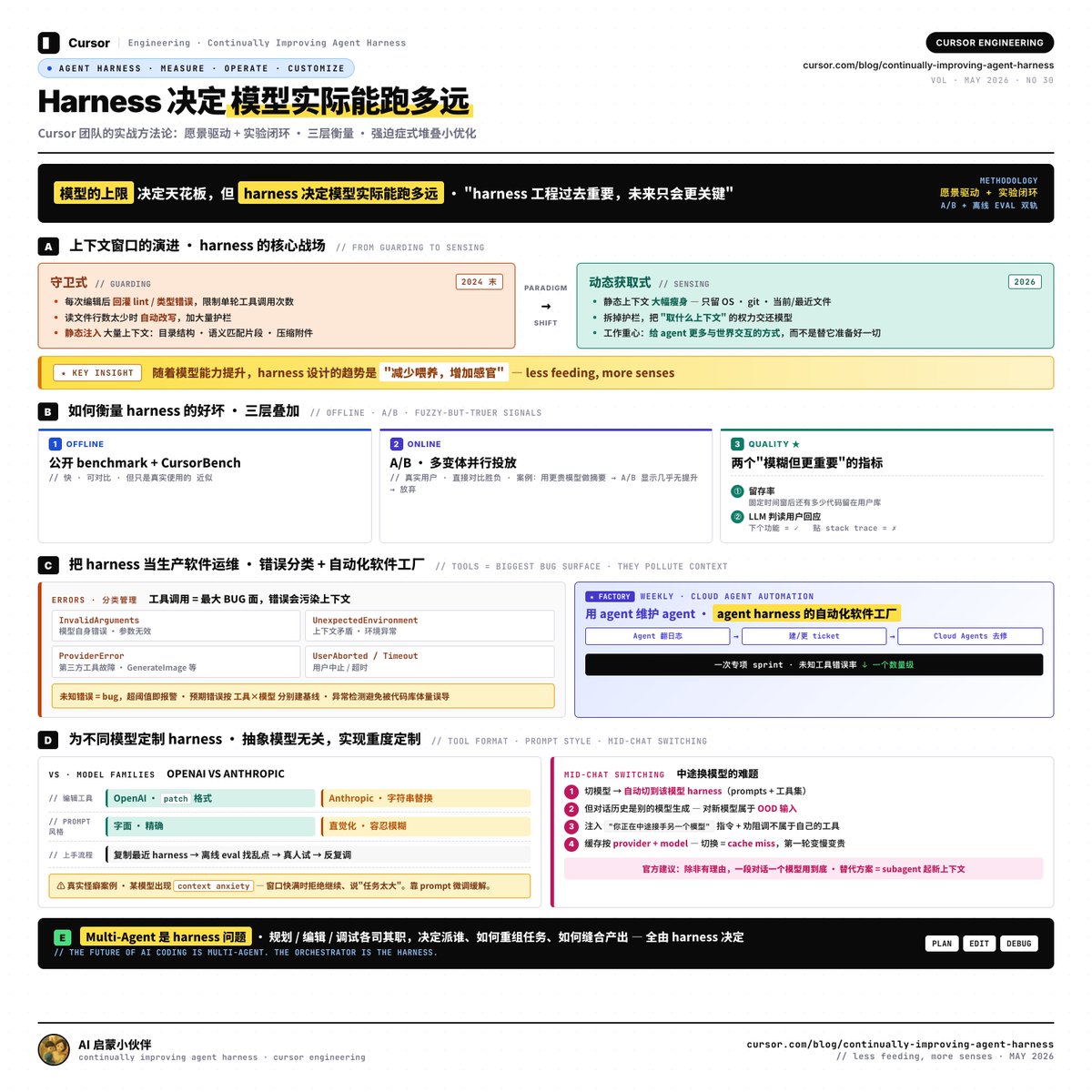
AutoResearch AI 这论文挺值得看的。
它讲的不是“AI 帮你总结论文”这种单点能力,而是一个更��的趋势:科研正在从 task-level AI,走向 workflow-level AI。
也就是说,AI 以后不只是帮你查文献、写代码、润色论文,而是可能参与完整科研流程:读文献、找问题、提假设、设计实验、调用工具跑实验、验证结果、写报���、再根据反馈修改。
论文里有个概念叫 Vibe Research,我觉得很形象:现在很多科研人其实已经在做了。人类给方向,AI 帮忙查、写、跑、改,最后人类负责判断和验证。
但作者也很清醒:真正的 AI 科学家还没到来。当前系统最大的问题不是会不会生成想法,而是证据能不能保存、实验能不能复现、弱方向能不能被及时拒绝、结论能不能追溯来源。
我觉得这篇文章最大的启发是:未来科研能力的竞争,可能不只是“谁会用 AI 写论文”,而是谁能搭出一套可靠的 AI research workflow。
AI for Science 的下一步,不是更会聊天的科研助手,而是更可验证、更可复现、更能闭环的科研工作流。
https://t.co/prnPUiBckS
#AIforScience #AutoResearch #Codex #claudecode
🔥LLaVA-OneVision-2.0 Open Sourced🔥
LLaVA-OneVision series @lmmslab now upgrades to 2.0 with its key advance on *codec-stream tokenization*, which treats highly dynamic video as a continuous bit-cost stream
- Tech Report: https://t.co/pFo2fGYj2M
- Code: https://t.co/JvRzu96rJ1
Flash-KMeans was only the beginning.
Today, from the Flash-KMeans team, we are releasing FlashLib — a GPU library for fast, predictable, agent-ready classical ML operators.
Up to 26× on KMeans, 19× on KNN, 40× on HDBSCAN, 208× on TruncatedSVD, 47× on PCA, 147× on exact t-SNE, and 49× on MultinomialNB over state-of-the-art (cuML).
Blog: https://t.co/P31SGl0cyT
Code: https://t.co/9nkO2hmeOl
What if LLMs could reason smarter, not just longer?
Researchers from Huawei Taylor Lab, Peking University, and Shanghai University of Finance and Economics introduce SHAPE.
The method rewards actual progress in reasoning — not verbosity — by using a two-level system: a stage-aware advantage at the segment level for efficient breakthroughs, and entropy-driven redistribution at the token level for sharper execution.
Result: 3% higher accuracy on math reasoning while using 30% fewer tokens across multiple base models and benchmarks.
SHAPE: Stage-aware Hierarchical Advantage via Potential Estimation for LLM Reasoning
Paper: https://t.co/Rsur6rgbWn
Our report: https://t.co/g9Eaw7BebN
📬 #PapersAccepted by Jiqizhixin
PyTorch Autograd vs. Unsloth Triton Kernels.
The core engineering behind UnslothAI has always been impressive!
Instead of relying on PyTorch's default autograd for backpropagation, Unsloth built their own backprop kernels from scratch in OpenAI's Triton language (a Python-based language for writing GPU kernels without needing to write raw CUDA C++).
One of the reasons to do this is that the default autograd runs each operation as a separate GPU call, and each call reads and writes data back to global memory before the next one can start.
Across dozens of transformer layers, this back-and-forth becomes the real bottleneck.
These hand-written kernels fuse operations like QKV projections and rotary position embeddings into single GPU calls, and recompute activations on the fly instead of storing them in memory.
This allows Unsloth to deliver >2x faster training with 70% less VRAM without any accuracy loss.
The loss curves match standard training runs down to the third decimal because the math is exact, not an approximation.
All of these kernel optimizations were already available through Unsloth's Python library.
But now Unsloth Studio puts a no-code web UI on top of that same engine, and there's a lot of solid engineering packed into this.
> The inference engine has a sandboxed code execution layer where models can run Python and bash, compute results, and verify their answers before responding.
This means the model can actually execute and validate code instead of just predicting what the output should look like.
The tool calling implementation also has a self-healing mechanism. Failed calls get auto-corrected and retried, which is a practical pattern for agentic workflows.
> Unsloth's Python library already had GRPO support (the RL technique behind DeepSeek-R1), and Studio now makes this accessible through the UI.
PPO requires running a separate critic model alongside the policy model during training, and that critic is typically as large as the model being trained, effectively doubling the VRAM requirement.
GRPO eliminates the critic model entirely by generating multiple completions per prompt and computing advantages from the relative quality within that group.
This cuts VRAM by 40-60% compared to PPO. Combined with Unsloth's Triton kernels and QLoRA, training a reasoning model on an RTX 4090 or even a 3090 becomes realistic on hardware that most of us actually have.
> In most fine-tuning workflows that I have run, the training step is actually the easy part. Getting raw data into a properly formatted dataset is where the real time goes.
Unsloth Studio includes Data Recipes (built on NVIDIA's DataDesigner) that take raw PDFs/CSVs/DOCX files, and transform them into structured synthetic datasets through a visual node-based workflow, replacing the custom parsing scripts entirely.
Once training is done, models can be exported directly to GGUF, safetensors, or other formats with automatic LoRA adapter merging into base weights.
The whole system runs 100% offline with no telemetry.
$ pip install unsloth
$ unsloth studio setup
$ unsloth studio
It's still in beta, but the engineering underneath is solid. For anyone working with open-source models locally, this is one of the more complete tools available right now.
Google DeepMind dropped a paper that should scare every agent builder.
It's the first systematic framework for a threat that barely existed two years ago: adversarial content engineered to hijack AI agents browsing the web.
They call them AI Agent Traps. The paper maps six distinct attack surfaces.
1) Content Injection Traps (perception)
Invisible CSS, hidden HTML, steganographic payloads inside images. The agent parses it, humans never see it. One study showed simple HTML injections hijack web agents in up to 86% of scenarios.
2) Semantic Manipulation Traps (reasoning)
No overt commands. Just biased phrasing, framing, and contextual priming that skew the agent's synthesis. LLMs inherit human cognitive biases, and attackers can weaponize every one of them.
3) Cognitive State Traps (memory and learning)
Poison the RAG corpus. Corrupt long-term memory. One study achieved over 80% attack success with less than 0.1% poisoned data.
4) Behavioural Control Traps (action)
Jailbreaks embedded in external resources. Data exfiltration prompts hidden in emails. Sub-agent spawning that tricks an orchestrator into instantiating attacker-controlled agents inside the trusted control flow.
5) Systemic Traps (multi-agent dynamics)
This is where it gets scary. A single fake news headline could trigger a synchronized sell-off. A compositional fragment trap splits a payload across sources, so each fragment looks benign until agents aggregate them.
6) Human-in-the-Loop Traps
The agent becomes the vector. The target is you. Invisible prompt injections have already caused summarization tools to faithfully repeat ransomware commands as "fix" instructions.
The core insight is uncomfortable.
By altering the environment instead of the model, attackers weaponize the agent's own capabilities against it. Training-time defenses cannot solve an inference-time problem.
The paper closes by calling for automated red-teaming that can probe these vulnerabilities at scale. That same shift is already happening on the offense side.
Strix is an open-source project doing exactly this for web apps. AI agents that act like real hackers, running your code dynamically, finding vulnerabilities, and validating them with actual proof-of-concepts.
24k stars on GitHub. Apache 2.0 licensed.
The agents writing your code need to be tested by agents trying to break it.
I've shared the link to the paper and Strix GitHub repo in the replies
We're open-sourcing FlashKDA — our high-performance CUTLASS-based implementation of Kimi Delta Attention kernels. Achieves 1.72×–2.22× prefill speedup over the flash-linear-attention baseline on H20, and works as a drop-in backend for flash-linear-attention.
Explore on github: https://t.co/sf4UohXDWY
今天读到一篇很锋利的论文,提出了一个概念叫「LLM 谬误」。什么意思呢,你用 AI 写出了一篇漂亮的分析报告,然后潜意识里开始觉得「我确实有这个水平」。
这不是幻觉问题(输出对不对),不是自动化偏差(太信 AI),是一种更阴的东西,你因为用了 AI,开始太信自己。
论文拆解了四个机制,
1)归因模糊。你丢了一句模糊的提示词进去,AI 吐出来一段结构完整、论证清晰的内容。你改了几个词,又丢回去,它又优化了一版。几轮下来,你已经分不清哪些想法是你的、哪些是它的了。人的大脑有个毛病,倾向���从结果反推作者身份,「这个东西是在我的���话里产出的,所以是我的」。
2)流畅性幻觉。AI 输出天然就语法正确、逻辑通顺、风格统一,看着就像一个资深人士写的。问题是人脑会把「读起来顺畅」自动等价于「写的人很专业」,这是一个认知捷径,你根本不会去审视内容到底是怎么生成的,表面的流畅直接就把你骗过去了。
3)管道不透明。传统工具你好歹能看到中间步骤,Excel 公式、SQL 查询,过程是透明的。但 AI 的检索、模式匹配、综合推理全部藏在黑箱里,你只看到输入和输出两头。中间它到底做了多少活,你完全无从判断,也就没办法准确地分配功劳。
4)认知外包。推理让 AI 推,组织让 AI 组织,措辞让 AI 润色,你自己参与的认知深度越来越浅。反复外包之后,你连评估自己到底懂不懂的能力都退化了。越依赖越不自知,越不自知越高估,正反馈循环。
这四个齿轮一咬合,感知能力和实际能力之间就裂开一道缝,而且是系统性的那种。
更要命的是往上捅到了制度层面。候选人用 AI 辅助做出高质量 portfolio,面试官只看产出根本判断不了独立能力;学生用 AI 完成作业,成绩不再反映真实理解;资质认证的信号价值被稀释。
这篇论文目前还是纯概念性的,没有实验数据。但它给一个东西起了名字,一个几乎每个 AI 重度用户都隐约感觉到、但没人正式说破的东西。
说真的,值得反复问自己一个问题,离开 AI,你还���多少?
https://t.co/veBTKMlv8Y
Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000+ tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP + Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100+ files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on https://t.co/YutVbwktG0 in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: https://t.co/uvoSJKyGCY
-
🔗 API: https://t.co/EOZkbOwCN4
🔗 Tech blog: https://t.co/9wWvgIQSS3
🔗 Weights & code: https://t.co/Be0hjs2RTP
someone open-source a 1.7b parameter model that parses literally anything.
text, tables, formulas, images, and pdfs in `100+ languages.
100% open-source.
Why has scaling Diffusion Transformers with Mixture-of-Experts been so tricky for visual data?
Researchers from Fudan University, Alibaba Group's Tongyi Lab, Zhejiang University, The University of Hong Kong, and MMLab just cracked the code!
They introduce ProMoE, an MoE framework that makes vision experts smarter. It uses a two-step router to first group image parts by their function (e.g., background vs. object) and then refines these assignments based on their semantic content, ensuring each expert focuses on what it does best.
This specialized routing boosts performance significantly, outperforming state-of-the-art methods on the demanding ImageNet benchmark for diffusion models.
Routing Matters in MoE: Scaling Diffusion Transformers with Explicit Routing Guidance
Paper: https://t.co/Pz51lY1Unp
Code: https://t.co/J7HMHOA5ZS
Our report: https://t.co/IKozelW5xx
📬 #PapersAccepted by Jiqizhixin