One session ends → poof. Everything important disappears.
A teammate cracks a brutal prod issue → it dies in their terminal forever.
Next week you’re debugging the exact same damn problem for the third time.
We were so done with it.
So we built Hivemind. A shared memory layer that connects Claude Code, Codex, and OpenClaw across sessions and across the entire team.
Tag the teammate who keeps debugging the same bug twice 😂
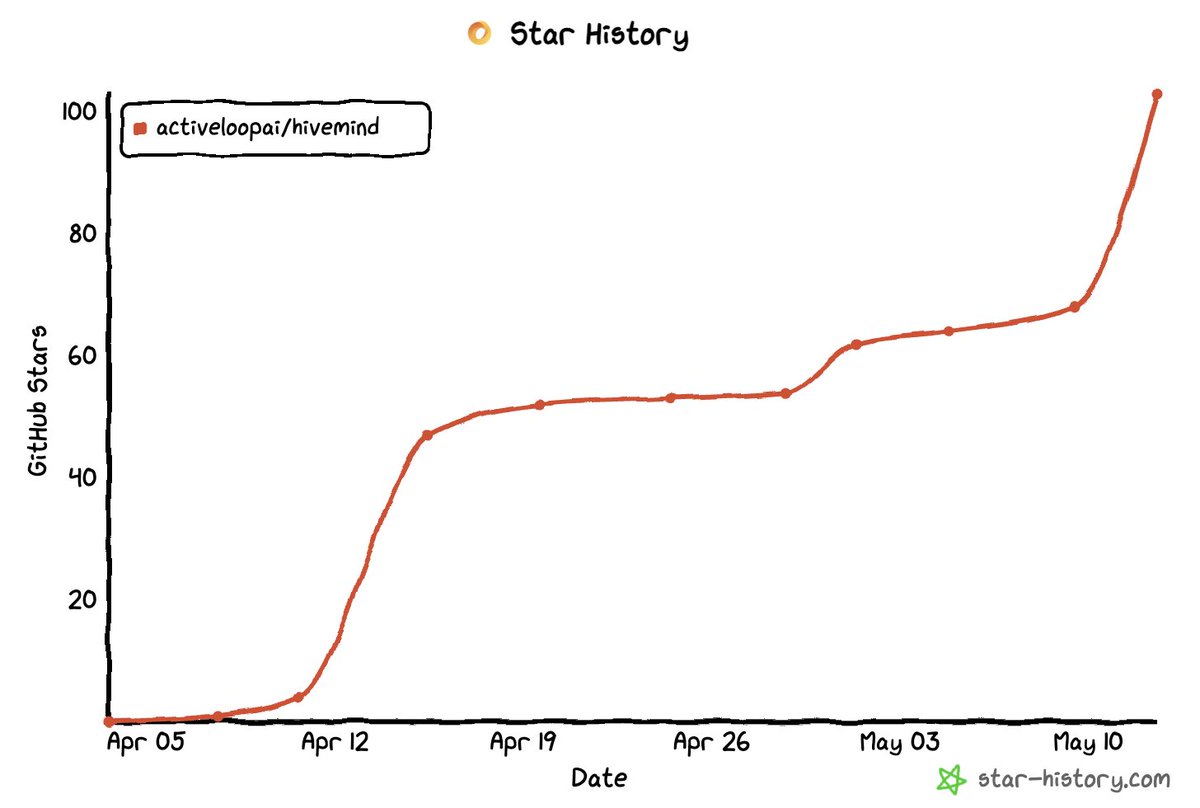
Hivemind just crossed 250 stars on github
2K weekly downloads on NPM. 🚀
Connect coding agents to a shared brain
> Collect traces into deeplake
> Auto-optimize skills
> Share across agents, machines and teammates
Your agents continuously learn from each other's experience.
Get them to compound your intelligence.
Mentioned this for MSFT as well; this is one of the exact problems that our Hivemind plugin was built to solve for Claude Code, but also for Codex and Cursor too.
It prevents duplicate work, creating slash command skills from agent traces so the entire team at a company can benefit from prior work.
True continued learning that reduces costs and increases speed of development.
Open source. Check it out at https://t.co/xfX8LH9gUO
This is one of the exact problems that our Hivemind plugin was built to solve for Claude Code, but also for Codex and Cursor too.
It prevents duplicate work, creating slash command skills from agent traces so the entire team at a company can benefit from prior work.
True continued learning that reduces costs and increases speed of development.
BREAKING: MICROSOFT JUST ANNOUNCED TO BAN ITS OWN ENGINEERS FROM USING AI DUE TO THE COST OF USING IT.
VP OF NVIDIA SAID, “THE COST OF AI FOR MY TEAM WAS MORE THAN HUMANS”
“AI CAN COST MORE THAN HUMAN WORKERS NOW”
This is one of the exact problems that our Hivemind plugin was built to solve for Claude Code, but also for Codex and Cursor too.
It prevents duplicate work, creating slash command skills from agent traces so the entire team at a company can benefit from prior work.
True continued learning that reduces costs and increases speed of development.
Open source. Check it out at https://t.co/xfX8LH9gUO
today, we're going beyond memory.
your org's agents shouldn't just remember what happened. they should learn from their experience.
Hivemind takes agent traces and codifies them into skills every agent on your team can use.
> no more explanations
> no more duplicate work
> no more repeat bugs
we make your intelligence compound.
here's how 👇
Engineering managers shouldn’t have to play detective every morning.
But too often, that’s the job:
standups get skipped
tickets stay stale
and status updates become a scavenger hunt.
What if your tools just told you what changed?
An AI layer across Claude Code, Codex, and OpenClaw could surface progress, blockers, and momentum automatically.
No nagging required.
You get your mornings back.
Engineers feel less monitored.
Everyone stays in sync.
Engineering managers shouldn’t have to play detective every morning.
But too often, that’s the job:
standups get skipped
tickets stay stale
and status updates become a scavenger hunt.
What if your tools just told you what changed?
An AI layer across Claude Code, Codex, and OpenClaw could surface progress, blockers, and momentum automatically.
No nagging required.
You get your mornings back.
Engineers feel less monitored.
Everyone stays in sync.
YOU LITERALLY JUST RUN 4 COMMANDS TO INSTALL HIVEMIND SO CLAUDE STOPS GETTING AMNESIA EVERY TIME THE TERMINAL CLOSES.
AND IT'S FREE & OPEN-SOURCE!
NOW GO BUILD!
One session ends → poof. Everything important disappears.
A teammate cracks a brutal prod issue → it dies in their terminal forever.
Next week you’re debugging the exact same damn problem for the third time.
We were so done with it.
So we built Hivemind. A shared memory layer that connects Claude Code, Codex, and OpenClaw across sessions and across the entire team.
Tag the teammate who keeps debugging the same bug twice 😂
Jack's right: "Companies move fast or slow based on information flow." But framing it as a worker hierarchy problem is losing the plot.
Look at where the actual work is moving: agents.
Quick history:
Email got messy. Slack fixed it.
Then humans kept dropping balls anyway. Someone's offline, a thread dies, marketing has no idea what eng shipped, the handoff never happens.
And now Slack itself is the slog. What if you could spend a fraction of the time in it?
Meanwhile, your agents are in the pre-Slack era:
• Your Claude Code agent has no clue what your coworker's OpenClaw agent decided yesterday.
• Marketing's agent can't see what sales's agent promised the customer.
• Product's agent has no idea what engineering's agent already shipped.
Same company, same project, totally separate brains. The fastest workers on your team are stuck on the slowest part of your stack.
Deeplake Hivemind fixes it. One install and your agents share memory across sessions, across teammates, across tools: Claude Code, OpenClaw, Codex, whatever.
When one agent learns something, every agent on your team knows.
No Slack pings. No status updates. No "wait, did you tell the VP?"
Just shared context, flowing automatically.
Slack was for humans. Hivemind is for the things actually doing the work now.
Comment HIVEMIND and we'll DM you $100 in free credits. Run the experiment with your crew.
Here is a banger article on how to make Postgres serverless for AI Agents.
The rules:
- spin up per request
- scale reads and writes
- drop to zero when idle
- no state tied to machines
- keep Postgres, rethink storage engine
What we got:
~14s cold start → ~1s
Databases in ~200ms
Stateless pods,
infinite horizontal scale
Postgres is the interface.
Deeplake is storage.
DuckDB is execution.
The system looks simple in hindsight.
But every piece breaks a default assumption.
This might be the simplest way to run databases for agents:
Make compute ephemeral. Make storage immutable. Let scaling be automatic.
Here’s how we built it. Link below
A banger post by our CTO @khustup on how he made Postgres Serverles and spin up under second.
We built a serverless, PostgreSQL-compatible database. Not a modified PostgreSQL deployment.
PostgreSQL provides the interface. DuckDB provides the query execution. Deeplake provides the storage engine.
The architecture makes a different set of tradeoffs than traditional PostgreSQL.
We think those tradeoffs are right for agent workloads: bursty, ephemeral, storage-heavy, and analytical.
Link: https://t.co/7GaOJoO4Pv
Robots have been stuck reacting.
Not understanding the real world.
That’s the bottleneck in last-mile delivery.
We combined Deeplake GPU database with Intel Core Ultra to power real-time VLA perception.
Result: 9x higher throughput.
Robots that don’t just see, but act intelligently.
Physical AI just crossed a threshold.
The path to solving last-mile delivery is built on real-time perception. With #IntelCoreUltra Series 3 processors and @activeloop’s Deep Lake GPU database, Pinkbot increased VLA throughput by 9x and improved delivery outcomes. Learn more about Intel Core Ultra Series 3 at https://t.co/FPsd9unN1c