Les journées de #statistique#JDS2024 auront lieu à @Bordeaux du 27 au 31 mai, sur le campus Victoire @univbordeaux !
Évènement d'envergure dans ce domaine de #recherche pour les scientifiques, des événements ouvert à tous sont également proposés !
👉 https://t.co/Lb6YEvbx5a
📢 Les #JDS2024 c'est lundi ! Au programme, échanges entre scientifiques et événements ouverts au public :
✅️ Soirée débat au Starfish
✅️ Atelier Enseignement de la #statistique
✅️ Atelier Recherche #reproductible✅️ Atelier Stat et #sport
https://t.co/Lb6YEvc4UI
Dans le cadre des journées de #statistique#JDS2024, rendez-vous le mardi 28 mai à 19h au bar le #Starfish pour un #Café de la statistique sur la "Prédiction des résultats #électoraux".
📢 Événement gratuit et ouvert au public.
👉 https://t.co/Lb6YEvbx5a
MLPs are so foundational, but are there alternatives? MLPs place activation functions on neurons, but can we instead place (learnable) activation functions on weights? Yes, we KAN! We propose Kolmogorov-Arnold Networks (KAN), which are more accurate and interpretable than MLPs.🧵
State Space Models: A Modern Approach
This is an interactive textbook on state space models (SSM) using the JAX Python library.
https://t.co/GZSaypO2o6
Modern LLMs are much more than token predictors. They are also much more than pretrained Transformers. I review the post pretraining processes in my latest blog post: https://t.co/ubKaMcHbur
As many of you know, over the past few months I have been sharing Prompt Engineering resources in different forms. I have now compiled them all into a cohesive publication and uploaded to arxiv: https://t.co/7TZgGF67lj
okay so AI can literally read our minds now.
a team from osaka was able to reconstruct visual images from mri scan data using stable diffusion.
first row is the image presented to the test subject, second row is the reconstructed image from mri data.
wild.
Wow, my Transformers Catalog has been viewed over 10k since last week's update. Many good comments too. Quick follow up includes link to github for folks who want to file a PR. Also adding a new timeline view where the Y-axis is model size https://t.co/bPbT5PjTS4
Excited to announce our Deep Learning Tuning Playbook, a writeup of tips & tricks we employ when designing DL experiments. We use these techniques to deploy numerous large-scale model improvements and hope formalizing them helps the community do the same! https://t.co/vDhSwZyHJm
You couldn't make it to #NeurIPS2022 this year?
Nothing to worry - I curated a summary for you below focussing on key papers, presentations and workshops in the buzzing space of ML in Biology and Healthcare 👇
Did you know you can perform ❗exact❗ uncertainty quantification for approximate Gaussian processes in quadratic time? 🤯
Joint work w/ G. Pleiss, M. Pförtner, @PhilippHennig5 and J. Cunningham at #NeurIPS2022.
Paper 📄 https://t.co/DpDgHiinV1
Code 💻 https://t.co/5KrjU2Mt12
Hi #rstats users! If you’ve been wrangling data in the tidyverse, the Arquero library in #JavaScript will feel familiar. Here's a primer to help translate common wrangling methods from dplyr & tidyr to Arquero, so you can work more nimbly between R & JS 🪄https://t.co/vpRLUkZNXc
My AI and ML research paper review time has gone down significantly.
Thanks to this amazing tool - https://t.co/nDV3I3IG2r that uses an AI model to explain dense sections
In the background, an LLM simplifies and explains complex concepts
AI explaining AI 👏👏👏
Our paper on understanding AlphaZero♟️is now published at PNAS! https://t.co/R2Cpt1XsaW The paper "studies" AZ's internals and its behaviors in collaborations with @DeepMind and world chess champion @32gcfhkmm. What did we learn? 🧵
A Large Language Model trained on scientific papers.
Type a text and https://t.co/XKTkxs8Ae0 will generate a paper with relevant references, formulas, and everything.
Amazing work by @MetaAI / @paperswithcode
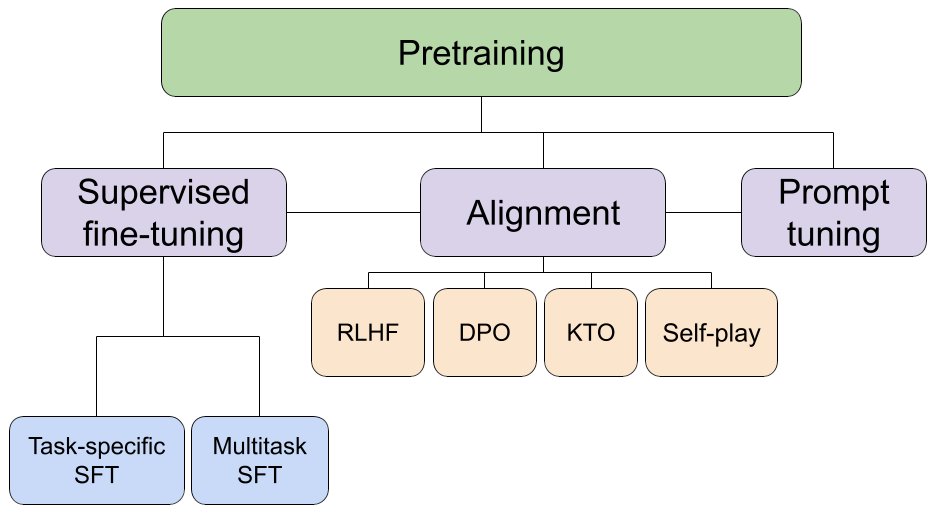
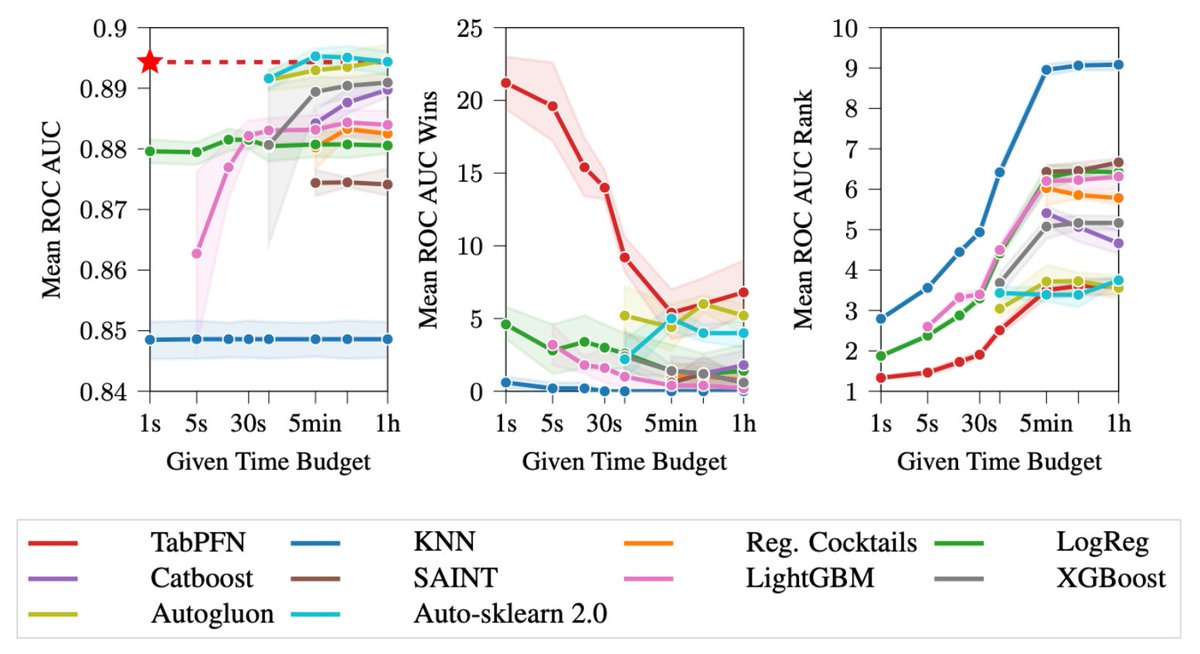
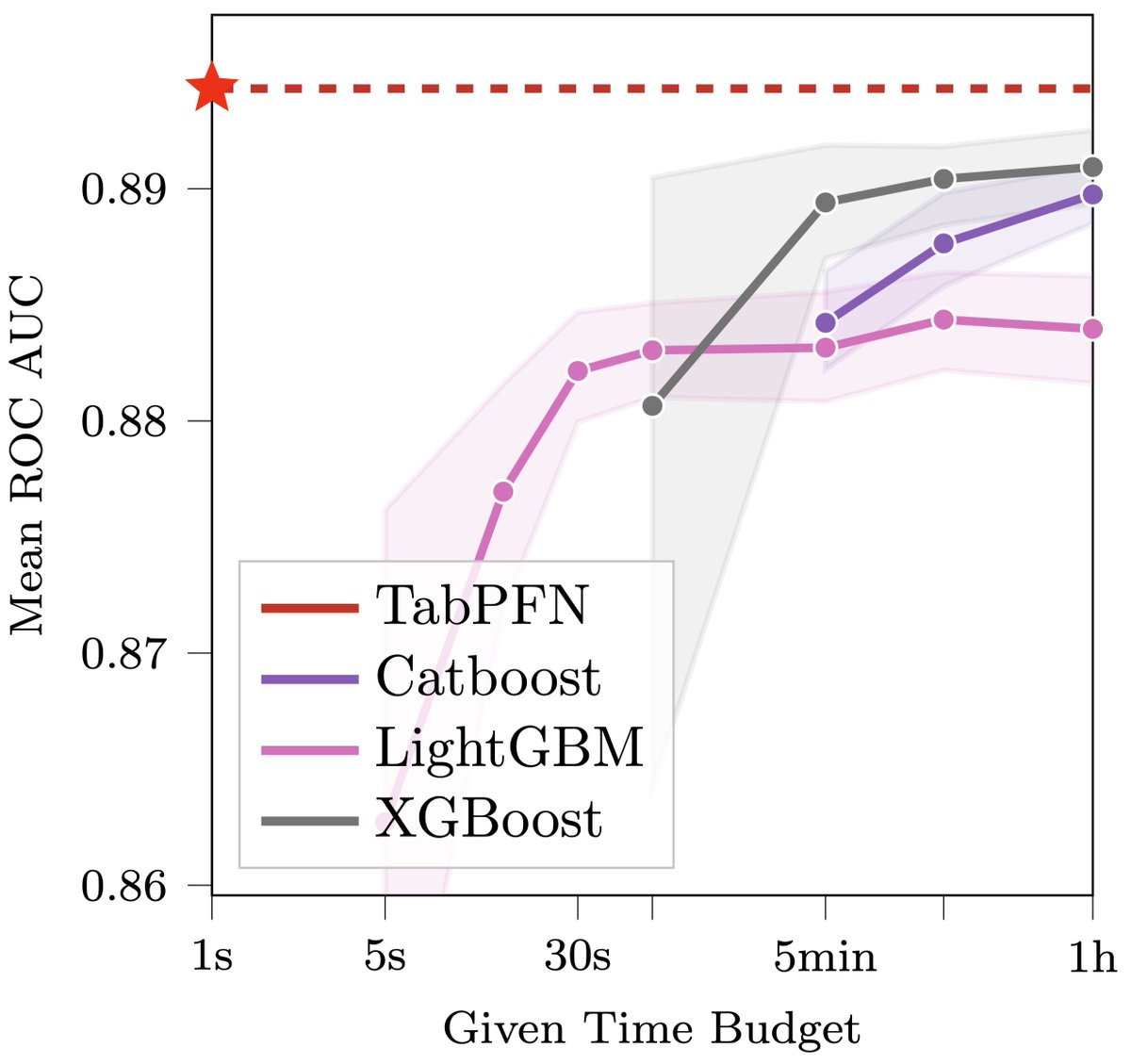
Thanks for the many comments on my tweet on TabPFNs: https://t.co/vtqv7L5du9
Here's an update on how this may revolutionize data science.
TL;DR: learning classification algorithms rather than programming them; real-time AutoML; democratizing ML to tackle *small data*! 🧵1/9
This may revolutionize data science: we introduce TabPFN, a new tabular data classification method that takes 1 second & yields SOTA performance (better than hyperparameter-optimized gradient boosting in 1h). Current limits: up to 1k data points, 100 features, 10 classes. 🧵1/6