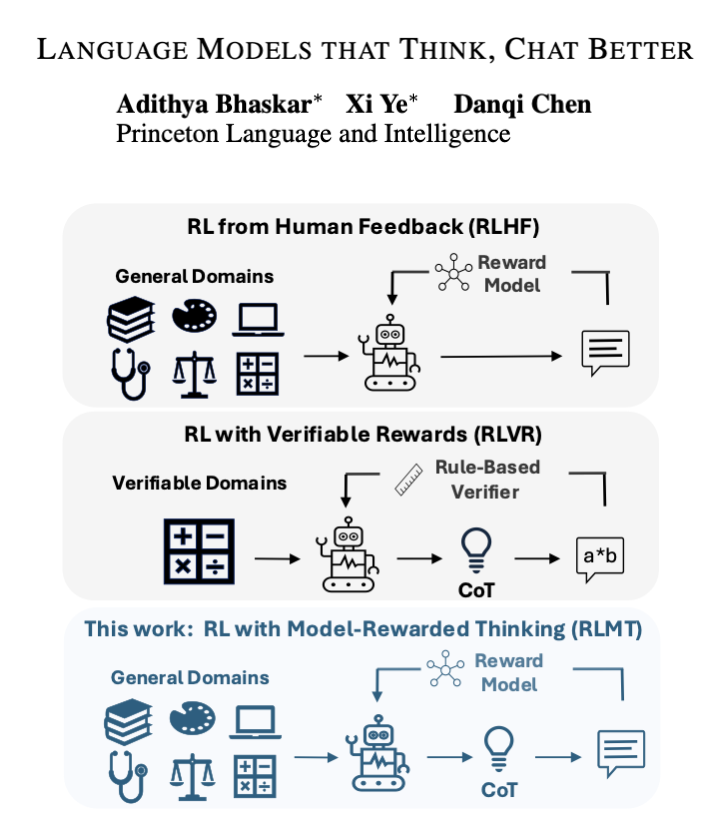
Language models that think, chat better.
We used longCoT (w/ reward model) for RLHF instead of math, and it just works. Llama-3.1-8B-Instruct + 14K ex beats GPT-4o (!) on chat & creative writing, & even Claude-3.7-Sonnet (thinking) on AlpacaEval2 and WildBench!
Read on. 🧵
1/8
My work in 2023: think deeply about technical topic, build the perfect codebase from scratch, know it by heart
My work in 2026: chatting with five dumb people at the same time, they've been stuck Whirliging... for fifteen minutes, not sure what to do so i might spin up a sixth
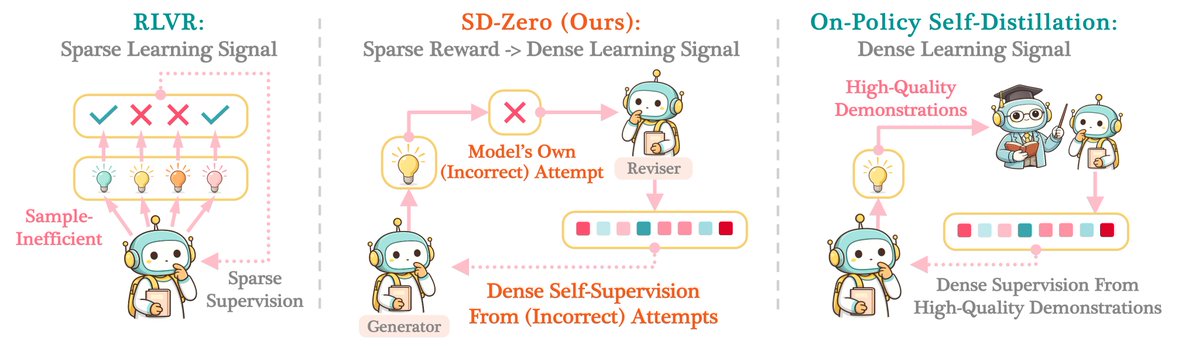
RLVR gives sparse supervision; On-Policy Self-Distillation often requires high-quality demonstrations. Our new method, ✨SD-Zero✨, gets the best of both worlds – we use model’s self-revision to turn binary rewards into dense token-level supervision. No external teacher. No curated demonstrations.
🚨 Introducing Self-Distillation Zero (SD-Zero), which trains one model to play two roles: (1) “Generator” that makes attempts, and (2) “Reviser” that conditions on the generator’s failed/successful attempt + binary reward to produce a better answer. ‼️Even WRONG attempts can become the training signal.‼️
🔗Paper: https://t.co/LwboIqHE11
🏆 SD-Zero brings 10%+ improvement over base models (Qwen3,4B; Olmo3,7B) on math & code reasoning, beating GRPO and vanilla On-Policy Self-Distillation under the same training budget. SD-Zero also enables iterative self-evolution.
Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
"SD-ZERO trains a single model to play two roles: a Generator, which produces an initial response, and a Reviser, which conditions on that response and its binary reward to produce an improved response. We then perform on-policy self-distillation to distill the reviser into the generator, using the reviser’s token distributions conditioned on the generator’s response and its reward as supervision. In effect, SD-ZERO trains the model to transform binary rewards into dense token-level self-supervision."
On-policy self-distillation on revised output. First train a model to generate both output and revision given the outcome. And do on-policy self-distillation to match the revised output.
Video models surprisingly can solve mazes, but inconsistently. We understand little about how they reason, making it hard to use such abilities.
We investigate the denoising process and find models commit to a plan early, letting us screen far more candidates for better perf.
🧵
STAT has been accepted to ICLR 2026! See you in Brazil 🇧🇷
Skill-Targeted Adaptive Training (STAT) is a continual learning method that squeezes out 🚨 7~10% more performance on extensively trained models like Qwen. It constructs a 🧩 Missing-Skill-Profile for each model based on what skills the model lacks in their responses, and adaptively curates post-training data accordingly.
Check out our Blog Post 👉 https://t.co/GeCZzQNXFk
🔗arXiv : https://t.co/Q3ItCevBEh
💻GitHub: https://t.co/jgx4h1C6GT
New #NVIDIA Paper
We introduce Motive, a motion-centric, gradient-based data attribution method that traces which training videos help or hurt video generation.
By isolating temporal dynamics from static appearance, Motive identifies which training videos shape motion in video generation.
🔗 https://t.co/TbKXjQMN3H
1/10
@VincentMoens@NeurIPSConf Hey Vincent, I would love to chat at NeurIPS. It seems that I can't DM you here without a premium account, so commenting instead.
I will be at NeurIPS 2025 from 12/2 to 12/7.
These days, I am most interested in bridging mid-training and post-training (of LLMs). Hit me up if you want to chat!
Text-to-image (T2I) models can generate rich supervision for visual learning but generating subtle distinctions still remains challenging.
Fine-tuning helps, but too much tuning → overfitting and loss of diversity.
How do we preserve fidelity without sacrificing diversity (1/8)
Claude Skills shows performance benefits from leveraging LLM skill catalogs at inference time. Our previous work (linked under thread 5/5) showed the same 6 months ago! 🌟Our new work, STAT, shows that leveraging skills during training can greatly help too‼️, e.g., Qwen can continue to learn new tricks from Hendrycks MATH, which it had been over-trained on.
🚨 We introduce Skill-Targeted Adaptive Training (STAT), which uses a supervisor model and a skill catalog to construct a 🧩Missing-Skill-Profile for each student model, and then modifies training to squeeze out >=7% more performance! The intervention can be as simple as reweighting existing training sets. You can also think of this as a more effective distillation method. More in threads 🧵
📎 [arxiv]: https://t.co/Q3ItCevBEh
💻 [github]: https://t.co/jgx4h1C6GT
🥳 Amazing collaborators: @Abhishek_034, @Yong18850571, @prfsanjeevarora
@xiye_nlp and I have been using tinker to run some experiments for our recent paper (go check it out!), and we can attest that it is really convenient!
- Don't have to worry about moving stuff to devices, OOMs, etc.
- Great conceptual modularity
- Great throughput!
Introducing Tinker: a flexible API for fine-tuning language models.
Write training loops in Python on your laptop; we'll run them on distributed GPUs.
Private beta starts today. We can't wait to see what researchers and developers build with cutting-edge open models!
https://t.co/tJsgxgBuWo







![yinghui_he_'s tweet photo. Claude Skills shows performance benefits from leveraging LLM skill catalogs at inference time. Our previous work (linked under thread 5/5) showed the same 6 months ago! 🌟Our new work, STAT, shows that leveraging skills during training can greatly help too‼️, e.g., Qwen can continue to learn new tricks from Hendrycks MATH, which it had been over-trained on.
🚨 We introduce Skill-Targeted Adaptive Training (STAT), which uses a supervisor model and a skill catalog to construct a 🧩Missing-Skill-Profile for each student model, and then modifies training to squeeze out >=7% more performance! The intervention can be as simple as reweighting existing training sets. You can also think of this as a more effective distillation method. More in threads 🧵
📎 [arxiv]: https://t.co/Q3ItCevBEh
💻 [github]: https://t.co/jgx4h1C6GT
🥳 Amazing collaborators: @Abhishek_034, @Yong18850571, @prfsanjeevarora](https://pbs.twimg.com/media/G3re93gXAAAScn4.jpg)







![yinghui_he_'s tweet photo. Claude Skills shows performance benefits from leveraging LLM skill catalogs at inference time. Our previous work (linked under thread 5/5) showed the same 6 months ago! 🌟Our new work, STAT, shows that leveraging skills during training can greatly help too‼️, e.g., Qwen can continue to learn new tricks from Hendrycks MATH, which it had been over-trained on.
🚨 We introduce Skill-Targeted Adaptive Training (STAT), which uses a supervisor model and a skill catalog to construct a 🧩Missing-Skill-Profile for each student model, and then modifies training to squeeze out >=7% more performance! The intervention can be as simple as reweighting existing training sets. You can also think of this as a more effective distillation method. More in threads 🧵
📎 [arxiv]: https://t.co/Q3ItCevBEh
💻 [github]: https://t.co/jgx4h1C6GT
🥳 Amazing collaborators: @Abhishek_034, @Yong18850571, @prfsanjeevarora](https://pbs.twimg.com/media/G3re93gXwAA6cPI.jpg)






























