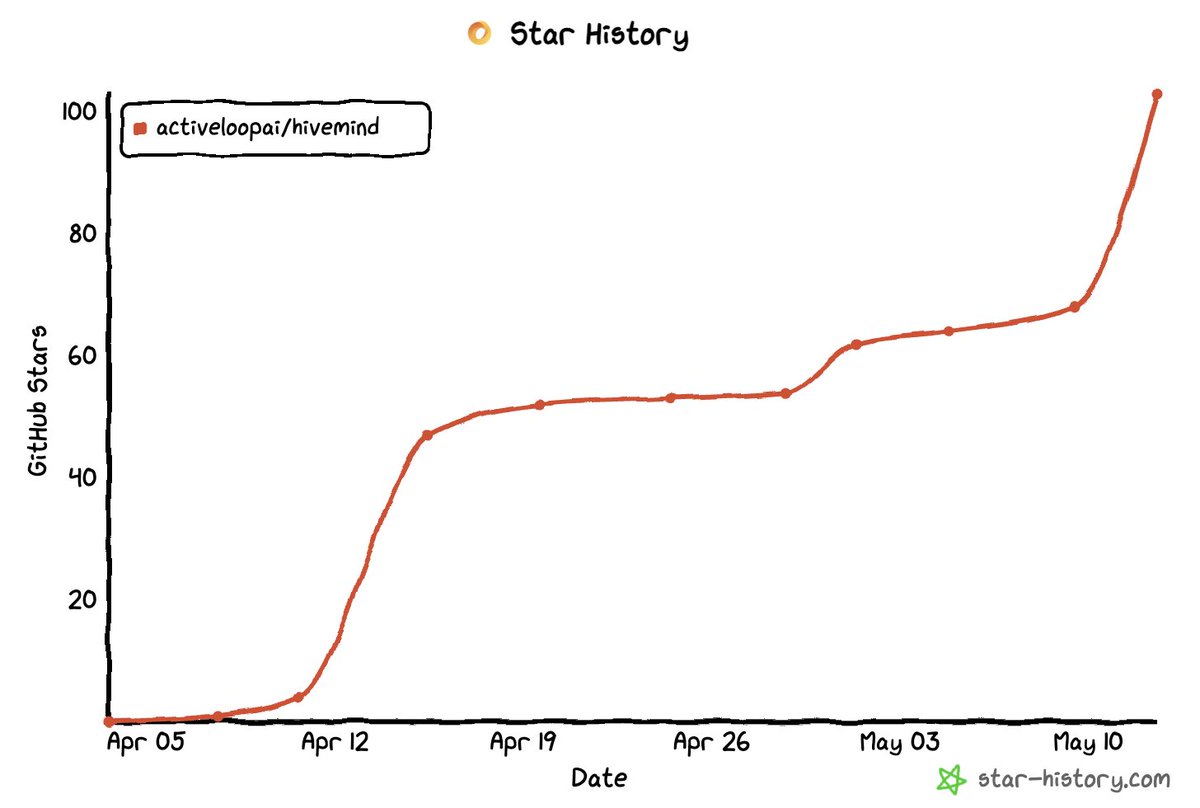
Hivemind just crossed 250 stars on github
2K weekly downloads on NPM. 🚀
Connect coding agents to a shared brain
> Collect traces into deeplake
> Auto-optimize skills
> Share across agents, machines and teammates
Your agents continuously learn from each other's experience.
Get them to compound your intelligence.
In April, we started Hivemind as a use case for Deeplake. A month later, it turned out that Deeplake is actually a use case for Hivemind 😁
Our development process leveled up dramatically. By sharing experience across different sessions, engineers, and agents through a single plugin installation, the system continuously improves itself. It works seamlessly: install the plugin once, and you’ll notice the difference after just one session.
today, we're going beyond memory.
your org's agents shouldn't just remember what happened. they should learn from their experience.
Hivemind takes agent traces and codifies them into skills every agent on your team can use.
> no more explanations
> no more duplicate work
> no more repeat bugs
we make your intelligence compound.
here's how 👇
My recent thoughts on how AI will reshape collaborative work led me to this conclusion:
The bottleneck is no longer the number of people in a company, but the number of productive experiments the company can run in parallel.
In the AI era, work shouldn’t stop between humans. Sessions with tools like Claude Code should be continuous.
A key requirement for this to work is strong information and experience sharing across team members.
Jack's right: "Companies move fast or slow based on information flow." But framing it as a worker hierarchy problem is losing the plot.
Look at where the actual work is moving: agents.
Quick history:
Email got messy. Slack fixed it.
Then humans kept dropping balls anyway. Someone's offline, a thread dies, marketing has no idea what eng shipped, the handoff never happens.
And now Slack itself is the slog. What if you could spend a fraction of the time in it?
Meanwhile, your agents are in the pre-Slack era:
• Your Claude Code agent has no clue what your coworker's OpenClaw agent decided yesterday.
• Marketing's agent can't see what sales's agent promised the customer.
• Product's agent has no idea what engineering's agent already shipped.
Same company, same project, totally separate brains. The fastest workers on your team are stuck on the slowest part of your stack.
Deeplake Hivemind fixes it. One install and your agents share memory across sessions, across teammates, across tools: Claude Code, OpenClaw, Codex, whatever.
When one agent learns something, every agent on your team knows.
No Slack pings. No status updates. No "wait, did you tell the VP?"
Just shared context, flowing automatically.
Slack was for humans. Hivemind is for the things actually doing the work now.
Comment HIVEMIND and we'll DM you $100 in free credits. Run the experiment with your crew.
We published a deep dive into our serverless postgres architecture, including some non-trivial architectural decisions we had to make along the way.
Would really appreciate feedback from others working on similar problems or operating systems at scale.
A banger post by our CTO @khustup on how he made Postgres Serverles and spin up under second.
We built a serverless, PostgreSQL-compatible database. Not a modified PostgreSQL deployment.
PostgreSQL provides the interface. DuckDB provides the query execution. Deeplake provides the storage engine.
The architecture makes a different set of tradeoffs than traditional PostgreSQL.
We think those tradeoffs are right for agent workloads: bursty, ephemeral, storage-heavy, and analytical.
Link: https://t.co/7GaOJoO4Pv
Jensen just announced the start of the GPU-accelerated database era at #GTC26.
AI runs on GPUs. But your data still runs on CPUs.
That mismatch is breaking the AI stack.
For the last two months, we’ve been busy solving this problem.
Excited to announce Deeplake becoming the GPU Database.
Deeplake brings your database directly onto the GPU, eliminating the CPU <-> GPU bottleneck for AI workloads.
The pendulum has switched.
GPU-native queries are now 10× faster and an order of magnitude cheaper to run.
Last week we even put up a 101 banner in San Francisco.
And this is just the beginning.
We’re planning a huge set of announcements starting this week. Stay tuned.
@DBuniatyan didn’t even work on our C++ core.
Still, with the right harness + agents, he ran an autonomous workflow for 15h and shipped a 2× TPC-H speedup to production.
Feels like engineering is becoming systems + feedback loops, not typing.
Was at the Physical AI Hack in SF today. Absurd talent density with hundreds of people. Every team gets an assigned robot. Energy is off the charts. 🤖🔥
Proud to sponsor with @activeloop and enable teams building on multimodal AI with Deep Lake. So much data to capture.
@activeloop and Pinkbot achieved 9× faster VLM reasoning throughput with @intel newest chips, unveiled at #CES2026.
As Physical AI takes on increasingly complex tasks, vision-language models enable robots not just to see, but to perceive and reason.
While perception now runs in near real time, VLM reasoning operates on a longer horizon, giving delivery robots the context needed for higher-stakes decisions such as when to cross the street.
At @activeloop we were among the first partners to run on Intel Corporation Panther Lake.
Intel's Panther Lake combined with Activeloop's Deep Lake multimodal storage enables fast perception with deep reasoning, making VLM-driven intelligence practical for last-mile robots.
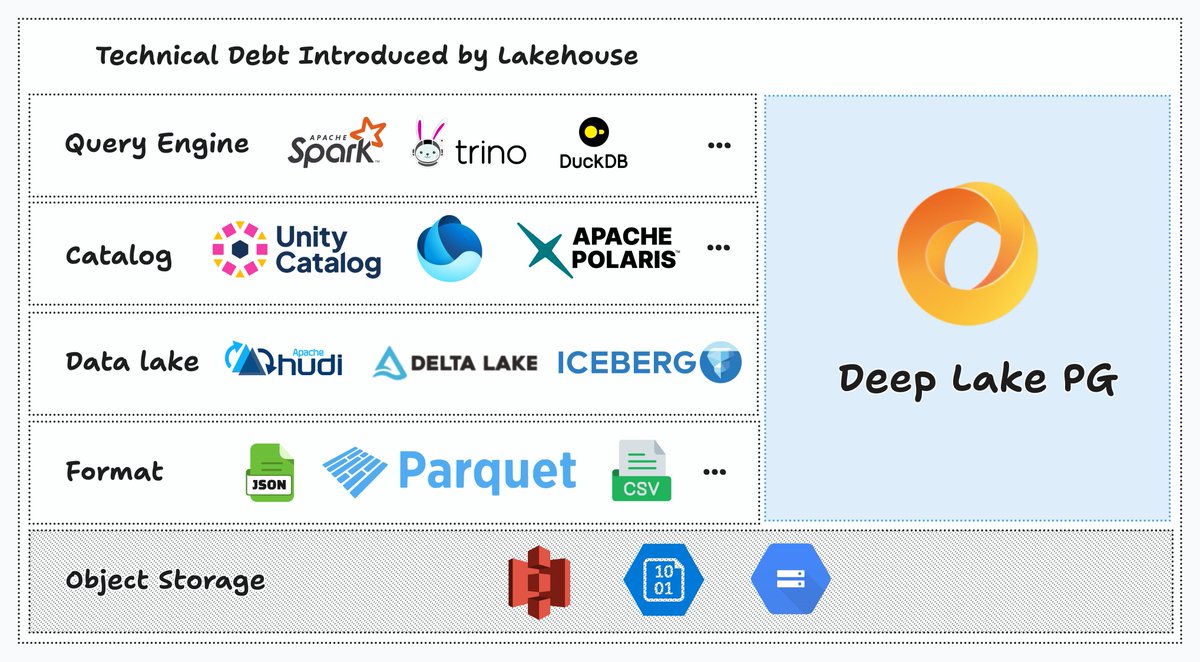
Today excited to open-source Deep Lake PG = Postgres + Deep Lake
Biggest bottleneck of AI having impact on GDP is unlocking data in Enterprises.
Every AI team I know is stitching Postgres → Vector DB → Warehouse → Lakehouse → Catalog.
All to give their agents basic memory and reasoning.
We replaced the entire data ecosystem with one database.
Deep Lake PG is now open source.
Stateless + multimodal knowledge + SQL queries + vectors in a single place.
Build on top of the database that powers our own Scientific Agent, a trove of 175TB+ of multimodal data.
The Genesis Mission calls for new ways to accelerate scientific discovery.
This is our contribution
Multimodal search across 25M papers is a step toward science discovery that moves at the speed of curiosity.
Releasing,
- Visually indexed scientific paper dataset with open access 25M papers, 450M+ visually indexed pages. Total 175TB+. All on Deep Lake
- Open-source scientific data agent that achieves 48% SOTA on Humanity's Last Exam with tools including the indexed scientific research dataset.
Excited to see what discoveries you all uncover with this.
Try it and share your most interesting findings.
Our recent collaboration with AWS as part of the SageMaker Incubator program focused on bridging multimodal scientific data for drug discovery using Activeloop Deep Lake.
https://t.co/XeVglVKdaS
Spoke to dozens of GTM leaders at large enterprises. All are frustrated by the same thing: their data is everywhere, but insights are nowhere.
At Activeloop today, we are unlocking AI Data Analysis form data silos towards Vibing intelligence.
Proud to announce the launch of Activeloop AI Analyst. Our engineering team created a system that stops the silo shuffle by reasoning across CRMs, ERPs, docs and meetings giving you just-in-time intelligence.
Your GTM ops team wastes 70% of its time on manual data prep. It’s time to fix it. The endless cycle of manual data preparation, integration, and reconciliation.
We’re introducing Activeloop to unlock AI Data Analysis for GTM Operations.