@NeurIPSConf Just drop this policy. You're a US academic press. You have a 1st Amendment RIGHT to publish whatever you want—including words written by individuals who are disfavored by your government, and reviews of those words. They can't constitutionally stop you. If they try, go to court!
@JAldrichPL@HerrDreyer@TaliaRinger@krismicinski Being in New York actually guarantees that you are *free* from such laws. ACM is an academic press: I trust it will stand up for its First Amendment press freedoms. So should NeurIPS. All the "services" they mention are forms of conveying speech! They can't be prohibited.
@JonathanWenger5@sirbayes@docmilanfar My version of this (suggested to colleagues last week):
The conference should modify the PDFs on OpenReview to include an invisible instruction to include a particular unusual phrase in the review. Reviews containing this phrase were probably written by AI.
Congratulations to all @JohnsHopkins researchers participating in #ICLR2025! Check out all @JohnsHopkins accepted papers, tutorials, and workshops at https://t.co/0XMBTXoPNf.
Who wants to come to JHU and do a postdoc with me?? I'm always enthusiastic about new modeling / inference / algorithmic ideas in NLP/ML. Also selected applications.
We’re thrilled to announce the #HopkinsDSAI Postdoctoral Fellowship Program! We’re looking for candidates across all areas of data science and AI, including science, health, medicine, the humanities, engineering, policy, and ethics.
Apply today!
https://t.co/e7ukJR8Tun
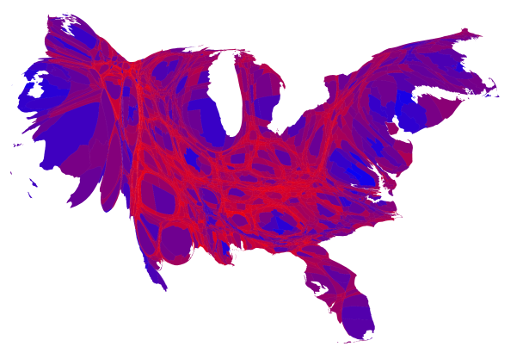
@nominalthoughts@cremieuxrecueil Great, thanks. Here are several additional ways to visualize the popular vote in a way that is not distorted by land area (2016 election):
https://t.co/aIzlShie2N
https://t.co/PGc00nPZ7d
@dmimno@AaronSchein I also tell them that a lexicon is a collection of types, and a corpus is a collection of tokens.
Counts, probs, defs are properties of types. So are sales, prices, reviews.
But it's tokens that are being counted or sold, and that affect their various audiences (contextually).
@dmimno@AaronSchein I ask them: If you ask at the bookstore how many Jane Austen novels they have in stock, should they answer 250 or 'all 6'? Let's disambiguate…
And next day, I point out that add-1 unigram smoothing modifies the denom of an estimated probability from `tokens` to `tokens+types`.
@AaronSchein In short, "atom" in the Good Place can be used for both atom tokens and atom types. So it's not surprising that here in the Bad Place, "token" is used to mean both token types (the things that have embeddings) and token tokens (the things that you pay OpenAI for). Agree?
@AaronSchein The Good Place code shows that a variable `atom: Atom` may be used to represent either an atom token or an atom type. (At least in the design where an atom token is simply a string whose context is supplied externally -- rather than an object containing a pointer to its context.)
Used cryptocurrency to purchase one of my fave philosophical ideas: The Type/Token Distinction!
My NFT certifies my Sole Ownership of the Platonic Idea.
But it can't stop you from using the idea as many times as you want (0, 1, 2, …).
SEE THE DISTINCTION?
https://t.co/Jg87geKWi0
@mdredze The 1960's compilers folks used "token" (and "type"!) differently from Pierce (1906).
Regrettably, NLP adopted their term "tokenizer" anyway. If we called it an "atomizer", then subwords etc. would be "atoms," and we could distinguish "atom types" from "atom tokens" when needed.
New #ACL2024 paper: LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error (@BoshiWang2's internship work at Microsoft Semantic Machines)
I like this work because it takes home an important insight: synthetic data + post-training is critical for agents.
Agents need perception-decision-execution capability and data, which is hard to get from pre-training because data on the Internet is mostly artifacts produced by such processes, not capturing the processes per se. I believe LLMs + synthetic data + environmental feedback will prove to be an immensively successful recipe for agents, and our work is just an early example of that.
Nice work @BoshiWang2@hfang90@adveisner@ben_vandurme