Anthropic engineer: "You're not supposed to prompt Claude. You're supposed to build a system that prompts itself."
Loops.
Most builders are doing this wrong:
No memory file, so every loop starts from zero.
No sub-agent split, so one agent tries to do everything.
No stop condition, so loops run forever and bill you in your sleep.
Most builders are missing at least two of the three.
Watch the video first.
Then read this - everything you need to know about Loops in 2026, in one place.
Bookmark this before it gets buried.
Un desarrollador chino llamado tw93 se hartó de que sus aplicaciones de escritorio le devoraran la RAM y el disco.
Abría Slack y desaparecían cientos de megabytes. Abría Discord, Notion o cualquier otra app y pasaba lo mismo. ¿La razón? Casi todas son lo mismo por dentro: un sitio web empaquetado con una copia completa del motor de Chrome (Electron).
Decidió que tenía que haber una forma mejor.
En 2022 empezó a construir Pake. Usó Rust + Tauri, que en vez de incluir un navegador completo, aprovecha el WebView nativo del sistema operativo.
El resultado fue brutal:
- Slack con Pake → 8 MB (en vez de 524 MB)
- Discord con Pake → 9 MB (en vez de 265 MB)
- ChatGPT con Pake → 9 MB (en vez de 260 MB)
Cuatro años después, su repositorio tiene más de 51.000 estrellas en GitHub. Tiene builds listos para Grok, ChatGPT, Gemini, Discord, YouTube, Twitter y muchos más. Todo bajo los 10 MB, ligero, rápido y gratis.
Y lo mejor: con un solo comando puedes convertir cualquier página web en una aplicación de escritorio nativa.
No fundó una startup. No levantó inversión. Solo resolvió un problema que molestaba a millones de personas.
A veces el cambio real lo hace una sola persona que se cansa de las cosas como están.
Esta brutal, repo en los comentarios 👇
Andrej Karpathy spent 70 minutes breaking down how top AI users actually work with LLMs.
The reality is simpler than people expect. You tell the model what you want in plain language and let it run.
No 40-line system prompts. No secret tricks.
By 2026 the engineer who writes off LLMs loses to the junior who just set one up properly.
70 minutes. Free. A rare straight look from an OpenAI co-founder.
Bookmark it and watch.
A developer in China named tw93 got tired of his laptop dying.
He would open Slack and watch 524 megabytes of disk space disappear. He would open Discord and watch another 265. He would open Notion and watch 800 megabytes of RAM evaporate before he had typed a single word.
He looked into why.
Every "desktop app" on his computer was the same thing. A website wrapped in a full copy of the Chrome browser engine. The framework is called Electron. An empty Electron app starts at 150 megabytes of RAM before you click anything. With twelve of them open, his laptop was running twelve copies of the same browser.
He thought there had to be a better way.
So in 2022, he started building one.
He called it Pake. Two characters in Chinese mean "packaging." He wrote it in Rust on top of a framework called Tauri. The idea was simple. Point Pake at any webpage. Get a desktop app. Without dragging an entire browser engine into the binary.
The first version of Slack he wrapped with it was 8 megabytes.
Not 524. Eight.
That is what 20 times smaller looks like.
Four years later, his repo has 50,594 stars. 6,144 forks. The license is MIT. The last commit was yesterday.
The bio on his GitHub reads: "Anything added dilutes everything else."
Today the Pake releases page contains pre-built apps for ChatGPT, Discord, Gemini, Grok, DeepSeek, Twitter, YouTube, Excalidraw, Flomo, WeChat, and twelve more. All under 10 megabytes. All native. All free.
Or you point Pake at any URL you want and it builds one for you in one command.
Slack's desktop app: 524 megabytes.
Pake-built Slack: 8 megabytes.
Discord's desktop app: 265 megabytes.
Pake-built Discord: 9 megabytes.
ChatGPT for Windows: 260 megabytes.
Pake-built ChatGPT: 9 megabytes.
tw93 is one person. He has 11,305 followers on GitHub. He runs a blog at https://t.co/WZoyHop8Id. He has shipped 39 public repos. He still pushes commits to Pake every week.
He did not start a company. He did not raise money. He did not write a Medium post about how Electron is dead.
He just shipped the thing that made it true.
(Link in the comments)
UP TO 95% TOKEN REDUCTION WITH ZERO CODE CHANGES
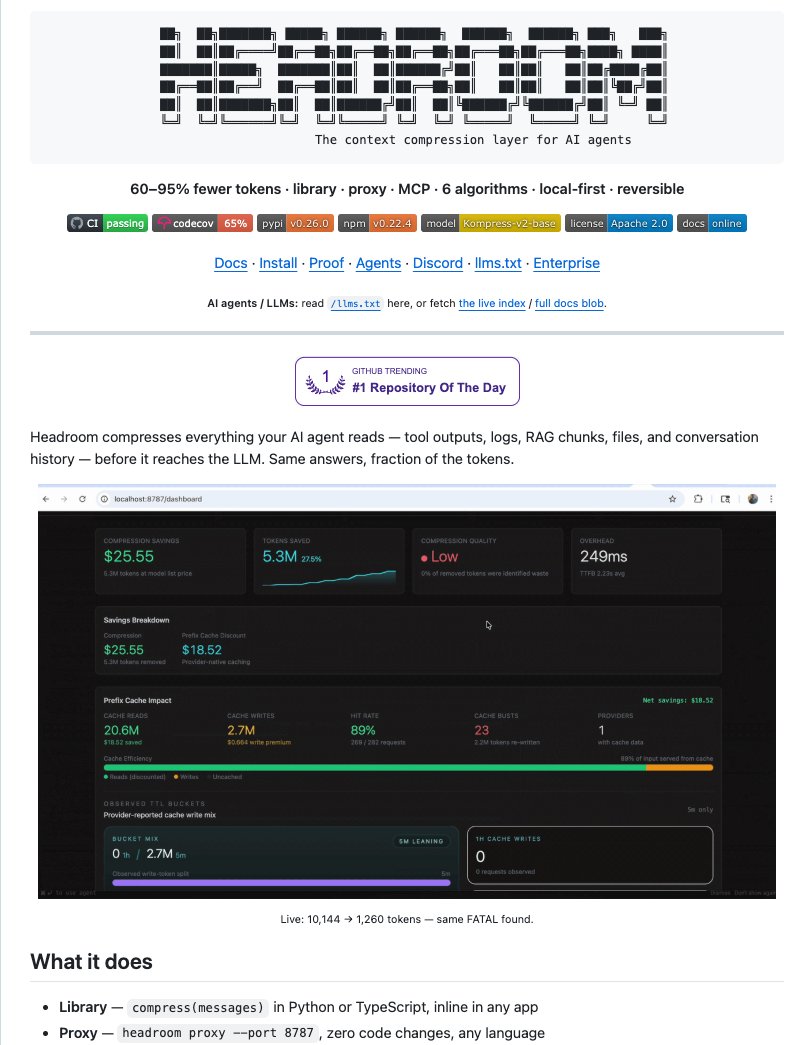
A Netflix engineer just open-sourced Headroom, and it’s one of the smartest ways I’ve seen to cut LLM costs.
It wraps Cursor or Claude in a local proxy to compress your payload before it hits the LLM:
→ Intelligently shrinks logs, JSON, and code
→ Perfectly preserves logic accuracy
→ Keeps 100% of your data local
→ Stops Opus-tier models from wasting tokens on boilerplate
It already crossed 35K stars, which says a lot.
100% free and open-source.
repo in 🧵↓
Google ha acabado con la mafia de las GPU 💀
VS Code ahora se conecta directamente a Google Colab.
→ Obtienes una GPU T4 gratuita dentro de tu editor.
→ Tus archivos locales. Su potencia de cómputo.
10 TOOLS ON GITHUB THAT FEEL ILLEGAL TO BE FREE
Bookmark every single one. Each one does something that looks like it should cost money, require a login, or get someone sued. All free.
1. https://t.co/PKb3pEQw5n
Download video or audio from YouTube and 1,800+ other sites straight to your drive, full quality, with subtitles and metadata. 171K stars and a new release every two weeks because YouTube keeps trying to break it and it keeps winning. The Unlicense, which means it's freer than free.
2. https://t.co/j7Qed5Kzq2
Every Adobe Acrobat feature, merge, split, sign, OCR, compress, redact, convert, running on your own machine so no file ever uploads anywhere. A UK dev built it in a day because he refused to pay Adobe just to sign a PDF. 78K stars, 25 million downloads. MIT.
3. https://t.co/RE1H55WHIF
A gorgeous dashboard that pulls live status from every service and app you run into one screen, the kind of control panel companies pay for. Free, self-hosted, and it makes your setup look like a NASA console. The thing that ties your whole stack together.
4. https://t.co/8gWTZZIXyM
AirDrop for every device. Send files between Windows, Mac, Linux, Android, and iOS over your own network with no account, no cloud, no size limit. Apple locked their best version inside their ecosystem. This one works on everything and costs nothing.
5. https://t.co/1RBMSQu38m
The entire Notion, rebuilt open-source and offline-first, so your notes, docs, and databases live on your machine instead of a company's server. Notion is valued at $10 billion. This does the core of it for free and never sells your data. 60K+ stars.
6. https://t.co/Qm55OR5YI1
Google Photos on hardware you own. Phone auto-backup, face recognition, AI search, shared albums, all of it, while Google stops mining your family photos to train its models. The single most satisfying thing to self-host, and people who try it never go back.
7. https://t.co/B57eBygDK6
Build unlimited professional resumes, host them, track them, all free and private, while every resume site online charges you the moment you hit download. 30K+ stars. The paywall that wastes job seekers' money, deleted.
8. https://t.co/zajmBsDn9M
OpenAI's own speech-to-text model, free to run, transcribing 99 languages at the accuracy that Otter, Rev, and Descript literally charge per minute for. The exact engine inside the paid apps, sitting on your laptop for $0. MIT.
9. https://t.co/13hzF0PW7N
Connect any app to any other app and automate entire workflows, the thing Zapier charges by the task for. Hundreds of integrations, self-hosted, running on your own server with no per-action fee. The automation tax, gone. 100K+ stars.
10. https://t.co/TyOTBGduto
Turn any website into clean, structured data an AI can read, in one call. The kind of scraping infrastructure companies sell for hundreds a month, open-sourced. Point it at a site, get back exactly what you need. The frontier devs are already building on it.
Free was always the default. Someone just had to build it.
Si tuviera un fin de semana para dominar Claude, empezaría aquí: https://t.co/nepfUQW21c
Deja de guardar 50 guías que nunca vas a leer. Estas son las únicas que importan:
(algunas guías son del jefe Ruben Hassid)
→ Nivel 1 - 17 min: Lo básico.
Claude For Dummies: https://t.co/jlB6IzTaHs
Claude Setup: https://t.co/f1oUvNtNAP
→ Nivel 2 - 1 hora: Flujos de trabajo reales.
Claude Cowork: https://t.co/7jjWe01ZWl
Claude para equipos: https://t.co/z7LEpf9xjr
Claude Design: https://t.co/GCAe64H6AG
Cowork + Projects: https://t.co/O218wA4Sb7
Claude para presentaciones: https://t.co/4M4gX7XCZY
Claude Skills: https://t.co/JsPA2rybvA
→ Nivel 3 - 3,5 horas: Nivel pro.
Evitar la adulación: https://t.co/iRp6XiQtdR
Claude Code: https://t.co/8KRFXLfJ2f
Claude 101: https://t.co/nMFE3CkP55
Deja de alcanzar los límites de Claude: https://t.co/EUtqndF4Y7
Deja de hacer prompting: https://t.co/hXgc6s1sFi
→ Nivel 6 - 8 horas: Modo experto.
Claude Computer: https://t.co/NrFSyiRC3d
Construir con la API de Claude: https://t.co/S4D13vdRJG
Web scraping will never be the same.
(100% open-source visual search at scale)
PixelRAG is a retrieval system that skips HTML parsing completely.
Instead of scraping a page into text and embedding chunks, it screenshots the page and retrieves the image. A vision-language model reads the answer straight off the pixels.
Why that matters: parsing is where web RAG quietly loses information.
- A single HTML-to-text parser can drop 40%+ of a page.
- Tables, charts, and layout get flattened or thrown out.
- Swapping parsers alone can move accuracy ~10 points on the same docs.
PixelRAG indexes the page a person actually sees. The team built a visual index of all of Wikipedia, 30M+ screenshots, and it still beats the strongest text RAG baseline by 18.1% on text-only QA.
The repo also ships a Claude Code plugin that gives Claude eyes.
It lets Claude screenshot any URL and read the rendered page instead of scraping the DOM. So you can hand it a live page, an arXiv paper, or your local site and ask what it actually looks like.
One setup script. No MCP server, no backend.
How the pipeline works:
- Renders each document (web, PDF, image) to image tiles.
- Embeds them with Qwen3-VL-Embedding, LoRA fine-tuned on screenshots.
- Builds a FAISS index and serves a search API.
A stronger reader model lifts accuracy with no re-indexing, since the index is just pixels.
Everything is open-source under Apache-2.0.
GitHub repo: https://t.co/qun9TjAdmw
Talking about RAG, I recently wrote an article on a new approach that makes retrieval much more efficient by cutting corpus size by 40x, reducing tokens per query by 3x, and improving vector search relevance by 2.3x.
The article is quoted below.
Un ingeniero de Netflix ha sacado algo tremendo.
¡Promete ahorrarte hasta el 95% de los tokens!
¿Cómo? Comprime tu contexto antes de enviarlo a la IA.
100% en local y compatible con Claude, Cursor, Codex...
24K estrellas en GitHub:
https://t.co/v4Ka8gmGV9
🚨 A Netflix engineer built an open-source proxy that cuts AI token usage by 60-95%.
Zero code changes.
Benchmarks show ±0.000 accuracy regression.
✨ 29.9k stars on GitHub.
It sits between your app and the LLM, so every tool output, code block, and conversation history gets compressed in-flight.
🚫 No summarization, no loss.
😎 Just 60-95% fewer tokens with the same answers.
Works with Claude Code, Cursor, Copilot, and any OpenAI-compatible client.
One pip install, one env var, done.
Netflix uses it internally.
Apache 2.0.
Built by Tejas Chopra.
https://t.co/u1OIlMF5gm
Someone just dropped a 9-layer production AI architecture and it's the most honest breakdown I've seen.
services/ - RAG pipeline, semantic cache, memory, query rewriter, router. Not one file. Five.
agents/ - document grader, decomposer, adaptive router. Self-correcting by design.
prompts/ - versioned, typed, registered. Never hardcoded.
security/ - input, content, output. Three guards not one.
evaluation/ - golden dataset, offline eval, online monitor. Most people skip this entire layer and ship blind.
observability/ - per-stage tracing, feedback linked to traces, cost per query.
.claude/ - agent context so your AI coding assistant knows the codebase before it touches a file.
The demo is one file. Production is this.
Check: academy[.]neosage[.]io
Andrej Karpathy: "90% of Claude's mistakes come from missing context, not a weak model."
41% mistake rate without a CLAUDE.md. 11% with the 4-rule baseline. 3% with the 12-rule version below
here are the 12 rules senior engineers settled on:
1. think before coding: state assumptions, don't guess. the model can't read your mind, stop hoping it will
2. simplicity first: minimum code, no speculative abstractions. the moment you let Claude add "for future flexibility," you've added 200 lines you'll delete next quarter
3. surgical changes: touch only what you must. don't let it improve adjacent code, that's how PRs blow up
4. goal-driven execution: define success criteria upfront, loop until verified. without them Claude either loops forever or stops too early
5. use the model only for judgment calls: classification, drafting, summarization, extraction. NOT routing, retries, status-code handling, deterministic transforms. if code can answer, code answers
6. token budgets are not advisory: per-task 4000, per-session 30000. by message 40 of a long debug, Claude is re-suggesting fixes you rejected at message 5
7. surface conflicts, don't average them: two patterns in the codebase? pick one. Claude blending them is how errors get swallowed twice
8. read before you write: read exports, callers, shared utilities. Claude will happily add a duplicate function next to an identical one it never read
9. tests verify intent, not just behavior: a test that can't fail when business logic changes is wrong. all 12 of Claude's tests can pass while the function returns a constant
10. checkpoint every significant step: Claude finished steps 5 and 6 on top of a broken state from step 4. nobody noticed for an hour
11. match the codebase conventions: class components? don't fork to hooks silently. testing patterns assumed componentDidMount, hooks broke them without surfacing
12. fail loud: "completed successfully" with 14% of records silently skipped is the worst class of bug. surface uncertainty, don't hide it
what actually compounds instead of the next framework:
- the CLAUDE.md file as institutional memory across sessions
- eval-driven changes, not vibe-driven
- checkpoints over speed
- explicit conflicts over silent blending
- discipline over framework, every time
- one repo, one rules file, no exceptions
you don't need a better AI
you need better context engineering
complete playbook below ↓









































![techNmak's tweet photo. Someone just dropped a 9-layer production AI architecture and it's the most honest breakdown I've seen.
services/ - RAG pipeline, semantic cache, memory, query rewriter, router. Not one file. Five.
agents/ - document grader, decomposer, adaptive router. Self-correcting by design.
prompts/ - versioned, typed, registered. Never hardcoded.
security/ - input, content, output. Three guards not one.
evaluation/ - golden dataset, offline eval, online monitor. Most people skip this entire layer and ship blind.
observability/ - per-stage tracing, feedback linked to traces, cost per query.
.claude/ - agent context so your AI coding assistant knows the codebase before it touches a file.
The demo is one file. Production is this.
Check: academy[.]neosage[.]io](https://pbs.twimg.com/media/HLBxYSCbEAAz5OC.jpg)



















