🪜 What if humanoids could climb ladders and work on them straight out of simulation?
Meet LadderMan: a perceptive system for zero-shot sim-to-real ladder climbing and on-ladder manipulation.
Watch the humanoid climb, stabilize, and manipulate—all in one system. 🤖👇
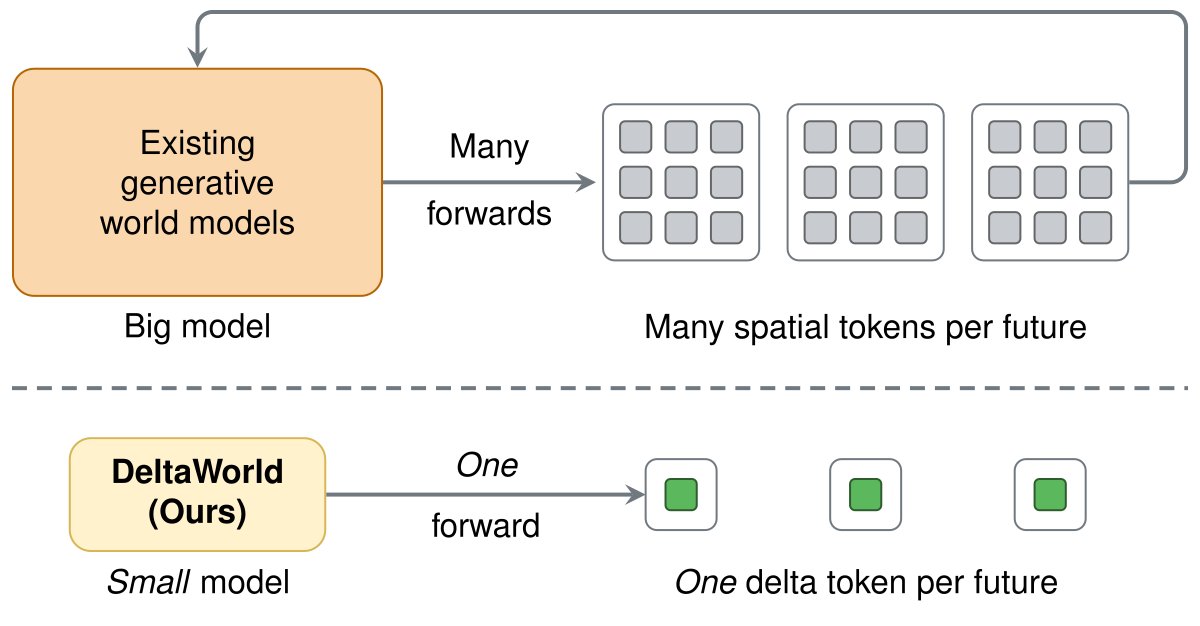
World models are heavy. They don't need to be.
Each frame is encoded as 1024 spatial tokens. What if it were just 1?
In our #CVPR2026 Highlight from Amazon FAR, we compress frames into "delta" tokens for efficient generative world modeling.
Paper, code & models below ↓
(1/7)
🤖We are hiring multiple Summer'26 Research Interns at @amazon FAR to work on open-world navigation and robot foundation models, especially in neural rendering & simulation/predictive world models/reasoning & agency/real-world evaluation/long-term autonomy!
Can humanoids perform agile, autonomous, long-horizon parkour—based on what they see in the world?
We present 𝗣𝗲𝗿𝗰𝗲𝗽𝘁𝗶𝘃𝗲 𝗛𝘂𝗺𝗮𝗻𝗼𝗶𝗱 𝗣𝗮𝗿𝗸𝗼𝘂𝗿 (𝗣𝗛𝗣): a framework that chains dynamic human skills using onboard depth perception for long-horizon traversal.
1/6
New project! Flow Policy Gradients for Robot Control
tldr; a simple online RL recipe for training and fine-tuning flow policies for robots
co-led w/ @redstone_hong: https://t.co/nKSq9EakUy
We introduce a framework that enables robust, long-horizon bi-directional locomotion over complex terrains, by effectively leveraging a single policy with dual-depth camera streams, without the need for LiDAR-based elevation maps.
Check out @Yuanhang__Zhang's tweet for architecture and implementation details, and the website for full, uncut rollouts.
Robust humanoid perceptive locomotion is still underexplored. Especially when different cameras see different terrains, paths get narrow, and payloads disturb balance...
Introduce RPL, tackling this with one unified policy:
• Challenging terrains (slopes, stairs and stepping stones);
• Multiple directions;
• Payloads;
Trained in sim. Validated long-horizon in the real world.
Watch the robot walk it all🦿
Details below👇
Tired of waiting hours for humanoids to learn to walk?
Our new technical report shows how to train sim-to-real humanoid locomotion in 15 minutes with FastSAC and FastTD3! The full pipeline is open-source in the newly released Holosoma codebase.
Thread 🧵
Excited to share this latest work from our team! Holosoma is now our go-to option for humanoid research at FAR, and we will continue to maintain it and add new capabilities in the future. We're also hiring!
Research: https://t.co/Aq4wt6lpKK
Software: https://t.co/LSwSfLSsFF
Sim-to-real learning for humanoid robots is a full-stack problem. Today, Amazon FAR is releasing a full-stack solution: Holosoma.
To accelerate research, we are open-sourcing a complete codebase covering multiple simulation backends, training, retargeting, and real-world inference.
Open-source: complete codebase covering multiple simulation backends, training, retargeting, and real-world inference. Infra built for humanoid, but also readily modified for quadruped (also included). Lots of infra gems/conveniences we rely on consistently. Hopefully equally helpful for others.
Excited to introduce TWIST2, our next-generation humanoid data collection system. TWIST2 is portable (use anywhere, no MoCap), scalable (100+ demos in 15 mins), and holistic (unlock major whole-body human skills).
Fully open-sourced:
https://t.co/fAlyD77DEt
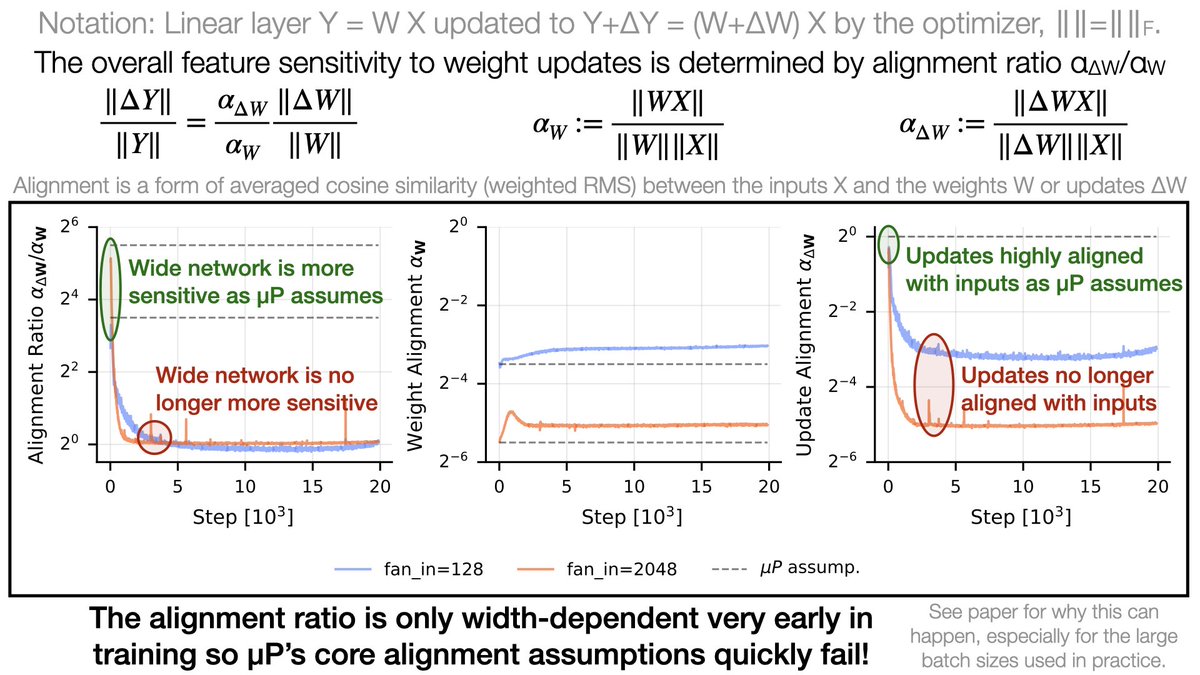
Why override µP? Because its core assumptions only hold very early in training!
In practice wide models quickly stop being more sensitive to weight updates than smaller models! This is caused by changes in the geometric alignment of updates and layer inputs over training. 🧵6/8
The Maximal Update Parameterization (µP) allows LR transfer from small to large models, saving costly tuning. But why is independent weight decay (IWD) essential for it to work?
We find µP stabilizes early training (like an LR warmup), but IWD takes over in the long term! 🧵
I've long wondered if we can make a humanoid robot do a 𝘄𝗮𝗹𝗹𝗳𝗹𝗶𝗽 - and we just made it happen by leveraging 𝗢𝗺𝗻𝗶𝗥𝗲𝘁𝗮𝗿𝗴𝗲𝘁 with BeyondMimic tracking!
This came after our original OmniRetarget experiments, with only minor tweaks to RL training: relaxing a termination threshold and removing one reward term.
The policy achieved a 𝟱/𝟱 success rate in our real-world experiments, showing the strength of high-quality, interaction-preserving motion retargeting combined with BeyondMimic’s minimal RL tracking.
Here is the updated arXiv: https://t.co/0dSdpYJAV6 (In Sec. V. A)
Our grand finale: A complex, long-horizon dynamic sequence, all driven by a proprioceptive-only policy (no vision/LIDAR)! In this task, the robot carries a chair to a platform, uses it as a step to climb up, then leaps off and performs a parkour-style roll to absorb the landing. This pushes the boundaries of agile, human-like loco-manipulation!
7/9
Very excited to start sharing some of the work we have been doing at Amazon FAR. In this work we present OmniRetarget, which can generate high-quality interaction-preserving data from human motions for learning complex humanoid skills.
High-quality re-targeting really helps the reinforcement learning.
Why? The control policy optimization landscape is much nicer for (near)feasible trajectories than for trajectories with artifacts like (e.g.) foot skating or ground penetration.