Excited to introduce RAPTOR at #ICLR2024!
RAPTOR is a tree based retrieval system that can navigate between low-level details and a holistic understanding of texts. Check out our paper here: https://t.co/v60wILm4VT 🦖
RAPTOR is a retrieval method that treats documents like hierarchies.
Instead of just matching to chunks of text, RAPTOR finds the most similar passages to your query and then traverses the document like a tree to find the most relevant high-level context and low-level details.
RAPTOR by @parthsarthi03 is a cool new paper on tree-structured-retrieval 🌲 that harkens back to the early days of @llama_index / gpt_index.
Been meaning to dig into it, in the meantime @ravithejads has a great summary below 👇
Stanford presents RAPTOR
Recursive Abstractive Processing for Tree-Organized Retrieval
paper page: https://t.co/6Gfcm11Bwx
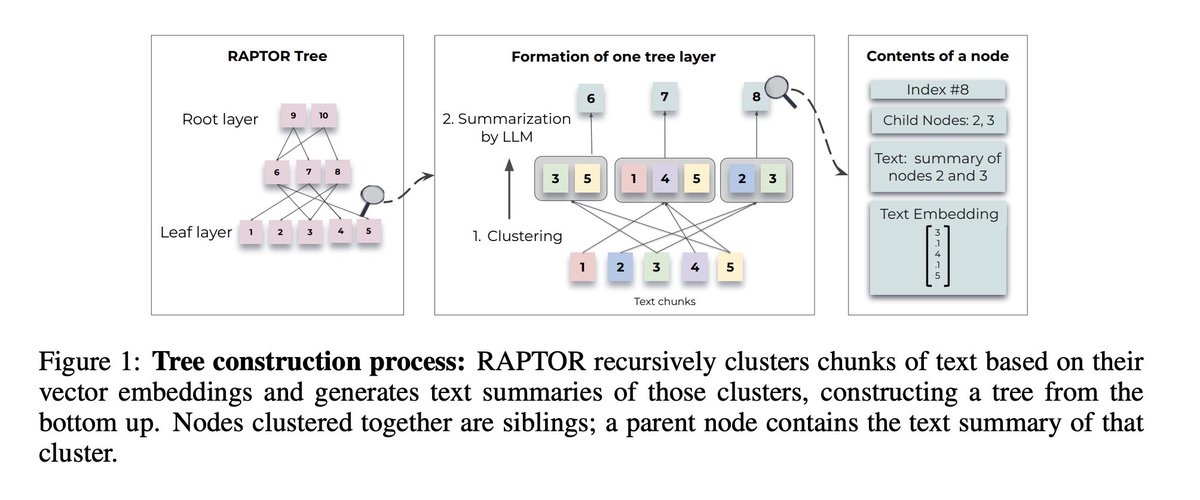
Retrieval-augmented language models can better adapt to changes in world state and incorporate long-tail knowledge. However, most existing methods retrieve only short contiguous chunks from a retrieval corpus, limiting holistic understanding of the overall document context. We introduce the novel approach of recursively embedding, clustering, and summarizing chunks of text, constructing a tree with differing levels of summarization from the bottom up. At inference time, our RAPTOR model retrieves from this tree, integrating information across lengthy documents at different levels of abstraction. Controlled experiments show that retrieval with recursive summaries offers significant improvements over traditional retrieval-augmented LMs on several tasks. On question-answering tasks that involve complex, multi-step reasoning, we show state-of-the-art results; for example, by coupling RAPTOR retrieval with the use of GPT-4, we can improve the best performance on the QuALITY benchmark by 20% in absolute accuracy.