Agents are mind-blowing.
But they don't remember things consistently.
Or when they do — it's not safe.
We built Engram.
AES-256 encrypted.
Keys stay on your device.
Zero-knowledge sync.
No cloud. No middleman.
Use it.
Your agent memory is yours.
@lmmslab
https://t.co/fQG72UC1b4
https://t.co/2btlaq1JPH
Agents are mind-blowing.
But they don't remember things consistently.
Or when they do — it's not safe.
We built Engram.
AES-256 encrypted.
Keys stay on your device.
Zero-knowledge sync.
No cloud. No middleman.
Use it.
Your agent memory is yours.
@lmmslab
https://t.co/fQG72UC1b4
https://t.co/2btlaq1JPH
🥳Year-End Reflection on the Growth of LMMs-Lab🥳
2025 has been a fruitful year for 🧠LMMs-Lab🧠 @lmmslab (https://t.co/QpJXVu7EWo), a non-profit open-source research organization dedicated to feeling and building the future of multimodal intelligence with:
🌟 > 12,000 Total GitHub Stars
🍴 > 2,000 Forks
🧑💻 > 30 Core Repositories
🔥LLaVA-OneVision upgraded to V1.5🔥
We @lmmslab present 🌋LLaVA-OV-1.5🌋, a fully open framework for democratized multimodal training
* Superior Performance surpassing Qwen2.5-VL
* High-Quality Data at Scale
* Ultra-Efficient Training Framework
- Repo: https://t.co/1Mm6Mq5jqR
@gazorp5@liuziwei7@Gradio@_akhaliq Yes we plan to release our tech report and propose a plug-play method without re-train the model to directly generate SRT output.
VideoMMMU is a meticulously crafted benchmark designed to evaluate multimodal models’ video understanding abilities for college-level videos.
Videos have tremendous knowledge and learning from them remains challenging for current models, but it is expected to become a crucial capability on the path toward achieving AGI.
🤖Interpreting Large Multimodal Models (LMM)🤖
We present an automatic framework to identify, interpret and steer neurons within LMM for safe AGI
- Paper: https://t.co/YIyk06DuK0
- Code: https://t.co/Z6FexYSxOF
- Model @huggingface : https://t.co/yh5iH8WqBY . Thanks @_akhaliq !
TL;DR
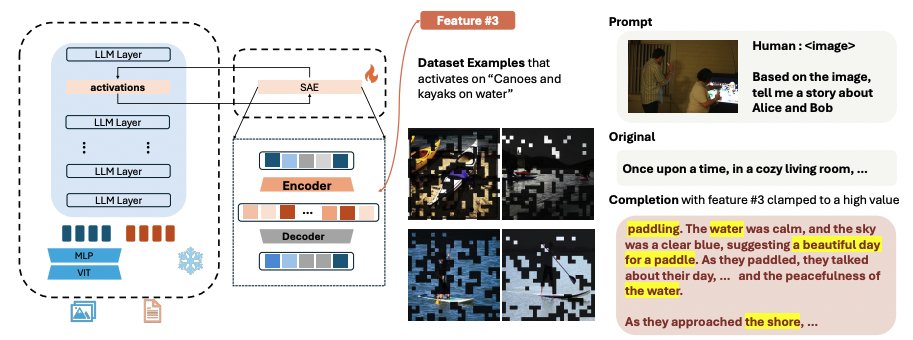
We present Large Multi-modal Models Can Interpret Features in Large Multi-modal Models
We successfully use a 72B large model to interpret the open-semantic features of an 8B small model, uncovering numerous important thought patterns inside multimodal models.
Paper: https://t.co/iZmMq0vrcr
Code: https://t.co/cxbWhlYbRt
Examples: https://t.co/DcwtaI03TG
🔥 We just submitted some baselines and benchmarks to lmms-eval @lmmslab (LLaVA team) — evaluation is now just one line of code away! We call for the reporting of visual token numbers when evaluating LMM performance!
- lmms-eval repo: https://t.co/RZrAJMqyTA
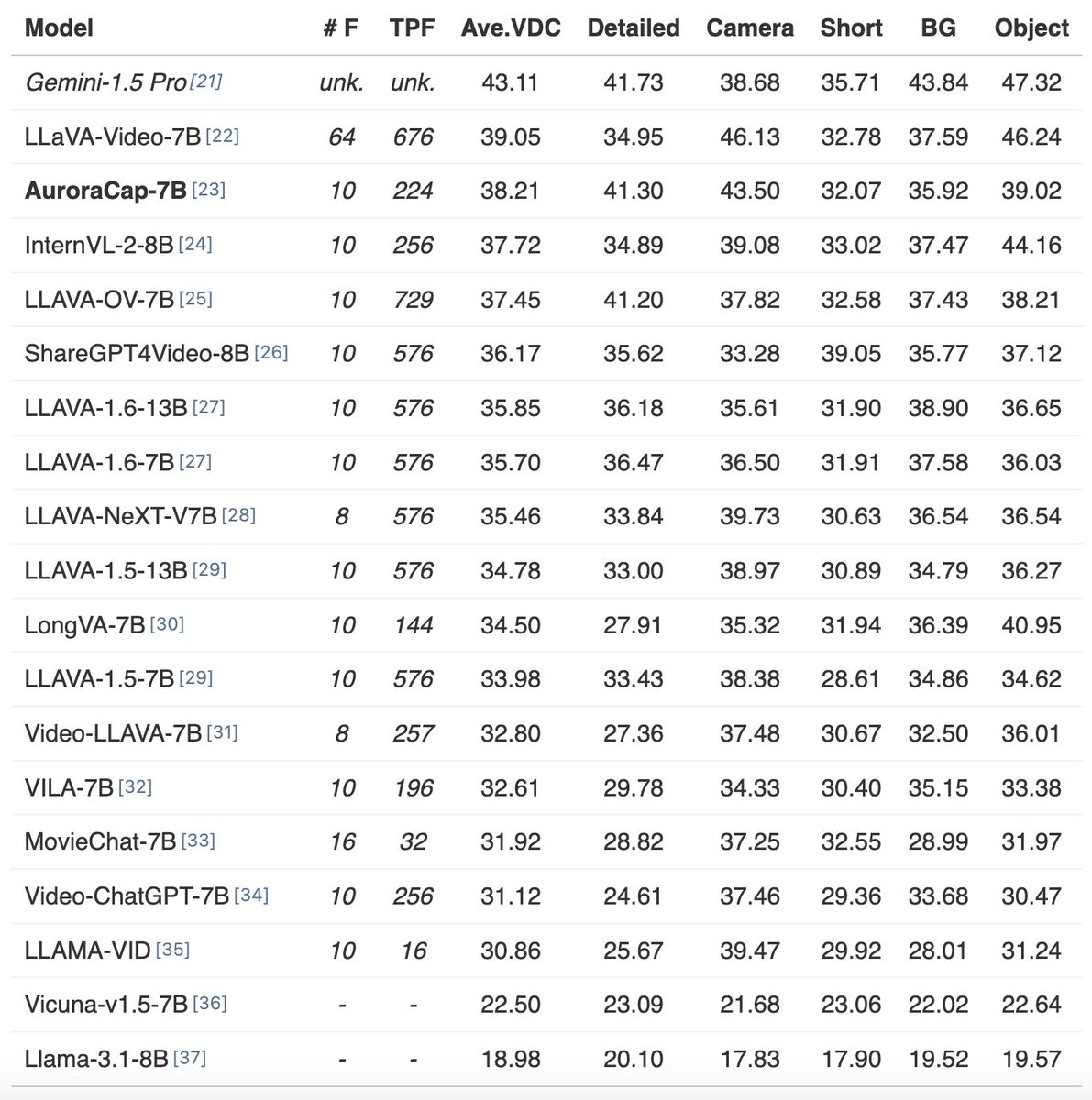
- VDC, first benchmark for detailed video captions: https://t.co/FxyH8i4rAc
- AuroraCap (VDC baseline): https://t.co/QRItwb31ti
- MovieChat, first long-video understanding benchmark: https://t.co/tlElVqVeFg
- MovieChat baseline: https://t.co/Fus36O252j
🚀🔥Introducing LLaVA-Critic--the first open-source large multimodal model designed to assess model performance across diverse multimodal tasks!
LLaVA-Critic excels in two primary scenarios:
- 👨⚖️LMM-as-a-Judge: It provides pointwise scores and pairwise rankings that closely align with human and GPT-4o preferences across multiple evaluation tasks, offering a viable open-source alternative to commercial GPT models.
- 🩷Preference Learning: It offers reliable reward signals that significantly enhance the visual chat capabilities of LMMs through preference alignment.
To develop the "critic" capacity, we curate LLaVA-Critic-113k, a high-quality critic instruction-following dataset tailored to provide quantitative judgment and the corresponding reasoning process across a range of complex evaluation settings.
Explore more:
- 📰Paper: https://t.co/N71QwFSr7D
- 🪐Project Page: https://t.co/qWLoZ0fX9J
- 📦Dataset: https://t.co/t0RXNEC3Q6
- 🤗Models: https://t.co/V0zZHdLi0J
Try our released models and dataset👆
(1/4)🚀 Ready to supercharge your Video LLMs? 🎥Meet LLaVA-Video-178K, a high-quality dataset for video instruction tuning with 1.3M samples in captions, Q&A!
💡Perfect for further boosting Video LLMs, on top of strong capability transfer from image/language shown in LLaVA-OV🤖
We are organizing a new workshop on "Knowledge in Generative Models" at #ECCV2024 to explore how generative models learn representations of the visual world and how we can use them for downstream applications.
https://t.co/6iW8lcdrZt
📅30 September 2024, 2 PM
Great experience working with Lianmin to integrate LLaAV-OneVision into SGLang, and huge thanks to @PY_Z001 and @KaichenZhang358 to help finish this.
Try it on: https://t.co/1xhUxNw0Oc
Directly try our demo (with SGLang SRT API service):
https://t.co/yAav2XwrAe