As LLMs saturate benchmarks, evaluating their five-nines reliability is crucial, but prohibitively expensive. We cut the inference cost by 5-20x on average (up to 156×) by exploiting a key insight: LLM failures are not random.
🧵[1/n]
One of the things I’m most excited about this year is building agents that can work productively for hours, days, or weeks. Coding agents are starting to become very competent at this, but what about computer use agents?
Our new benchmark, Odysseys (co-led with @JangLawrenceK) is a set of 200 new tasks derived from real world browsing behavior that measure long horizon web navigation capabilities (potentially up to hours of web browsing work). Interestingly, we find that frontier CUAs are already surprisingly good at working productively for up to an hour on these tasks, but there’s a lot of work to be done in making them even more efficient.
Like every other AI researcher, my real dream is to open a cafe once we solve ASI. So, here’s Opus 4.6 doing some market research for me ("I want to do market research on the most popular cafes in Singapore. Analyse the menus of the top 10 cafes in Singapore (by Google reviews/ratings), and make sure we include at least 1 from the North/South/East/West/Central regions of Singapore. Keep the relevant pages of each cafe open, and summarise their pricing, menu offerings, unique selling points, making sure to reference which tab is opened for each cafe. For each cafe, also help me figure out how long it would take to get to it from Tampines MRT, and include this in your final summary.").
I was very impressed to see Opus 4.6 complete this task after working for 52 mins, satisfying all 7 rubrics that corresponded to this task. It provided a very nice markdown summary at the end that gave me all the information I asked for!
Foresight will be the defining frontier on the path to AGI.
I am excited to start Sooth Labs with my amazing co-founders: Yaser Sheikh @subail, Chuck Hoover @chuckjhoover, David LaRose, and Shih-En Wei.
Deeply grateful to Aydin Senkut @asenkut and Feyza Haskaraman @FHaskaraman at @felicis for leading the round, alongside an exceptional group of partners.
https://t.co/VBE9JIz42h
Joint work with the amazing @x_duan9296 (the best master's student at CMU), @FahimTajwar10, @rsalakhu, @zicokolter, and Jeff Schneider. Come chat with us today at 3:15 PM!
Paper: https://t.co/80EM9aO0Nb
Code: https://t.co/EFmC5AiZQX
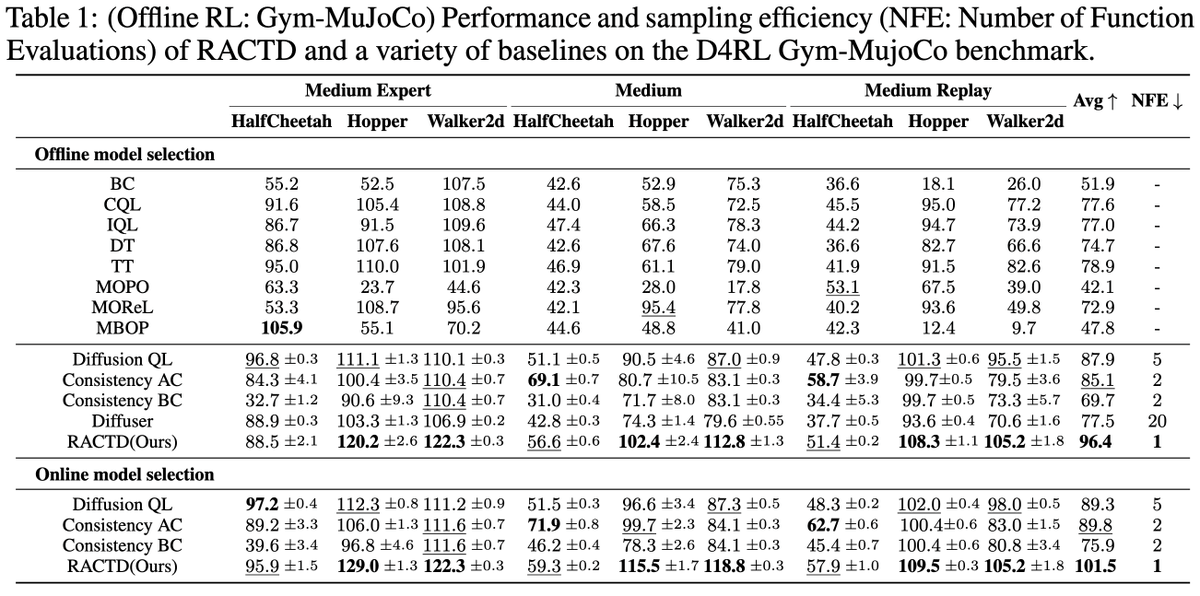
Diffusion planners are great for offline RL. But they need many steps to work well! Way too slow for real-time decision making!
Presenting RACTD at #ICLR2026: reward-aware distillation that plans in ONE step
🇧🇷 Today (4/23) P4-#4618 3:15-5:45 PM
https://t.co/80EM9aO0Nb 1/
RACTD improves over previous SOTA by 9.7% on D4RL Gym-MuJoCo and outperforms Diffuser on long-horizon Maze2D planning
All with a SINGLE denoising step, achieving up to 142x speedup over diffusion counterparts 🚀🚀🚀
How can visual planning agents 𝙨𝙚𝙡𝙛-𝙞𝙢𝙥𝙧𝙤𝙫𝙚 from their own collected experience?
We present 𝗦𝗜𝗟𝗩𝗥🩶, a framework that combines offline data with online experience for concurrent zero-shot generalization and sample-efficient self-improvement capabilities!#ICLR2026
We release Diamond Maps💎 unlocking accurate and efficient guidance for diffusion models. Our experiments show that our methods scale incredibly well. Excited to see what people will build with this!
Accurate guidance has been a notoriously hard problem, but in this work, we’re bringing TWO (!) solutions to the table. The recipe for success:
1️⃣ Speed: Use distilled models (flow maps, mean flows, consistency models).
2️⃣ Exploration: Inject stochasticity to properly explore your search space.
Because this fundamentally improves anything using flow matching and diffusion, we see a lot of potential for applications across audio, robotics, molecules, and beyond.
Paper: https://t.co/wxtWWRrnw7
Code: https://t.co/WocPtT6orn
Huge thanks to an amazing team: Douglas Chen, @LucaEyring, @ishin_shah, Giri Anantharaman, @electronickale, @zeynepakata, Tommi Jaakkola, @nmboffi, and @max_simchowitz. It was awesome bringing this to life together!
F2D2 is accepted at #ICLR2026 ! To celebrate, we have added a new JAX codebase & new results w/ Lagrangian self-distillation in camera-ready! Check them out on our project page: https://t.co/AbcOZGTU77
P.S. I will present F2D2 Apr 23 10:30 AM – 1:00 PM P3-#1911, see yall in Rio🇧🇷
Diffusion/Flow-based models can sample in 1-2 steps now 👍 But likelihood? Still requires 100-1000 NFEs (even for these fast models) 😭
We fix this! Introducing F2D2: simultaneous fast sampling AND fast likelihood via joint flow map distillation.
https://t.co/FFfqWnLIwu
1/🧵
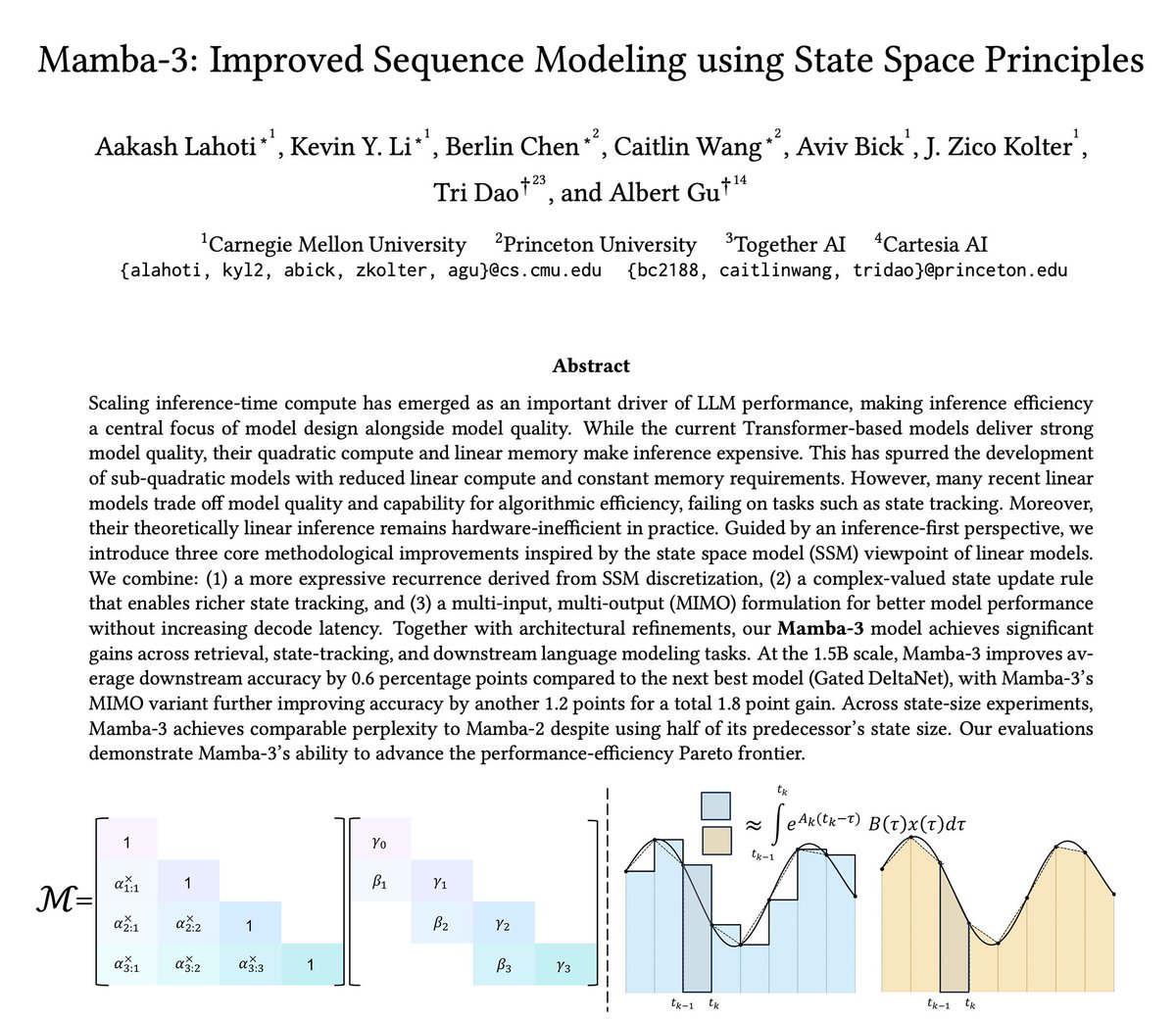
The newest model in the Mamba series is finally here 🐍
Hybrid models have become increasingly popular, raising the importance of designing the next generation of linear models.
We've introduced several SSM-centric ideas to significantly increase Mamba-2's modeling capabilities without compromising on speed. The resulting Mamba-3 model has noticeable performance gains over the most popular previous linear models (such as Mamba-2 and Gated DeltaNet) at all sizes.
This is the first Mamba that was student led: all credit to @aakash_lahoti@kevinyli_@_berlinchen@caitWW9, and of course @tri_dao!
Train Beyond Language. We bet on the visual world as the critical next step alongside and beyond language modeling. So, we studied building foundation models from scratch with vision.
We share our exploration: visual representations, data, world modeling, architecture, and scaling behavior! [1/9]
Excited to announce our workshop on flow-based generative models at CMU:
Frontiers of Flows for Generative AI
March 26-27, Pittsburgh PA
https://t.co/U52Mx5vIYf
We have an amazing lineup of featured talks, panel discussions, and lightning talks. Registration is now open!
Video Editing is great - but what if you want to apply an effect to your input video described by another video??
Introducing RefVFX, the first method that takes in both an input video and a reference effect video for generative video editing!
We just brought flow maps to language modeling for one-step sequence generation 💥
Discrete diffusion is not necessary -- continuous flows over one-hot encodings achieve SoTA performance and ≥8.3× faster generation 🔥
We believe this is a major step forward for discrete generative modeling and language modeling alike. 🚀
Full thread from first author @chandavidlee: https://t.co/7HIBNbQdFO























![EungyeupKim's tweet photo. As LLMs saturate benchmarks, evaluating their five-nines reliability is crucial, but prohibitively expensive. We cut the inference cost by 5-20x on average (up to 156×) by exploiting a key insight: LLM failures are not random.
🧵[1/n] https://t.co/LeObtyqOZK](https://pbs.twimg.com/media/HInrn0EXIAAWHCE.png)








![TongPetersb's tweet photo. Train Beyond Language. We bet on the visual world as the critical next step alongside and beyond language modeling. So, we studied building foundation models from scratch with vision.
We share our exploration: visual representations, data, world modeling, architecture, and scaling behavior! [1/9]](https://pbs.twimg.com/media/HClL4cFbEAA3PHP.png)




















