Meet Ambuj-Tripathi-Indian-Legal-Llama-GGUF: a specialized AI model fine-tuned for Indian law. This isn't just another chatbot. It's a legal assistant trained to understand the nuances of Indian statutes, case law, and legal language. A game-changer for legal tech in India.
This 2-hour lecture by Andrej Karpathy - co-founder of OpenAI, the man who coined "vibe coding" - will build GPT from scratch and show you exactly why message 30 costs you 31x more than message 1.
Bookmark this & give it 2 hours today, no matter what. It's the best thing you can do for your Claude budget. Then read the article below.
After this, you'll never pay for tokens Claude spends talking to itself again.
bro created an AI job search system for Claude Code that scored 700+ job applications and actually got him a job.
AND IT'S NOW OPEN-SOURCE.
It scans multiple company career pages, rewrites your CV per job, and even fills application forms. The repo has:
> 14 skill modes (evaluate, scan, PDF, ...)
> Go terminal dashboard
> ATS-optimized PDF generation via Playwright
> 45+ companies pre-configured (Anthropic, OpenAI, ElevenLabs, Stripe...)
GitHub: https://t.co/PwrYBOAphi
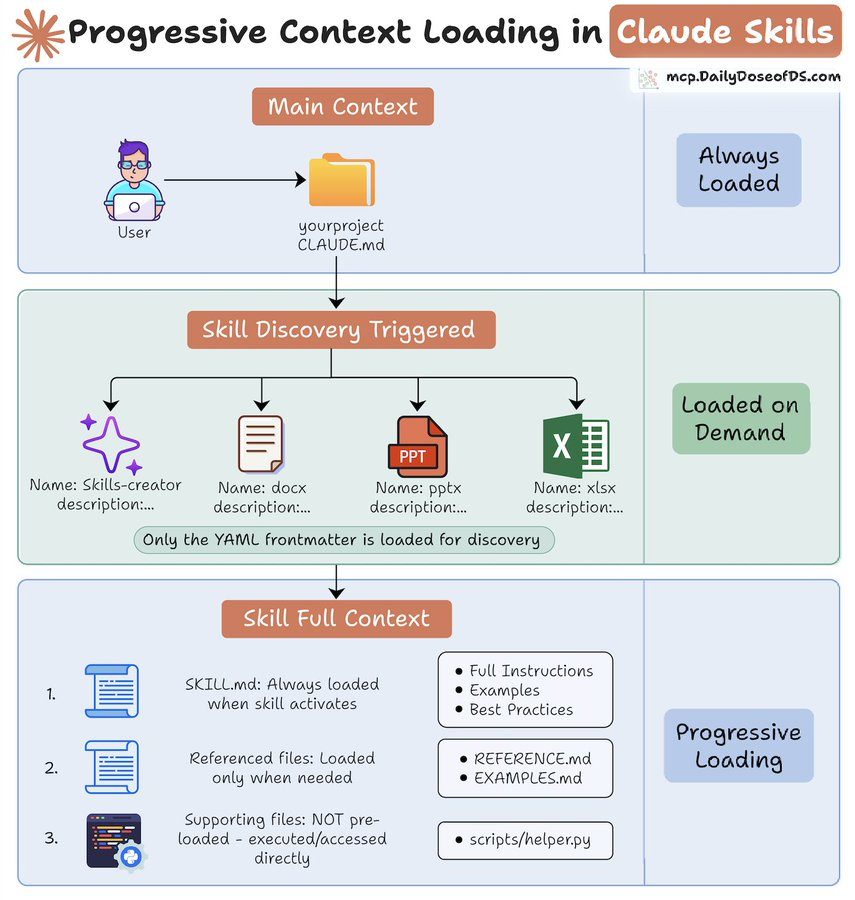
Context engineering in Claude Skills is GENIUS!
Skills use a 3-layer context management system that lets it use 100s of skills without hitting context limits.
Here's how it works:
> Layer 1: Main Context - Always loaded, it contains the project configuration.
> Layer 2: Skill Metadata - Comprises only the YAML frontmatter, about 2-3 lines (< 200 tokens).
> Layer 3: Active Skill Context - SKILL. md files and associated documentation are loaded as needed.
Supporting files like scripts and templates aren't pre-loaded but accessed directly when in use, consuming zero tokens.
This architecture supports hundreds of skills without breaching context limits.
The article below is a complete guide to 𝗖𝗟𝗔𝗨𝗗𝗘.𝗺𝗱, hooks, skills, agents, and permissions, and how to set them up properly.
The fastest growing GitHub repos this week:
1. microsoft/VibeVoice (+11.1K stars)
Open-source frontier voice AI. Clone voices, transcribe 60min audio in one pass.
2. bytedance/deer-flow (+9.0K stars)
ByteDance's open-source SuperAgent. Researches, codes, creates on its own.
3. NousResearch/hermes-agent (+8.8K stars)
The agent that grows with you. Self-evolving memory.
4. mvanhorn/last30days-skill (+8.6K stars)
AI agent skill that researches any topic across Reddit, X, YouTube, HN, Polymarket.
5. hacksider/Deep-Live-Cam (+7.3K stars)
Real-time face swap with a single image.
6. TauricResearch/TradingAgents (+3.9K stars)
Multi-agent LLM trading framework. Because one agent wasn't scary enough.
7. hesreallyhim/awesome-claude-code (+3.2K stars)
Curated skills, hooks, and plugins for Claude Code.
8. google-research/timesfm (+2.8K stars)
Google's time-series foundation model. Zero-shot forecasting.
9. datalab-to/chandra (+2.4K stars)
OCR model for complex tables, forms, and handwriting.
10. SakanaAI/AI-Scientist-v2 (+2.0K stars)
Automated scientific discovery via agentic tree search.
The theme this week: voice AI and self-evolving agents dominated.
Bookmark this. Next week's list will look completely different.
Building a personal knowledge base for my agents is increasingly where I spend my time these days.
Like @karpathy, I also use Obsidian for my MD vaults.
What's different in my approach is that I curate research papers on a daily basis and have actually tuned a Skill for months to find high-signal, relevant papers.
I was reviewing and curating papers manually for some time, but now it's all automated as it has gotten so good at capturing what I consider the best of the best. There are so many papers these days, so this is a big deal.
You all get to benefit from that with the papers I feature in my timeline and on @dair_ai.
The papers are indexed using @tobi qmd cli tool (all of it in markdown files along with useful metadata). So good for semantic search and surfacing insights, unlike anything out there.
I am a visual person, so I then started to experiment with how to leverage this personal knowledge base of research papers inside my new interactive artifact generator (mcp tools inside my agent orchestrator system). The result is what you see in the clip.
100s of papers with all sorts of insights visualized. I keep track of research papers daily, so believe me when I tell you that this system is absolutely insane at surfacing insights. This is the result of months of tinkering on how to index research and leverage agent automations for wikification and robust documentation.
But this is just the beginning. The visual artifact (which is interactive too) can be changed dynamically as I please. I can prompt my agent to throw any data at it. I can add different views to the data. Different interactions. I feel like this is the most personalized research system I have ever built and used, and it's not even close.
The knowledge that the agents are able to surface from this basic setup is already extremely useful as I experiment with new agentic engineering concepts. I feel like this knowledge layer and the higher-level ones I am working on will allow me to maximize other automation tools like autoresearch. The research is only as good as the research questions. And the research questions are only as good as the insights the agents have access to.
Where I am spending time now is on how to make this more actionable. I am obsessed about the search problem here. The automations, autoresearch, ralph research loop (I built one months ago) are easier to build but are only as good as what you feed them.
Work in progress. More updates soon. Back to building.
Gemma 4 31B running with TurboQuant KV cache on MLX 🔥
128K context:
→ KV Memory: 13.3 GB → 4.9 GB (63% reduction)
→ Peak Memory: 75.2 GB → 65.8 GB (-9.4 GB)
→ Quality preserved
TurboQuant compression scales with sequence length, so the longer the context, the bigger the savings!
Try it out:
> uv run mlx_vlm.generate –model google/gemma-4-31b-it –kv-bits 3.5 –kv-quant-scheme turboquant
Note: Decode speed drops (~1.5x) due to kernel launch overheads, we are aware and will fix in coming releases.
Meet Gemma 4!
Purpose-built for advanced reasoning and agentic workflows on the hardware you own, and released under an Apache 2.0 license.
We listened to invaluable community feedback in developing these models. Here is what makes Gemma 4 our most capable open models yet: 👇
Thanks for following us!
We're excited to see what you all build with Gemma 4!
In case you missed it, you can find all our checkpoints, with an Apache 2.0 License, on Hugging Face:
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
@Wooden_street You're such a fraud company, fooling customers and trapping them into buying your products and then misguiding them that there product will be delivered. The customer care is a scam and the local store is for trapping. Order ID 1113531