Excited to introduce RAPTOR 🦖 at #ICLR2024:
RAPTOR is a tree-based retrieval approach that navigates between granular details and a holistic understanding of documents. It sets a new SoTA on 3 benchmarks.
Read the paper here:
https://t.co/WjBn2LKyOO
Running AI agents has become easy. Observing them is the hard part.
Let one run 24/7 for days and your terminal becomes a wall of scrollback no human can ever read. We don't know what it actually did, where it stalled, or whether it quietly went off the rails.
1/
RL fine-tuning often prematurely collapses LLM entropy.
Poly-EPO is a scalable set-RL algorithm that optimizes for a set of accurate solutions with diverse reasoning strategies.
Paper: https://t.co/0HVe8YHr56
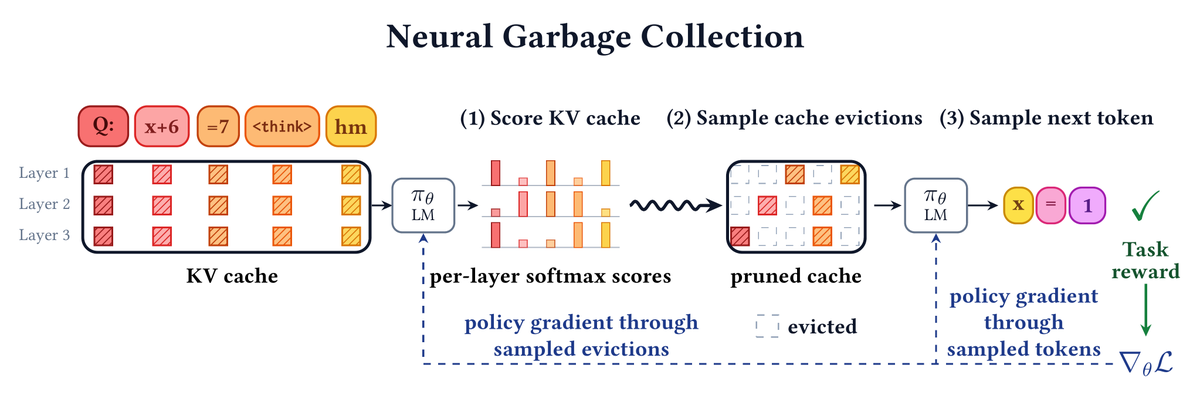
Can a language model learn, end-to-end, what to keep in its own KV cache and what to throw away? Can it learn to forget while it learns to reason?
Deep learning's central lesson: capability emerges from end-to-end optimization, not heuristics/strong inductive biases. But for efficiency, we rely heavily on hand-designed approaches.
🗑️ Introducing Neural Garbage Collection (NGC): we train a language model to jointly reason and manage its own KV cache, using reinforcement learning with outcome-based task reward alone. No SFT, no proxy objectives, no summarization in natural language.
New paper with @jubayer_hamid, Emily Fox, and @noahdgoodman!
Exploration is the lifeblood of learning from experience. An agent must search broadly to uncover successful behaviors. It should continue exploring to expand its capabilities by learning distinct strategies to complex problems. Threading this needle between exploration and exploitation is critical for solving unsolved problems at test-time.
An algorithm should encourage (1) optimistically exploring reasoning strategies, and (2) achieving a synergy between exploration and exploitation. Towards that end, we develop Poly-EPO: a method for training LMs to explore and reason. Work with @ifdita_hasan (co-lead), Shreya, @ShirleyYXWu, @HengyuanH, @noahdgoodman, @DorsaSadigh, and @chelseabfinn. 🧵
Heading to ICLR today and excited to be presenting two papers! 🇧🇷
If you’re interested in self-improving agents, lifelong learning, exploration, or just want to connect, I’d love to chat. DMs are open!
👇 I’ll be presenting:
📝 RLAD: Training LLMs to Discover Abstractions for Solving Reasoning Problems
📅 04/23, 3:15 PM | Pavilion 3, Poster #1413
📝 FSPO: Few-Shot Optimization of Synthetic Preferences Personalizes to Real Users
📅 04/23, 10:30 AM | Pavilion 3, Poster #1509
🚨🚨New Paper: Generative Insight Anticipation from Scientific Literature
Human scientists achieve breakthroughs by "standing on the shoulders of giants," synthesizing profound insights from disparate sources. While LMs show promise in scientific discovery, they currently struggle to reliably generate ideas of true impact, diversity, and feasibility.
Introducing "insight anticipation," a novel task challenging LLMs to generate a downstream paper's core scientific contribution directly from its foundational prior works. We also introduce GIANTS-4B, an RL-trained model that significantly outperforms frontier models at this task! 🧵⬇️
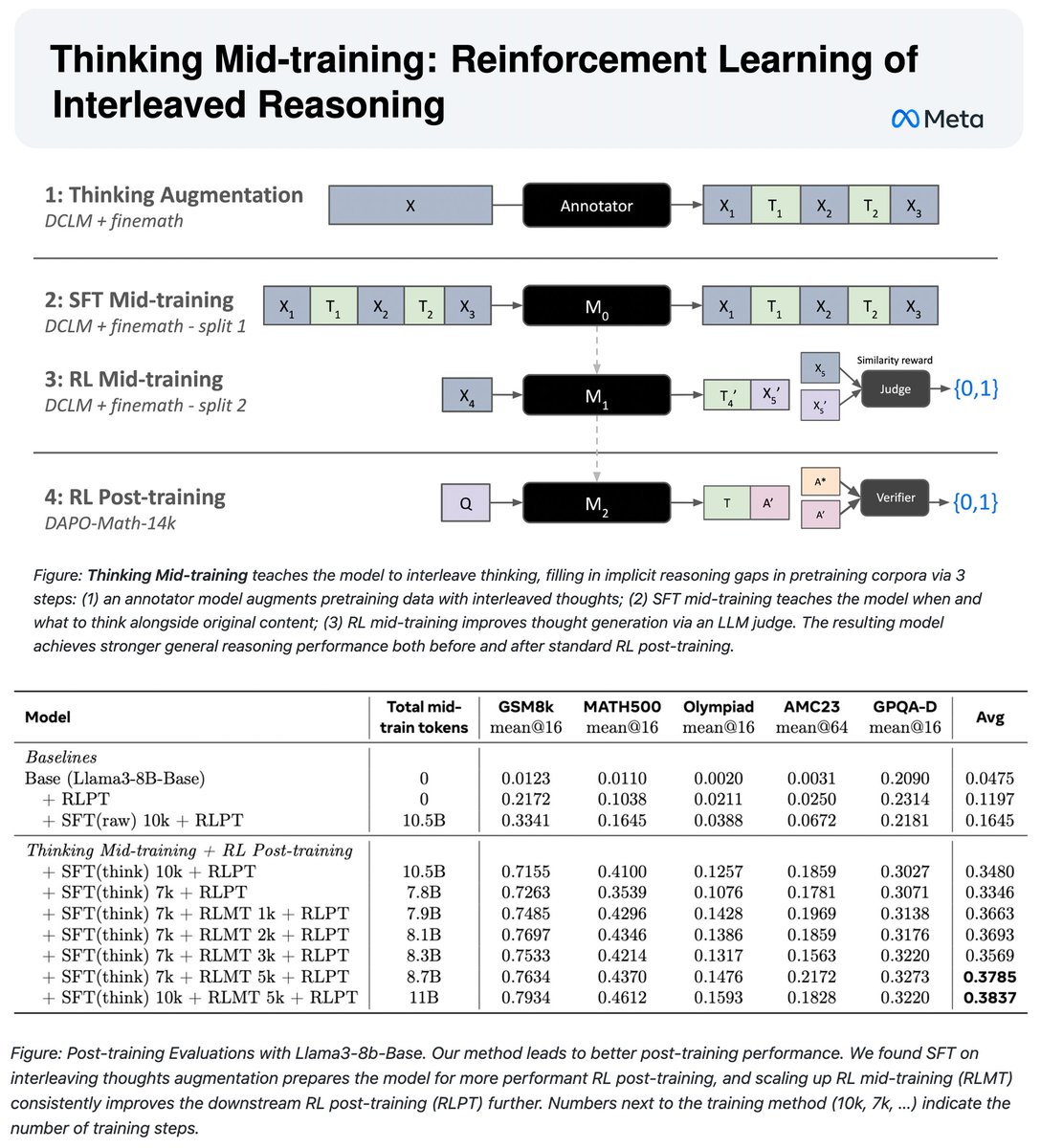
🏋️Thinking Mid-training: RL of Interleaved Reasoning🎗️
We address the gap between pretraining (no explicit reasoning) and post-training (reasoning-heavy) with an intermediate SFT+RL mid-training phase to teach models how to think.
- Annotate pretraining data with interleaved thoughts
- SFT mid-training to learn when/what to think alongside original content
- RL mid-training to optimize reasoning generation with grounded reward from future token prediction
Result: 3.2x improvement on reasoning benchmarks compared to direct RL post-training on base Llama-3-8B, and gains over only prior SFT as well.
Introducing reasoning earlier makes models better prepared for post-training!
Read more in the blog post: https://t.co/aGJcQKUjRw
We're proud to share that WebGym is now accepted to CVPR 2026. I would be excited to talk to people working in the vision domain about web agents and reinforcement learning. See you in Denver soon. 😈
Code and data are now publicly available at https://t.co/Iv9RimUx9x.
Happy to share that our paper is accepted at ICLR 2026.
Since publishing it, we’ve been pushing the ideas much further: scaling set RL to LLMs for reasoning in maths and coding.
Excited to share what we have found soon!
😈 Today, Microsoft open-sources WebGym: the task set, code, a bunch of visualization tools, and guiding documentations. WebGym is an RL environment with the *first* open-source implementation of the fully asynchronous rollout system designed for multi-step vision-supported web agentic trajectory collection, which speeds up *4x-5x* compared to existing synchronous implementations. This release comes with *300k* realistic web agentic tasks with comprehensive evaluation rubrics and pipeline, together with annotations on difficulty and domains.
🧵 1/6
😈 Today, we introduce WebGym, the largest-to-date open-source RL environment for web agent training that contains 300k tasks and a rollout framework optimized specifically for web environments' rollout speed. We reveal the effects of essential scaling directions we observe with WebGym.
1/n
I am incredibly excited to introduce Chariot. (@Chariot_in)
Suvrat (@TheBhooshan) and I are working a research lab based in India to research systems that can truly understand, reason, and interact with the world starting with speech. We are one of the four teams backed by the @OfficialINDIAai Mission and the Government of India.
Today, we had the incredible honor of meeting and interacting with the Honorable Prime Minister of India @NarendraModi ji at his residence to explain what we are working on.
While I was explaining our model to him, he zeroed in on the core problem and asked me if the model could discern the intent behind the words to determine the correct tone. With his example of "Ram Naam Satya Hai" vs "Ram Ram”, he asked if the model knows when something is solemn vs casual? Does it understand the weight of what's being said, not just the words themselves?
It's exactly the kind of problem we're obsessing over at Chariot— speech isn't transcription, it's intent, emotion, cultural context, all encoded in how something is said.
Grateful to the India AI Mission for this opportunity. Lots to build. 🇮🇳
Agreed. The frontier is on Continual learning, personalization and memory management. We fundamentally don’t know how to do it and it will have direct and immediate impact on enterprise.
Fara-7B is our first agentic small language model for computer use.
We learned a lot, and looking forward to next steps:
*Agentic models can be small, yet remain capable
*Unlike solutions that rely on chat model wrappers, even small agentic models can process screenshots and perform direct GUI actions such as scrolling, typing, and clicking.
*Simulation-driven multi-agent synthetic data to automates task generation, trajectory generation and validation is a way to address the agentic data scarcity gap, and in our case costs < $1 per task.
*Evaluating CUA is hard ; we release WebTailBench, a new eval set with diverse tasks not found in other benchmarks, and work with an external party, Browserbase, to independently assessed Fara-7B using human annotators.
Model available on Foundry and HuggingFace and can run on device on Copilot+ PC
🚨🚨New Paper: Training LLMs to Discover Abstractions for Solving Reasoning Problems
Introducing RLAD, a two-player RL framework for LLMs to discover 'reasoning abstractions'—natural language hints that encode procedural knowledge for structured exploration in reasoning.🧵⬇️