⏰⏰(another) science of robot learning paper. Why does action chunking work so well in robotic manipulation?
Probably lots of reasons. but here’s one you may not have thought of: control stability.
After months of polishing and 5 revisions, check out“ Action Chunking and Exploratory Data Collection Yield Exponential Benefits for Imitation Learning”. The title says it all.
Lead by the eloquent @ThomasTCKZhang , illustrated by the talented @dpfroms , supported by @ChaoyiPan of MIP fame (https://t.co/P3SCCFNgrT) fame, and in collaboration with the one and only @NikolaiMatni .
🤖🤖Very excited to finally share our new work “Action Chunking and Exploratory Data Collection Yield Exponential Improvements in Behavior Cloning for Continuous Control”
Everyone in robotics does action-chunking, but why does it actually work?🤔🤔And, what can theory tell us about the properties of data we should be collecting for robotic behavior cloning? 🧵1/N
Congratulations to Siqiao ( @KnightNemo_ ) for releasing his NanoWorldModels repo.
World model research can be notoriously tricky, given the numerous small design decisions that can make an excellent idea appear to fail completely. Siqiao's repo will help all researchers avoid these pitfalls; a huge service to the community!
In the last couple of months, we have witnessed significant advances in Industry-scale World Models. Yet, for the broader community, the gap between reading about these models and deploying them remains disappointingly wide.
Today we're releasing Nano World Models: a minimalist, batteries-included repo for advancing world model science.
🧵 (1/9)
#RSS2026 Call for participants 📢
Excited to announce our RSS 2026 Workshop: Post-Training for Robotics Foundation Models, together with the first Real-World Reinforcement Learning Challenge!
The workshop is held on July 13 in Sydney.
https://t.co/c3Dy1CrI0L。
Unlocking test-time scaling and search in generative models has been a fundamental obstacle, and is increasingly important as these methods are deployed in science, engineering, and robotics.
It was a pleasure to work with @peholderrieth on a paradigm that finally makes this capability genuinely possible, and lets you trade off training time vs inference time according to your needs. Check it out!
We release Diamond Maps💎 unlocking accurate and efficient guidance for diffusion models. Our experiments show that our methods scale incredibly well. Excited to see what people will build with this!
Accurate guidance has been a notoriously hard problem, but in this work, we’re bringing TWO (!) solutions to the table. The recipe for success:
1️⃣ Speed: Use distilled models (flow maps, mean flows, consistency models).
2️⃣ Exploration: Inject stochasticity to properly explore your search space.
Because this fundamentally improves anything using flow matching and diffusion, we see a lot of potential for applications across audio, robotics, molecules, and beyond.
Paper: https://t.co/wxtWWRrnw7
Code: https://t.co/WocPtT6orn
Huge thanks to an amazing team: Douglas Chen, @LucaEyring, @ishin_shah, Giri Anantharaman, @electronickale, @zeynepakata, Tommi Jaakkola, @nmboffi, and @max_simchowitz. It was awesome bringing this to life together!
⚠️Public Service Announcement for ICLR folks headed to Rio: Rio is beautiful, but getting a travel adapter in Brazil is a pain in the ass, and they don't use similar outlets to other major regions (US, UK, Europe, China). Buy a Brazil-specific adapter before traveling. Enjoy :)
1/ As AI agents become increasingly capable, what must *inevitably* emerge inside them?
We prove selection theorems: strong task performance forces world models, belief-like memory and—under task mixtures—persistent variables resembling core primitives associated with emotion.
Great work by @nmboffi and @AdtRaghunathan and others!
Excited to see the power of few-step flow maps extend from images to other domains like text. Check out Nick's post to learn more.
We just brought flow maps to language modeling for one-step sequence generation 💥
Discrete diffusion is not necessary -- continuous flows over one-hot encodings achieve SoTA performance and ≥8.3× faster generation 🔥
We believe this is a major step forward for discrete generative modeling and language modeling alike. 🚀
Full thread from first author @chandavidlee: https://t.co/7HIBNbQdFO
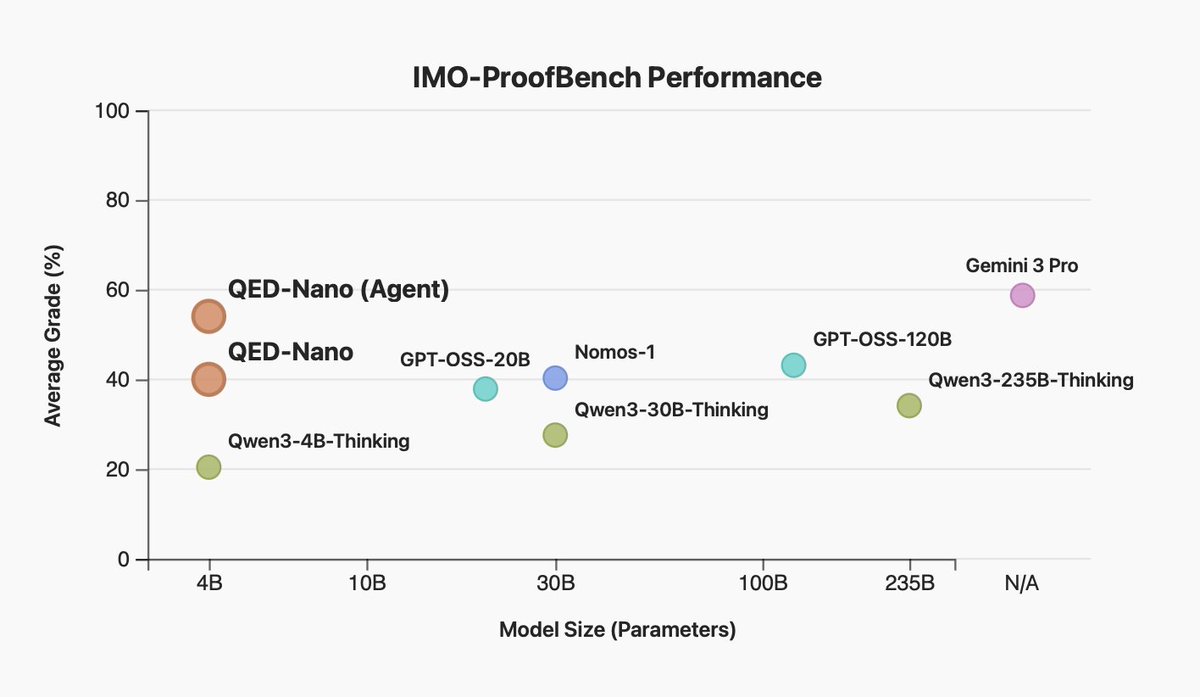
Can just a 4B model solve IMO-level proof problems at the level of much stronger LLMs like Gemini 3 Pro? Yes, if you can train the LLM to scale test-time compute well!
We're very excited to release our 4B model "QED-Nano", built via an awesome open collab! Details below🧵⬇️
Introducing Large Video Planner (LVP-14B) — a robot foundation model that actually generalizes. LVP is built on video gen, not VLA. As my final work at @MIT, LVP has all its eval tasks proposed by third parties as a maximum stress test, but it excels!🤗
https://t.co/wjD54YFK3k
I’ve always seen twitter bros be like “keep building keep shipping” when using ai agents for coding, but now that I’ve tried it for real, it feels less like grinding and more adjacent to eating popcorn while bed rotting and watching heated rivalry (I’m not complaining)
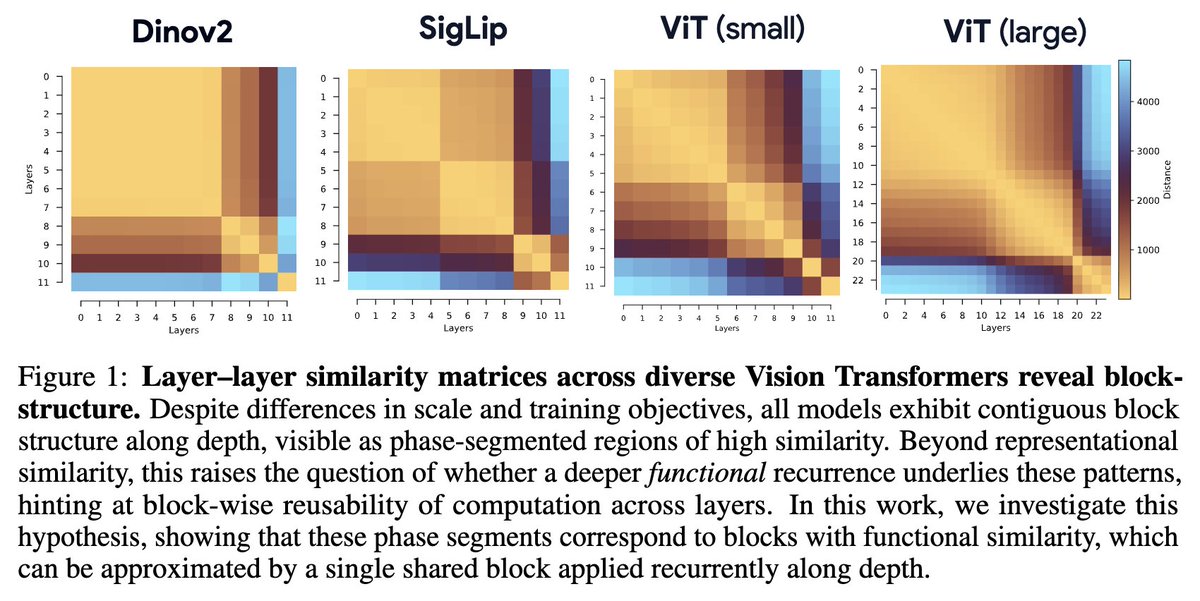
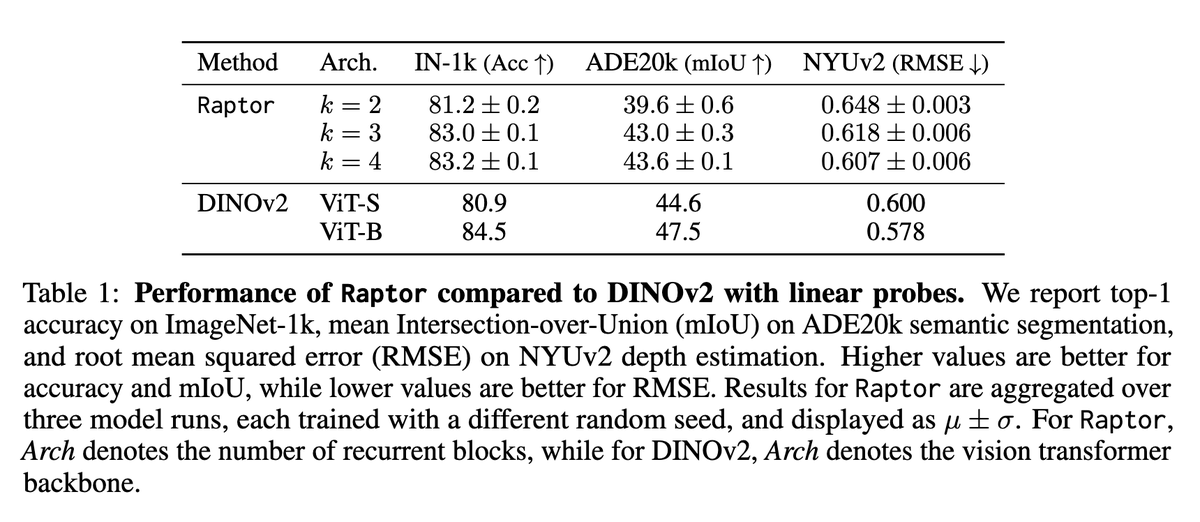
The authors ask whether an N-layer ViT can be rewritten using just K<<N layers by recurring on them. Remarkably, they match DINOv2 performance with only 2-3 layers. The paper also offers rich dynamical-systems analysis. Very cool work!
🔗https://t.co/G2KgMALnpS
Standard training of generative policies is surprisingly bad at learning multi-modal strategies from training data. So what can we do to pre-train for diverse solutions and effective post-training?
Check out @ajwagenmaker 's new paper for an answer :)
How should we pretrain a policy from demonstrations to ensure it is an effective initialization for RL finetuning, while preserving the performance of the pretrained policy itself?
We propose Posterior Behavioral Cloning (PostBC)! (1/11)
My friends @elvisnava and @mimicrobotics (makers of awesome robot hands 🧤) just put out a video-first VLA. 📹📹
Motivation: A bitter-lesson alternative to retargeting, and a path to cross-embodiment.
Key Idea: Nvidia Cosmos backbone with T5 text encoder, and but pre-train from RGB rather than low-dim actions. Low-Dim actions only needed for a lightweight flow-decoder for task-specific fine-tuning.
Benefits: Opens to the door for human data collect with off-the-shelf cloth gloves (and maybe soon, YouTube!), leverages internet scale video, embodiment agnostic.
Excited to see where you go next!
Today @mimicrobotics and friends are excited to share mimic-video, a new class of Video-Action Model that elevates video model backbones as first class citizens for robot learning!
the mistake so many people make is seeing university professors as intellectuals when they’re actually employees at a combination hedge fund and healthcare conglomerate that operates a small luxury resort/sports franchise where student-customers occasionally take classes
What is the best current explanation for why CFG is needed for conditional generation? Is it just that are unguided models “undersharpened”/ over smoothed bc of NN inductive bias ?
Excited to introduce PolaRiS, a real-to-sim recipe for turning short real-world videos into high fidelity simulation environments for scalable and reliable zeroshot generalist policy evaluation.
https://t.co/nWcR6YuPf4
(1/N 🧵)