All materials of @berkeley_ai Deep Unsupervised Learning now up:
https://t.co/pzJQptPAdN
Great semester w/@peterxichen,@Aravind7694,@hojonathanho, and guest inst. @AlecRad,@ilyasut,A Efros,@avdnoord
Covers: AR / PixelCNN, Flow models, VAE, GAN, self-supervised learning, etc...
@ankesh_anand@egrefen@ylecun I posted the slides for my model-based RL tutorial today here: https://t.co/YskkYXYWqK
Content is similar to the DRL bootcamp video 1 yr ago, but updated.
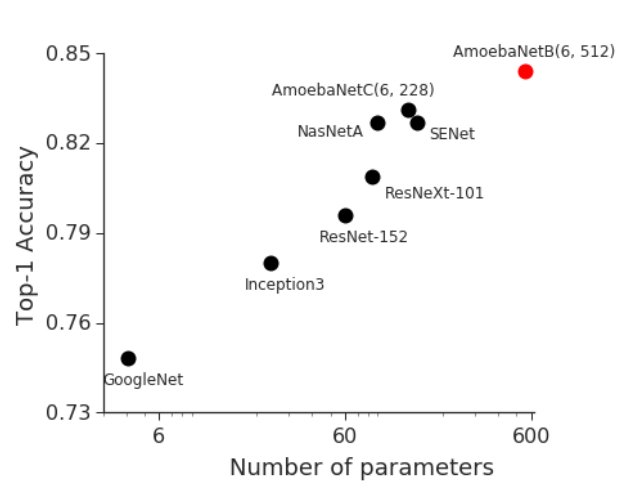
Bigger models are better models so we built GPipe to enable training of large models. Results: 84.3% on ImageNet with AmoebaNet (big jump from other state-of-art models) and 99% on CIFAR-10 with transfer learning. Link: https://t.co/SE7Dz2cA0g
WaveGlow: A non-autoregressive generative model for speech synthesis. Our unoptimized @PyTorch inverts mel-spectrograms at 500 kHz on a V100 GPU, and is easy to train. Paper: https://t.co/E4t6avhlar Samples: https://t.co/lriR2xv3G4 Work with @DeepPrenger and @RafaelValleArt
@MelMitchell1 So, something is surely missing; I don't know what it is; but supervised learning might be a huge part of finding it. Hence, it continues to be underestimated, even by me. 😅
It turns out that DL's ability to make great predictions of just about anything is a still underestimated superpower. "Curve fitting" is doing some nifty things these days. 👇👇👇
An agent which learned to play Mario without rewards. Instead, it was incentivized to avoid "boredom" (that is, getting into states where it can predict what will happen next). Discovered warp levels, how to defeat bosses, etc. More details: https://t.co/lGw3rZUbv3
@MelMitchell1 IMO, the lesson of DL is that we're not as clever as we think. Somehow, machines need to build the ultimate solution. Today, "supervised learning" (as a subroutine for RL, unsupervised, or meta-learning) is one heckuva tool to find solutions we could never imagine.
I have put together some thoughts about the article here: https://t.co/m1HGFQZdMj. I am concerned that the story in the Economist not only displaces my own narrative but also sets unrealistic expectations for anyone setting out in the field.
Our field needs more diversity. There must be more people like me who feel welcome and who are given the tools to succeed. However, part of preparing people to succeed is to be candid about how challenging it can be and how many failures there are along the way.
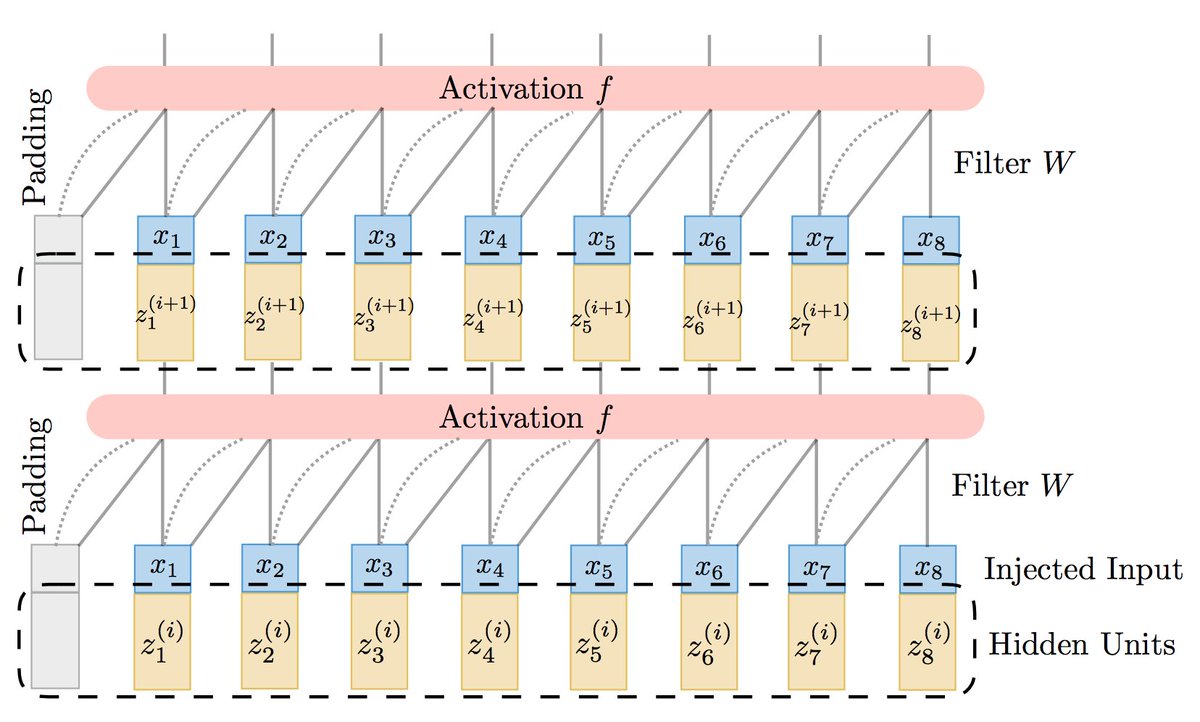
Got the "do I use an RNN or CNN for sequence modeling" blues? Use a TrellisNet, an architecture that connects these two worlds, and works better than either! New paper with @shaojieb and Vladlen Koltun.
Paper: https://t.co/PUEd2ZiFbh
Code: https://t.co/b9HUBt3JhE
I've spent most of 2018 training models that could barely fit 1-4 samples/GPU.
But SGD usually needs more than few samples/batch for decent results.
I wrote a post gathering practical tips I use, from simple tricks to multi-GPU code & distributed setups: https://t.co/oLe6JlxcVw
This is one of the things about bias in ML that I fear the most. Many companies will build these systems innocently and have *no idea* that the algorithm has found a way to discriminate unfairly. *Everyone* in company has to stay vigilant, not just ML team.
This is being reported as a problem with machine learning, but there's another way of looking at it: The algorithm exposed bias in their *existing* hiring practices