We’ve automated every single thing we can @every with AI agents.
And yet there’s way more human work to do than ever. We’ve gone from 4 -> 30 human employees since GPT-3.
I wrote a report on the structural reasons: how AI makes expert competence cheap, why that drives up demand for experts, and why the dynamic only intensifies as we approach AGI.
After Automation: https://t.co/Lb7SUCduAg
Today we reduced headcount by 22%. The business is the strongest it's ever been. So I think it's important to be direct about what I'm seeing and why.
First, I made this decision and I own it. I did it because the way to operate at the highest level of productivity is changing, and to win the future, ClickUp needs to change with it.
Second, this wasn't about cutting costs. Most savings from this change will flow directly back into the people who stay. We'll be introducing million-dollar salary bands. If you create outsized impact using AI, you'll be paid outside of traditional bands.
Most importantly, I have the deepest gratitude for those affected. We're doing this from a position of strength specifically so we can take care of people properly. Everyone affected receives a package aimed at honoring their contributions and easing the transition.
I only see two options: wait for this to play out gradually in the market or be honest about what I'm seeing and act proactively.
THE 100X ORGANIZATION
The primary change is that we're restructuring around what I call 100x org. The goal is 100x output. The roles required to build at the highest level are fundamentally different than they were a year ago.
Incremental improvements to existing systems won't get us there. We need new ones. That means creating enough disruption to rebuild rather than iterate on what's already broken.
The common narrative is that AI makes everyone more productive. It doesn't. Many of the workflows of today, if left unchanged, create bottlenecks in AI systems.
These roles will evolve. But waiting for that to happen naturally means falling behind now.
The 100x org is actually heavily dependent on people - infinitely more than today. This is only possible with 10x people that have embraced and adopted new ways of working.
THE BUILDERS, AGENT MANAGERS, AND FRONT-LINERS
— THE BUILDERS: 10X ENGINEERS
I don't think most companies have internalized what's actually happening with AI in engineering. The common narrative is that AI makes all engineers more productive. That may be true in isolation, but at an organization level - that is the farthest thing from reality.
Here's what we've validated recently at ClickUp: the great engineers, the ones who can orchestrate, architect, and review, are becoming 100x engineers. They're not writing code. They're directing agents that write code. The skill is judgment.
AI makes the best engineers wildly more productive, and everyone else using AI slows these engineers down.
Think about it - the bottlenecks are (1) orchestration - telling AI what to do, and (2) reviewing - what AI did. Everything is leapfrogged and no longer needed.
So who do you want orchestrating and reviewing code?
And how do you want your best engineers to spend their time?
If your best engineers are spending time reviewing other people's code, then this is inherently an inefficient bottleneck. These engineers can review their agent's code much faster than reviewing human code.
The new world is about enabling your 10x engineers to become 100x.
The wrong strategy is to push every engineer to use infinite tokens. Companies doing this are celebrating 500% more pull requests. But customer outcomes don't match the volume of code being generated.
I call this the great reckoning of AI coding, and every company will face this soon if not already.
More code is just another bottleneck to the best engineers, and ultimately to your company's impact as well.
— THE BUILDERS: 10X PRODUCT MANAGERS
Product management and design roles are merging.
Designers that have customer focus, become more like product managers.
And product managers that have intuition for UX become more like designers.
The bottleneck of user research is gone. It takes us just one mention of an agent to kickoff research and analyze results.
The bottleneck of product <> design iteration is also gone. The product builder iterates on their own, along with agents and skills that ensure alignment with quality and strategy.
Also controversial today - I believe that the wrong strategy is to have your PMs shipping code - that just introduces another bottleneck that the best engineers will waste their time on.
To be clear, PMs should be coding but they should do this in a playground to iterate, validate, and scope. That code should not go to production.
Everything outside of managing systems, orchestrating AI, and reviewing output becomes a bottleneck.
That's why the other roles that are critical along with these are the systems managers (to reduce bottlenecks) along with a bottleneck you can't replace - customer meeting time.
— THE SYSTEM MANAGERS
Ironically, the people that automate their jobs with AI will always have a job. They become owners of the AI systems - agent managers. We have many examples of these people at ClickUp.
The underlying systems in which we operate are absolutely critical to get right. I think most companies are delusional to think they can iterate on existing systems and compete in this new world.
You must create enough disruption so that old systems are deprecated entirely. If there's any definition for 'AI native' that's what it is.
— THE FRONT-LINERS
In a world that will become saturated with AI communication, the human touch will matter more than anything to customers.
This is a bottleneck that you shouldn't replace - even when agents are high enough quality to do video meetings.
One-on-one meeting time with customers is something that shouldn't be automated. The systems around the meetings should be - so that front-liners spend nearly 100% of their time with customers.
REWARDING 100X IMPACT
In a world where companies are able to do so much more with less, where does that excess money go?
In our case, much of the savings in this new operating model will flow directly back to those that enabled it.
We must reward people that create productivity accordingly. This aligns incentives on both sides. Plus, in a world where your best people create 100x impact, you can't afford to lose them.
You should aim to retain these employees for decades. The context they have and their ability to efficiently orchestrate and review will be nearly impossible to replace.
Compensation bands of today should be thrown out the door. We're introducing $1 million cash/year salary bands with a path available to nearly everyone in the company if they produce 100x impact by creating or managing AI systems.
THE FUTURE
Nearly every company will make changes like these. The ones that do it proactively will define what comes next.
The future is not fewer people. It's different work, new roles, and better rewards for those who embrace it. We're already seeing entirely new roles emerge, like Agent Managers, that didn't exist a year ago.
ClickUp is positioning to lead this shift, not just internally, but for our customers too. I've never been more certain about where we're headed.
Xynth can now scan the stock market for you 24/7 !
Simply describe what you want monitored in plain English.
Under the hood, we wire Claude Opus 4.7 + Python to 3,000+ live market endpoints to build your custom alert.
The workflow lives in the cloud, hunting your setup the moment it hits.
As part of this launch, we're giving free access to the top 5 most profitable alerts built so far.
RT + comment "Xynth" below to get access ↓
Basic hedge fund economics 🧵. N.B.:
1. for educational purposes only and I will keep it super-simple
2. ofc, personal views
3. No soliciting! I am not coming to defend hedge funds, just to explain some basics. And I am not going to answer replies on the Current Thing.
1/
Large Language Models, How to Train Them, and xAI’s Grok
When OpenAI released ChatGPT in November 2022, it took the world by storm, reaching over a million users in only 5 days. This kind of viral attention was previously unheard of in AI, driven by how closely the underlying language model seemed to replicate human intelligence.
Since then, there has been an explosion in AI activity, ranging from applications built on top of ChatGPT which seek to improve efficiency for mundane tasks, to new chatbots like xAI’s Grok which aim to replace ChatGPT altogether.
This explosion happened so quickly that few of us really took a step back to understand the basics. So we wanted to sit down and understand how LLMs work to figure out how new entrants like xAI will compete.
So what is an LLM?
A large language model is a type of neural network that can ingest strings of text and then predict the next sequence of words. Intelligent chatbots like ChatGPT are specialized versions of these language models that have been trained for the specific purpose of generating responses to questions.
To understand and generate text like humans, there are a few things that language models must be able to do:
1. Understand the meanings of various words
2. Understand the context of words in relation to other words
3. Remember long strings of these words
4. Do all of the above very quickly
Until recently, even the best-in-class language models struggled to do all four. They were either slow and inefficient to train, had poor memory, or were bad at recognizing context. This resulted in models that failed to effectively replicate human abilities.
In 2017, a new type of architecture called a “transformer” was introduced that promised to solve many of these issues. Two key breakthroughs, “positional encoding” and “self-attention” made this architecture much more efficient to train and better at recognizing the context of words.
As language models were trained with more compute power and data using this architecture, new capabilities emerged. Today, models can reason about topics, write code, and even understand information across multiple modalities including images and audio.
But how do LLMs work?
LLMs work by first taking a string of words and representing them as sequences of numbers called vectors. Each number within the vector captures the meaning of a word in relation to other words. Think of this like a graph. When two words are closely related, they’re mapped closely together.
The position of each word in the sentence is also represented as a vector, allowing the model to capture context without needing to process each word serially - a key development that made transformers much more efficient than previous models.
The “self attention” layer, which is what transformer models are known for, then allows the model to hone in on relevant words to further improve contextual awareness. Take the following sentence:
“Yesterday, I went to the bank to deposit money.”
The word “money” allows the model to understand that the sentence refers to a money bank, not a river bank.
So how do you build an LLM?
Large language models like ChatGPT and Grok are built in two key stages:
1. The training stage, which feeds the model billions (and often trillions) of words so that the model can learn what different words mean and how closely they are related, with the goal of eventually generating text by predicting the next word.
2. The fine-tuning stage, which trains this pre-trained model to perform a particular kind of task like answering questions.
Stage 1: Training the model
To train a language model to generate text, you first need to collect a massive amount of data on which to teach the model to predict the next word. This is achieved by scraping the internet for text data from a diverse range of sources, and then cleaning this up to remove duplicates, spelling errors and issues that you don’t want the model to learn.
Once the training dataset is assembled, it is then turned into a series of incomplete sentences that are used to train the model to predict the next word.
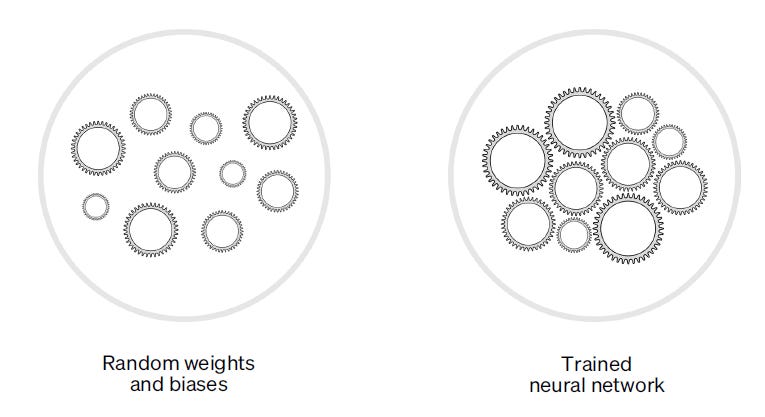
Language models are types of neural networks that use layers of nodes to generate their predictions. Nodes are like gears in a machine. Individually, they lack meaning, but when trained to work together, nodes can understand and interpret complex data like language.
Initially, the connections between nodes will be assembled randomly, so the model’s prediction will also be random. But as the model is trained, the nodes learn to predict the output that we want to see by adjusting the weights and biases that connect them together.
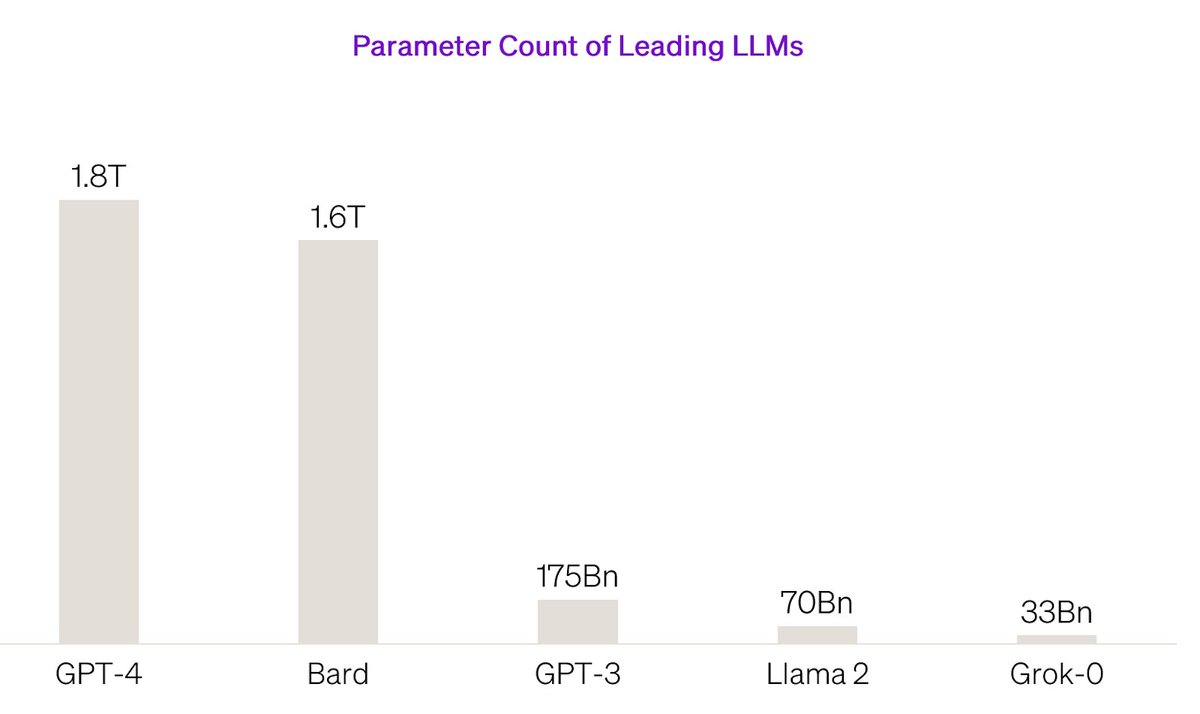
The number of weights and biases that a model uses to make a prediction is called its “parameters”. The more parameters there are, the more complex the model. While this often leads to better performance, it also comes at the cost of higher latency and computational demand. Newer language models like Grok aim to outperform larger models using fewer parameters by improving on the architecture of models and leveraging higher quality training data.
During the training process, the language model learns to map the relationships between words and predict the next word in a sequence. But it still needs to learn how to perform specific tasks like responding to questions. This is the role of fine-tuning.
Stage 2: Fine-tuning the model
To build a chatbot that can respond to questions, pre-trained models are trained on thousands of examples of prompts in the desired question-answer format until the model can predict an appropriate response to a given question.
Then, once the model can predict answers in the desired format, human feedback is used to rank several of the model’s possible responses from best to worst in a process called “reinforcement learning from human feedback” (RLHF). This feedback is used to train a second “reward model” to guide the LLM to predict the best response.
Companies building new language models today face two major challenges. The first is that exponential increases in the amount of data used to train a new model only result in linear improvements in performance. So with an abundance of data available for training, all else equal, models eventually converge towards a single level of performance.
The second is a lack of context. Many models like ChatGPT lack context beyond their training period, meaning that they have no awareness of information and events beyond a given date. When asked about information after this period, they either refuse to answer, or worse still, hallucinate and provide a convincing but made-up response.
So, if you want to build a chatbot that is constantly improving and context-aware, how do you do it?
A new entrant to the race: xAI and Grok
xAI launched its new chatbot Grok on November 4th, 2023, just four months after the company was officially announced. Grok’s initial model, Grok-0, demonstrated impressive performance with limited resources, directly competing with Meta’s LLaMA 2 model using half the complexity (70 billion vs. 33 billion parameters). Its next iteration, Grok-1, showcased even better results, surpassing all other models in its compute class including GPT-3.5, which took OpenAI several years to achieve.
What makes xAI’s model unique is its access to a proprietary and constantly-evolving dataset of tweet activity, which generates over 12 terabytes of data daily, containing extensive data on human interactions and current events in multiple formats (text, images and even audio), and distributing its model to an existing user-base of more than 500mm MAUs on X.
Access to this dataset of constantly updated information can help to minimize hallucinations and provide more context-aware responses when presented with questions about recent events. xAI can quickly retrieve information from reputable sources on X, and use the wisdom of crowds to interpret the sentiment around a given topic, allowing the model to provide more context-aware responses to queries.
Having access to this data in multiple formats such as images and audio can also help xAI’s model achieve a deeper and more nuanced understanding of the world. For example, understanding a person’s facial expressions while they are speaking results in a much richer interpretation of their speech than just an audio recording. In the same way, leveraging multi-modal inputs on X can help xAI’s model to better understand the context of news and other world events.
The final differentiator is distribution. xAI already has built-in distribution through the X platform, which has more than 500mm monthly active users. Assuming modest uptake, this allows xAI to rapidly improve its models through much faster reinforcement learning from human feedback loops than other models, providing the company with another set of proprietary data that can help propel its model further than competitors.
Conclusion:
As the foundational layer of language models is becoming increasingly difficult to improve with more data, the quality of the data that these models are trained on becomes a key differentiator. xAI’s Grok benefits from a vast dataset of diverse and up-to-date information in multiple formats, as well as a pre-existing user base of 500mm people to rapidly improve its models. With high quality real-time data and the capital to scale, Grok has the opportunity to become the most up-to-date, customizable and context-aware language model in the race to achieve AGI.
Disclaimer: The views and opinions expressed above are current as of the date of this document and are subject to change without notice. Materials referenced above will be provided for educational purposes only. None of the above will include investment advice, a recommendation or an offer to sell, or a solicitation of an offer to buy, any securities or investment products.
Remember when Binance released proof of reserves to calm the market?
Well, the accounting firm that helped with that, Mazars Group, deleted the proof of reserves from its website.
And Mazars Group is pausing all work with Binance and its other crypto clients.