Most companies don't need AI Agents.
They need better RAG.
That's the uncomfortable truth.
Right now, everyone wants to build autonomous AI systems that can reason, plan, use tools, and complete tasks independently.
But many teams haven't even solved the retrieval problem yet.
Here's the difference:
📚 RAG answers questions.
🤖 AI Agents complete objectives.
RAG is like hiring the world's fastest researcher.
Ask a question.
It finds the right documents, retrieves relevant information, and generates an answer.
Simple.
Reliable.
Cost-effective.
AI Agents are different.
They don't stop at answers.
They decide what to do next.
They break goals into tasks.
They call APIs.
They write code.
They use tools.
They evaluate results.
And they keep working until the objective is complete.
That's why an Agent is exponentially more powerful...
And exponentially harder to build.
The biggest mistake I see:
Companies trying to deploy AI Agents when what they actually need is a solid RAG system connected to their knowledge base.
Because if an agent can't retrieve the right information...
It will simply make faster mistakes.
The AI stack is evolving:
LLM → Generates
RAG → Retrieves
Agent → Acts
The future isn't RAG vs Agents.
The future is Agents powered by great retrieval.
Because intelligence without context is guessing.
And autonomy without context is dangerous.
Question:
Are you building RAG systems, AI Agents, or both? 👇
#AI #GenAI #RAG #AIAgents #LLM #ArtificialIntelligence #MachineLearning #Automation #AgenticAI #Tech
Most developers think Claude Code is just an AI coding assistant.
They're wrong.
Claude Code is secretly a 5-layer operating system for AI agents.
And 90% of people never go beyond Layer 1.
Here's the architecture 👇
━━━━━━━━━━━━━━━
🧠 Layer 1 — Memory (CLAUDE.md)
Your project's brain.
Stores:
→ Coding standards
→ Architecture decisions
→ Team workflows
→ Repo conventions
→ Engineering rules
Persistent across sessions.
This is what transforms Claude from:
"Generic AI"
into:
"Your engineering team's AI."
━━━━━━━━━━━━━━━
📚 Layer 2 — Skills
Reusable expertise modules.
Need:
→ A React expert?
→ A security auditor?
→ A database architect?
Claude dynamically loads the right knowledge only when needed.
Benefits:
→ Cleaner context
→ Lower token usage
→ Specialized execution
→ Fewer hallucinations
This is where AI starts feeling agentic instead of conversational.
━━━━━━━━━━━━━━━
🔒 Layer 3 — Hooks
The layer most teams completely ignore.
Hooks are programmable infrastructure triggers.
Examples:
→ Auto-run tests
→ Block risky commands
→ Enforce code quality
→ Inject runtime context
→ Send Slack alerts
→ Auto-format outputs
This is NOT AI reasoning.
It's deterministic reliability.
Production-grade AI systems are built here.
━━━━━━━━━━━━━━━
🤖 Layer 4 — Subagents
This is where Claude Code becomes a true multi-agent system.
Delegate tasks like a real engineering organization:
→ One agent writes code
→ One reviews PRs
→ One writes tests
→ One investigates bugs
Parallel execution.
Isolated context.
Separate tools.
No context pollution.
No recursive chaos.
You stop thinking:
"One assistant"
And start thinking:
"Distributed cognitive workers."
━━━━━━━━━━━━━━━
📦 Layer 5 — Plugins
The distribution layer.
Package:
→ Skills
→ Hooks
→ Commands
→ Agents
→ Workflows
...into one reusable install.
Install once.
Share across teams.
Reuse everywhere.
This is how organizations operationalize AI engineering at scale.
━━━━━━━━━━━━━━━
The biggest misconception in AI right now:
People think the magic is prompting.
It's not.
The real leverage comes from:
→ Architecture
→ Orchestration
→ Memory systems
→ Deterministic workflows
→ Agent coordination
Most people are chatting with Claude.
A few are building autonomous software teams inside it.
That's the real shift happening right now.
🔖 Bookmark this if you're serious about AI engineering.
#ClaudeCode #AIAgents #AgenticAI #AIEngineering #SoftwareDevelopment #LLM
These 9 lectures from Stanford University are the BEST for anyone wanting to learn and understand LLMs in depth
Lecture 1 - Transformer: https://t.co/cVdYFH3S4Y
Lecture 2 - Transformer-Based Models & Tricks: https://t.co/Y5NMU4gukB
Lecture 3 - Tranformers & Large Language Models: https://t.co/l1g10v5Geo
Lecture 4 - LLM Training: https://t.co/Yns6HyfhJE
Lecture 5 - LLM tuning: https://t.co/19B5gUR56K
Lecture 6 - LLM Reasoning: https://t.co/YAMRpvjvji
Lecture 7 - Agentic LLMs: https://t.co/xo9oWaeO5p
Lecture 8 - LLM Evaluation: https://t.co/hPoBaT0g2J
Lecture 9 - Recap & Current Trends: https://t.co/knCs62eb42
Start understanding LLMs in depth from the experts. Go through each step-by-step video
Start understanding LLMs in depth from the experts. Go through each step-by-step video
You ask AI a question.
400ms later, it answers like magic.
But your prompt just traveled through an invisible infrastructure pipeline most developers never think about:
→ API Gateways
→ Load Balancers
→ Tokenizers
→ GPU Routers
→ Inference Engines
→ KV Cache
→ Safety Filters
→ Billing Systems
→ Observability Pipelines
Every single token touches dozens of systems before it reaches your screen.
And here's the crazy part:
The model itself is only ONE layer.
The real engineering challenge is everything around it.
Most AI latency bugs aren't "the model being slow."
They're:
• bad routing
• cold GPUs
• token explosion
• cache misses
• overloaded gateways
• broken streaming
• safety rechecks
• observability bottlenecks
Modern AI apps are no longer "just calling an API."
They're distributed systems pretending to be chatbots.
The developers who understand this stack will build the next generation of AI infrastructure.
Everyone else will keep blaming the model.
Save this before your next mysterious latency spike 🔖
Everyone is fine-tuning LLMs.
Almost nobody understands what is actually being updated inside the model.
Here are 5 techniques that change how you think about model adaptation, and what each one is actually doing to the weights:
1./ LoRA - Learn the update, not the weights
The pretrained weight W is frozen. Completely untouched.
Instead of updating W directly, two small matrices are trained =>
A ∈ ℝʳˣᵈ and B ∈ ℝᵈˣʳ, where r ≪ d
The weight update is: ΔW = BA Effective weight: W' = W + BA
The entire adaptation happens in a tiny low-rank space. W never changes.
2./ LoRA-FA - What if we freeze even more?
Same structure as LoRA. One change.
A is frozen alongside W. Only B is trained. Effective weight: W' = W + BA (A is fixed)
Half the trainable matrices of LoRA. Same core idea. Fewer parameters.
3./ VeRA - What if the matrices don't need to be learned at all?
This is where it gets interesting.
A and B are both frozen, and randomly initialized. What gets trained are just two tiny scaling vectors =>
b ∈ ℝʳ and d ∈ ℝʳ
Instead of learning the low-rank matrices themselves, VeRA keeps them frozen and learns small scaling vectors that modulate their contribution.
Initialization => b = 0, d = 1
You're not learning matrices. You're learning how to scale them.
One of the most parameter-efficient techniques on this list.
4./ Delta-LoRA - What if W itself learns from the low-rank updates?
This one is fundamentally different.
Unlike standard LoRA, the base weight W is not fully frozen. It is updated through low-rank delta propagation at every step =>
W^(t+1) = W^t + c(B_(t+1)A_(t+1) − B_t A_t)
Where c is a scaling factor.
A and B are trainable. W evolves, but guided entirely by low-rank changes.
5./ LoRA+ - Same structure. Smarter learning rates.
Identical to LoRA, freeze W, train A and B.
One change => B is assigned a larger learning rate than A. η_B > η_A
A ← A − η_A · ∂J/∂A B ← B − η_B · ∂J/∂B
A small optimization change that can make LoRA training more effective.
The core idea running through all five:
You do not always need full fine-tuning to adapt a model.
LoRA updates two matrices.
LoRA-FA updates one.
LoRA+ updates two at different speeds.
Delta-LoRA lets W evolve - guided by low-rank deltas. VeRA updates two vectors.
Same goal. Five different answers to the same question:
=> What is the minimum we actually need to learn?
That is the core idea behind parameter-efficient fine-tuning.
And now you know what is actually happening inside the model.
RAG has evolved far beyond its original form.
When people hear Retrieval-Augmented Generation (RAG), they often think of the classic setup: retrieve documents → feed into LLM → generate an answer.
But in practice, RAG has branched into many specialized patterns, each designed to solve different challenges around accuracy, latency, compliance, and context.
Here are some of the most important categories:
➤ Standard RAG - the original retrieval + generation (RAG-Sequence, RAG-Token).
➤ Graph RAG - connects LLMs with knowledge graphs for structured reasoning.
➤ Memory-Augmented RAG - external memory for long-term context.
➤ Multi-Modal RAG - retrieves across text, images, audio, video.
➤ Streaming RAG - real-time retrieval for live data (tickers, logs).
➤ ODQA RAG - open-domain QA, one of the earliest and most popular uses.
➤ Domain-Specific RAG - tailored retrieval for legal, healthcare, or finance.
➤ Hybrid RAG - combines dense + sparse retrieval for higher recall.
➤ Self-RAG - lets the model reflect and refine before final output (Meta AI, 2023).
➤ HyDE (Hypothetical Document Embeddings) - improves retrieval by first generating “mock” documents to embed.
➤ Recursive / Multi-Step RAG - multi-hop retrieval + reasoning chains.
Others like Agentic RAG, Modular RAG, Knowledge-Enhanced RAG, Contextual RAG are best thought of as system design patterns, not strict categories, but useful extensions for specific use cases.
The image below maps out 16 different types of RAG, their features, benefits, applications, and tooling examples.
Whether you’re building production-grade assistants, domain-specific copilots, or real-time monitoring systems, the right flavor of RAG can make all the difference.
Instead of watching an hour of Netflix, watch this 60 minute lecture from Steve Jobs after being fired from Apple. It will teach you more about building companies than most startup books ever will.
Frameworks every developer learns
vs what actually runs the internet:
Everyone learns: React
What runs the internet: jQuery (still on 77% of sites)
Everyone learns: MongoDB
What runs the internet: PostgreSQL
Everyone learns: GraphQL
What runs the internet: REST APIs from 2015
Everyone learns: Kubernetes
What runs the internet: A single EC2 instance and a prayer
Everyone learns: Microservices
What runs the internet: A monolith nobody wants to touch
Everyone learns: Redis for caching
What runs the internet: Redis from a StackOverflow answer in 2019
Everyone learns: Docker
What runs the internet: "It works on my machine"
The gap between what gets taught
and what's actually running in production
is where most of your career happens.
Learn the modern stuff.
But don't be surprised when the job
involves something you've never heard of
doing something nobody fully understands.
Most people building AI agents are mixing up four distinct primitives — and it's causing architectures that break in production.
Skills. MCP. Hooks. Subagents.
Not the same thing. Not interchangeable. Each solves a different problem at a different layer of your agent stack.
Here's the complete mental model — and why it matters now more than ever.
━━━━━━━━━━━━━━━━━━━━
THE ONE-LINE VERSION
━━━━━━━━━━━━━━━━━━━━
𝗦𝗸𝗶𝗹𝗹𝘀 = WHAT to know
𝗠𝗖𝗣 = HOW to connect
𝗛𝗼𝗼𝗸𝘀 = WHEN to automate
𝗦𝘂𝗯𝗮𝗴𝗲𝗻𝘁𝘀 = WHO does the work
Now let's go deeper on each one.
━━━━━━━━━━━━━━━━━━━━
① SKILLS — The Knowledge Layer
━━━━━━━━━━━━━━━━━━━━
Skills are reusable instruction modules stored in your project and loaded on-demand by the agent.
They're not always in context. That's the point.
The agent reads metadata first, then loads full content only when needed. Progressive disclosure at the architecture level.
Think of them like training manuals for a new hire — they don't carry the entire employee handbook in their head. They know where to look.
Structure looks like this:
.claude/skills/
├── deploy/
│ └── SKILL.md
├── scripts/
└── code-review/
└── SKILL.md
Simon Willison called it well:
"Skills are awesome — maybe a bigger deal than MCP."
I think he's right. We've been obsessing over tools and under-investing in knowledge architecture.
━━━━━━━━━━━━━━━━━━━━
② MCP — The Connection Layer
━━━━━━━━━━━━━━━━━━━━
MCP (Model Context Protocol) is how your agent reaches the external world.
GitHub. Databases. Slack. REST APIs. File systems. Internal tools.
Think of MCP as the USB-C port of agentic AI. A universal interface that standardizes how agents connect to services.
We're now past 10,000+ MCP servers in the ecosystem. Linux Foundation took governance in 2026. MCP Apps are becoming interactive UIs in their own right.
This isn't niche infrastructure anymore. It's the connective tissue of enterprise AI.
━━━━━━━━━━━━━━━━━━━━
③ HOOKS — The Automation Layer
━━━━━━━━━━━━━━━━━━━━
Hooks are deterministic triggers — and they run outside the agent loop entirely.
Four types:
⚡ PRE-TOOL → runs before tool execution
⚡ POST-TOOL → runs after tool execution
⚡ ON-EDIT → fires when files change
⚡ ON-NOTIFICATION → alerts and logging
Critical distinction: the LLM does not control Hooks. You do.
That's why they're powerful for compliance, formatting, linting, and audit trails in enterprise contexts. Deterministic behavior you can actually rely on.
━━━━━━━━━━━━━━━━━━━━
④ SUBAGENTS — The Delegation Layer
━━━━━━━━━━━━━━━━━━━━
Subagents are independent workers, not threads.
Each runs in isolated context with its own model, its own permissions, its own scoped tools. The parent agent delegates — it doesn't micromanage.
Real example:
🤖 Subagent 1: Code Reviewer — Tools: Read, Grep
🤖 Subagent 2: Researcher — Tools: Search, Fetch
🤖 Subagent 3: Deployer — Tools: Bash, SSH
This is where genuine parallelism in agent systems comes from. And it's where most hobby-grade implementations fall short.
━━━━━━━━━━━━━━━━━━━━
THE FULL STACK
━━━━━━━━━━━━━━━━━━━━
Here's how all five layers compose together:
📦 PLUGINS
package layer — bundles everything
↓
📚 SKILLS
knowledge & workflows
↓
🔌 MCP + TOOLS
external connections | built-in capabilities
↓
🤖 SUBAGENTS
isolated execution
↓
⚡ HOOKS
deterministic automation
↓
📌 CLAUDE.md
always-on context
CLAUDE.md sits at the base. It's the sticky note on your monitor. Always loaded. Always in context. Project knowledge that never leaves.
━━━━━━━━━━━━━━━━━━━━
A REAL-WORLD FLOW
━━━━━━━━━━━━━━━━━━━━
Task: "Analyze competitors and write a report"
Here's what actually happens under the hood:
→ CLAUDE.md loads project context and company info
→ Skill activates the 'competitive-analysis' framework
→ MCP fires — searches Google Drive for past briefs
→ Subagent 1 spawns — market-researcher gathers live data
→ Subagent 2 spawns — technical-analyst reviews competitor repos
→ Hook triggers — auto-formats output and runs linter
No manual orchestration.
No prompt engineering duct tape.
No hoping the LLM figures it out.
Just a clean, composable architecture that scales.
━━━━━━━━━━━━━━━━━━━━
THE BOTTOM LINE
━━━━━━━━━━━━━━━━━━━━
The agents that will win in production aren't the ones with the smartest LLM at the center.
They're the ones with the cleanest separation of concerns between knowledge, connection, automation, and delegation.
Skills. MCP. Hooks. Subagents.
Get the primitives right. The rest follows.
——
What part of the agentic stack are you finding hardest to get right in production?
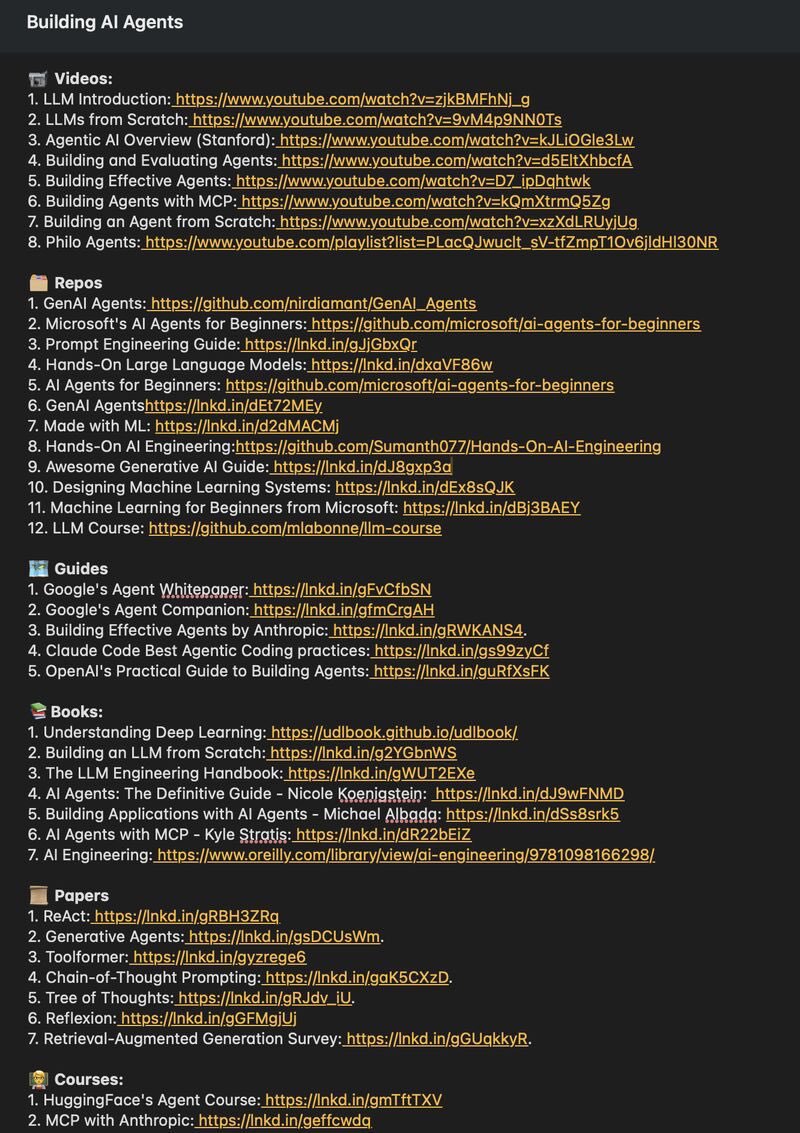
Stop wasting hours trying to learn AI.
I have already done it for you.
With one list. Zero confusion. And no fluff.
📹 Videos:
1. LLM Introduction: https://t.co/sfqLeUwf3W
2. LLMs from Scratch: https://t.co/GbnKbfvhcg
3. Agentic AI Overview (Stanford): https://t.co/EnqB4YMpeY
4. Building and Evaluating Agents: https://t.co/vp8RCDEoZP
5. Building Effective Agents: https://t.co/mngwlvMHna
6. Building Agents with MCP: https://t.co/TVk18pOf6Z
7. Building an Agent from Scratch: https://t.co/bfnRYfrFjd
8. Philo Agents: https://t.co/SQcGLseeM1
🗂️ Repos
1. GenAI Agents: https://t.co/cXJNVqPZqv
2. Microsoft's AI Agents for Beginners: https://t.co/WHiolowRZi
3. Prompt Engineering Guide: https://t.co/rVMK9vZfBJ
4. Hands-On Large Language Models: https://t.co/zpmaATDtdr
5. AI Agents for Beginners: https://t.co/WHiolowRZi
6. GenAI Agents: https://t.co/s9uA1N24PV
7. Made with ML: https://t.co/AKffs9HkUz
8. Hands-On AI Engineering: https://t.co/h9OVhJ3tWn
9. Awesome Generative AI Guide: https://t.co/lV1YMGL52R
10. Designing Machine Learning Systems: https://t.co/IUXQzlY97i
11. Machine Learning for Beginners from Microsoft: https://t.co/KrSHxdZMju
12. LLM Course: https://t.co/6U4Vww6Uyk
🗺️ Guides
1. Google's Agent Whitepaper: https://t.co/5Wpf7xvQqz
2. Google's Agent Companion: https://t.co/bVmjIK8Xam
3. Building Effective Agents by Anthropic: https://t.co/7SsNu6xr6Y
4. Claude Code Best Agentic Coding practices: https://t.co/X22UJOHlbC
5. OpenAI's Practical Guide to Building Agents: https://t.co/Bn5SYDT9KR
📚 Books:
1. Understanding Deep Learning: https://t.co/csAFkaw3Qp
2. Building an LLM from Scratch: https://t.co/72W4q5QV4z
3. The LLM Engineering Handbook: https://t.co/WgHM7dn8xq
4. AI Agents: The Definitive Guide - Nicole Koenigstein: https://t.co/2vXzCQXEqg
5. Building Applications with AI Agents - Michael Albada: https://t.co/MQAwMPbzQZ
6. AI Agents with MCP - Kyle Stratis: https://t.co/CcaNk01utK
7. AI Engineering: https://t.co/GD45IogK63
📜 Papers
1. ReAct: https://t.co/Nk77rLspmX
2. Generative Agents: https://t.co/CJEokZcGSw
3. Toolformer: https://t.co/GVKiIt2pj3
4. Chain-of-Thought Prompting: https://t.co/YyoEidCGMi
🧑🏫 Courses:
1. HuggingFace's Agent Course: https://t.co/288ifz8r9R
2. MCP with Anthropic: https://t.co/F07zf0lfXi
3. Building Vector Databases with Pinecone: https://t.co/6MFjlpTHab
4. Vector Databases from Embeddings to Apps: https://t.co/ngGDY3Rc7r
5. Agent Memory: https://t.co/BnlgGadL7o
Follow @iansh04_ for more!!
👇 Comment “AI” for more resources
Repost for your network ♻️
Bookmark for future.
Confused by all the AI Agent hype but don’t know where to start?
Here’s a roadmap that breaks it down into 7 clear stages to go from beginner to advanced in Agentic AI.
1. Start With the Basics
Understand what agents are, how they work, and the difference between chatbots, APIs, and multi-agent systems.
2. Master Prompt Engineering & Role Design
Learn how to build better agents with chain-of-thought reasoning, role-based prompts, and task-specific flows.
3. Add Memory & Context Handling
Move beyond short-term chats. Enable agents to remember, retrieve, and use past interactions to act smarter.
4. Enable Tool Use and Real-World Actions
Equip agents with the power to browse the web, send emails, query databases, and more via API tools.
5. Build Smarter, Reasoning Agents
Use multi-step planning, ReAct frameworks, and task decomposition to create self-correcting, goal-driven agents.
6. Launch Full Agent Ecosystems
Create advanced systems with agent collaboration, automation loops, fallback planning, and real business integration.
Save this roadmap. Share with your team. Whether you’re just starting or building real systems this guide has your back.
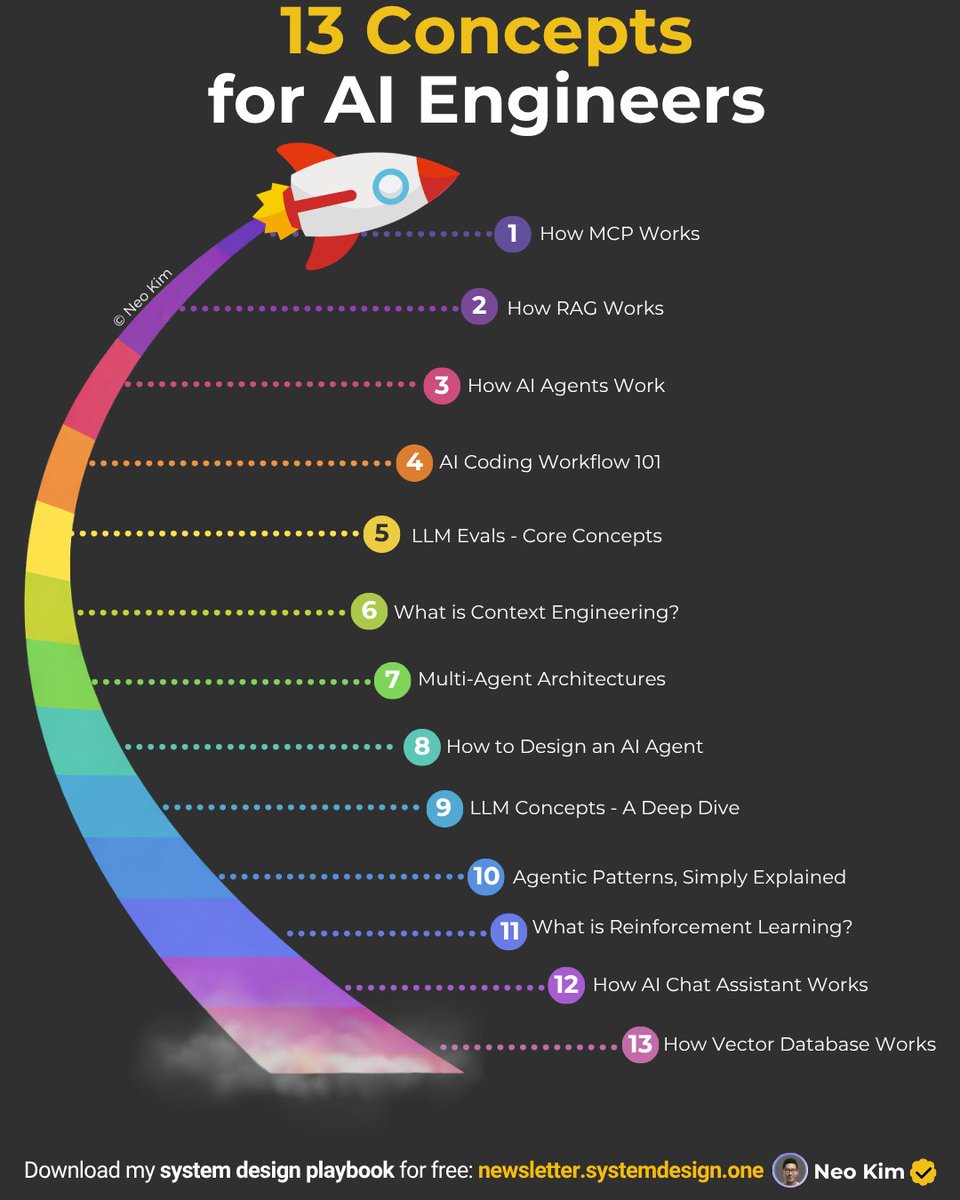
If you're serious about AI engineering (in 2026), then learn these 13 concepts:
1 How Vector Database Works
→ https://t.co/FVxan8xHH3
2 How RAG Works
→ https://t.co/cGmunPTUlb
3 Design Personal Chat Assistant
→ https://t.co/nNWq3onTnW
4 LLM Concepts - A Deep Dive
→ https://t.co/5lCKxq2g4N
5 How to Design an AI Agent
→ https://t.co/JvnPd9773A
6 What is Reinforcement Learning
→ https://t.co/AVpl9j1oit
7 LLM Evals 101
→ https://t.co/nv3Ol8W53p
8 Context Engineering 101
→ https://t.co/OMkiZhkODL
9 AI Coding Workflow 101
→ https://t.co/paIf9ksIU9
10 Agentic Patterns, Simply Explained
→ https://t.co/8YdBBWvTj1
11 How AI Agents Work
→ https://t.co/tk3zkCjRvg
12 Multi-Agent Architectures, Clearly Explained
→ https://t.co/rS5QQS7Jln
13 How MCP Works
→ https://t.co/wgf8gHnnkn
What else should make this list?
===
👋 PS - Want my System Design Playbook (for Free)?
Join my newsletter with 200K+ software engineers now:
→ https://t.co/ByOFTtOihX
===
💾 Save now & repost to help others learn AI engineering.
👤 Follow @systemdesignone + turn on notifications.