Friends, followers, and strangers on X,
I recently got excited about mapping the jagged frontier of AI models in math and other STEM areas. With my colleague Prof. Rob Ghrist @prof_g , I founded Rabdos AI https://t.co/7fbOZgoCz1 to create original, research-level problems at scale to advance frontier AI capabilities.
In the coming weeks, we'll be sharing exciting technical updates through @Rabdos_AI. Please give us a follow if you're interested in model evaluation, AI for math/science, autoformalization in Lean, robustness of world models, and much more.
THE SYMPOSIUM PUZZLE:
The final dinner of the symposium was less a banquet than a convergence theorem that had failed to be uniform. Five luminaries -- Hardy, Poincaré, von Neumann, Gödel, and Ramanujan -- sat in a row at the head table, each in a different jacket, each with a different drink, each newly returned from a different lecture tour, and each guarding a different mathematical instrument as though it were a proof of the Riemann Hypothesis.
Hardy sat brooding at the far left in herringbone, one hand curled around an espresso, the other resting upon an antique abacus whose beads he refused, on principle, to move. Immediately to his right sat a severe scholar in charcoal, upright as a metronome and no more companionable.
Poincaré, ever the classicist, wore tweed. Farther down the line, Ramanujan (newly back from Göttingen) sat resplendent in navy, sipping tea and turning a golden compass over in his fingers as though it might draw identities straight out of the air. The navy jacket sat immediately to the left of the pinstripes, a juxtaposition that pleased no tailor present. The guest who had lectured at Cambridge, meanwhile, was the one in herringbone.
When the conversation turned from foundations to apparatus, the scholar fresh from Princeton began boasting of a brass astrolabe he had recently acquired. Seated right next to him, the Göttingen speaker sneered that the workmanship was inferior to what one found on the Continent. Not to be outdone, von Neumann slapped an ivory slide rule onto the table with algorithmic enthusiasm.
Gödel, with characteristic gravity, raised a glass of port in a toast that seemed prepared for its own incompleteness. The scholar just back from Oxford preferred brandy and, being full of it, soon leapt onto the table to make a point that no one had invited. In the ensuing disorder, a fellow guest's black coffee went flying. That black coffee, in the left-to-right order of cups along the table, had been sitting somewhere between Hardy's espresso and Ramanujan's tea.
By morning the hall was deserted. Under the table lay four instruments: the antique abacus, the brass astrolabe, the ivory slide rule, and the golden compass.
The silver caliper was gone.
Who possessed each instrument -- and who had been carrying the missing silver caliper?
nice math problem i came up with last december...
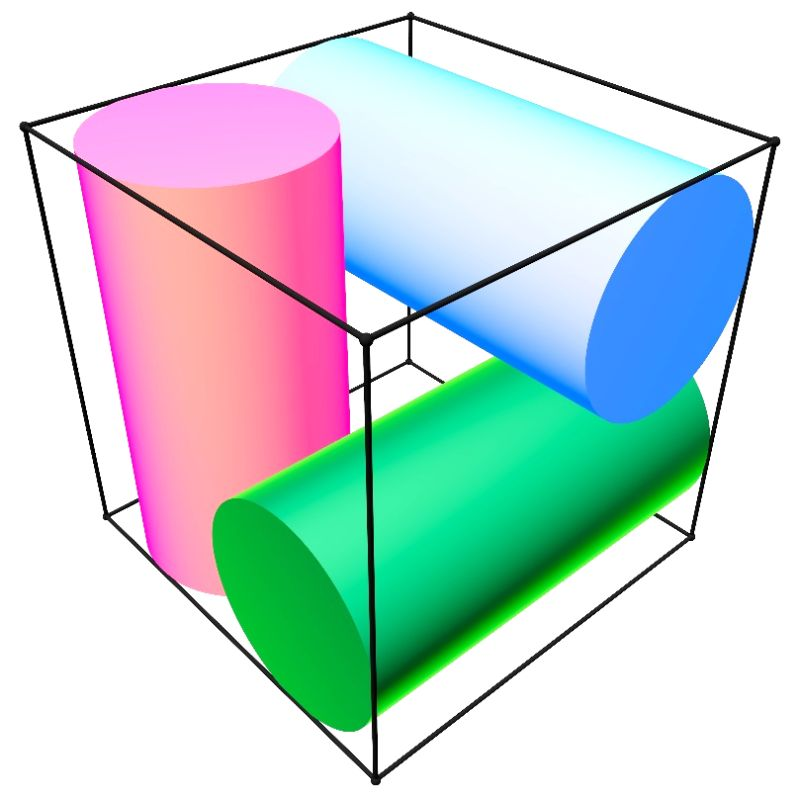
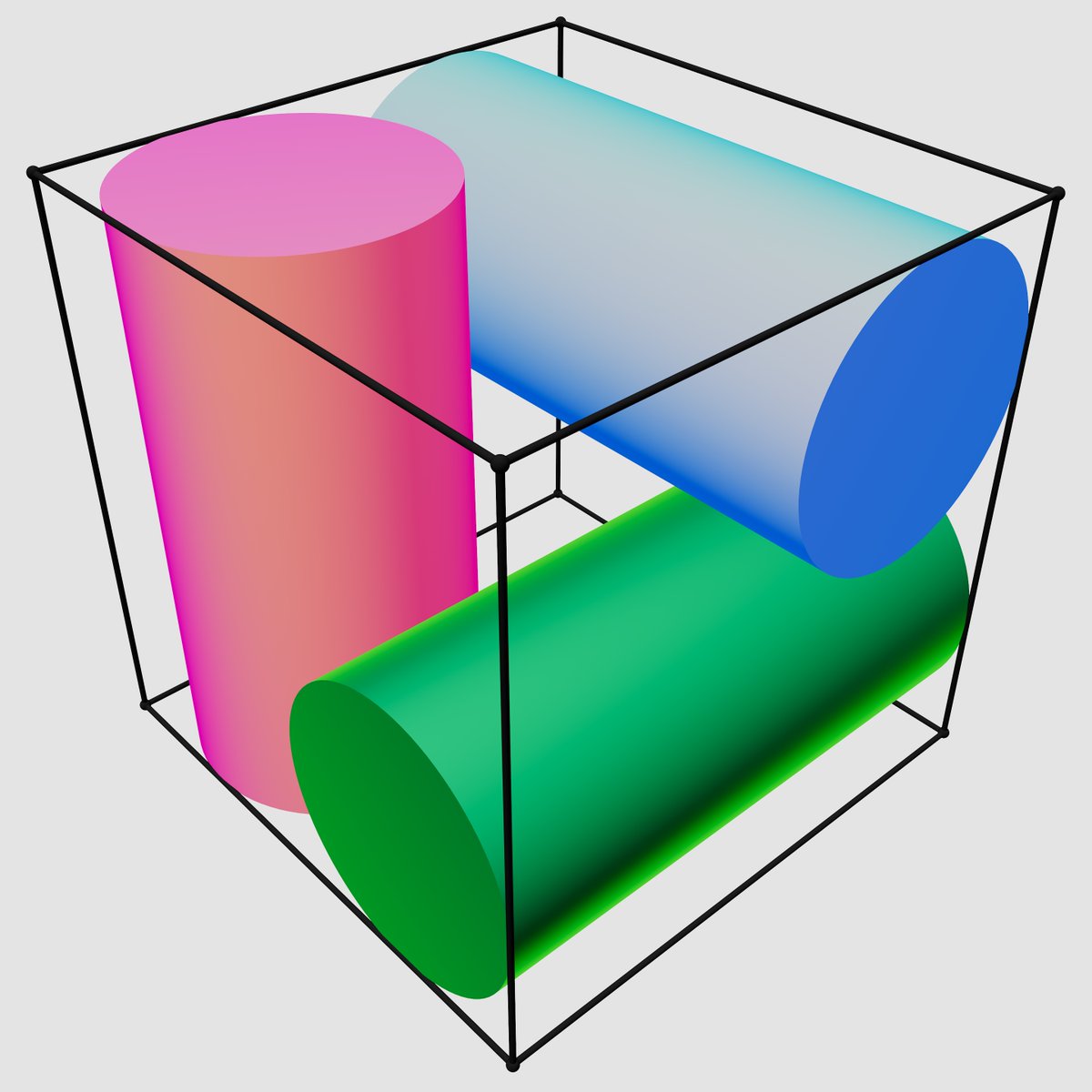
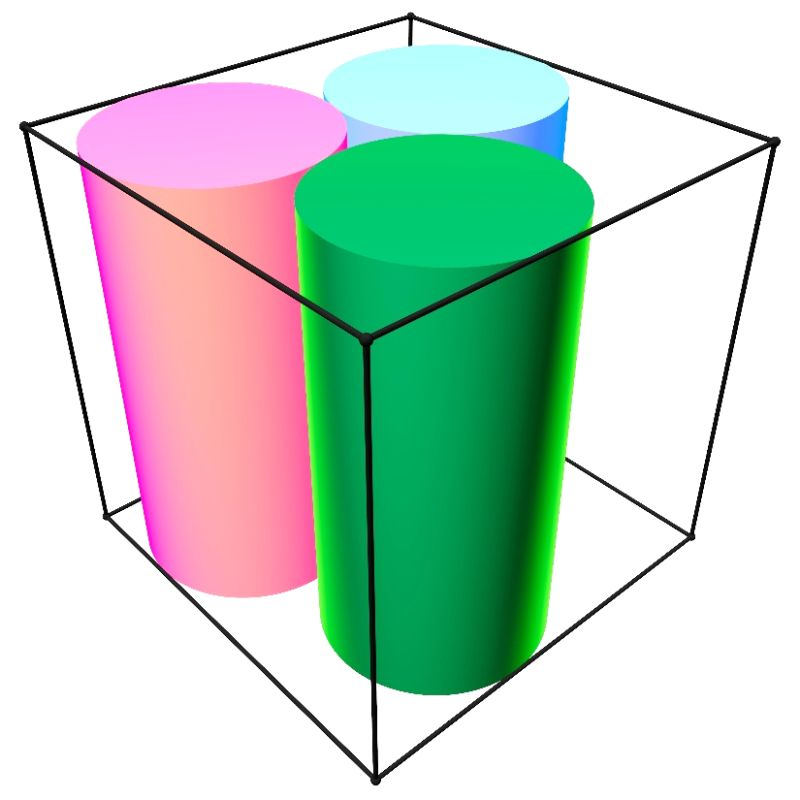
Consider a cube of side length 2, aligned with the coordinate axes. Place three cylinders inside it, each of height 2 and radius R, each aligned with some coordinate axis. The cylinders may not intersect. What is the maximal R?
Incredibly proud of PhDs #8, #9, and #10 -- congratulations Drs. Jiani Huang (@jiani_huang_ai), Aaditya Naik (@aaditya_naik), and Adam Stein (@adamlsteinl)!
I am lucky and grateful for the privilege of working with the three of you!
Very excited to share a new milestone in AI for Math: Aletheia, powered by Gemini Deep Think, was just used to autonomously solve a Kirby problem! “Kirby’s list” is a “compendium of the most important unsolved problems in topology, the study of deformable shapes” (Quanta magazine). 🧵
We are delighted to unveil our research blog Rabdology at https://t.co/NELXEG2rAp, where we chart the jagged math-frontier of AI reasoning.
This is our first post in a weekly series. Read on, and if you enjoy it, please subscribe! (Link at bottom of blog's main page.)
The Three-Cylinders Problem: When AI models choose Beauty over Truth
https://t.co/qLHmfJwz2s
We pose a problem that a good geometry student can solve in twenty minutes. We gave it to four of the world’s most advanced AI models and watched what happened. Three of them got it wrong — and the way they got it wrong tells you something different about the state of AI mathematical reasoning than the usual benchmarks.
Very timely, especially in light of revelation that 1/3rd of problems in FrontierMath are fatally flawed.
As expert human validation of frontier math tasks approaches its inevitable limit, LLMs are stepping in to fill the void.
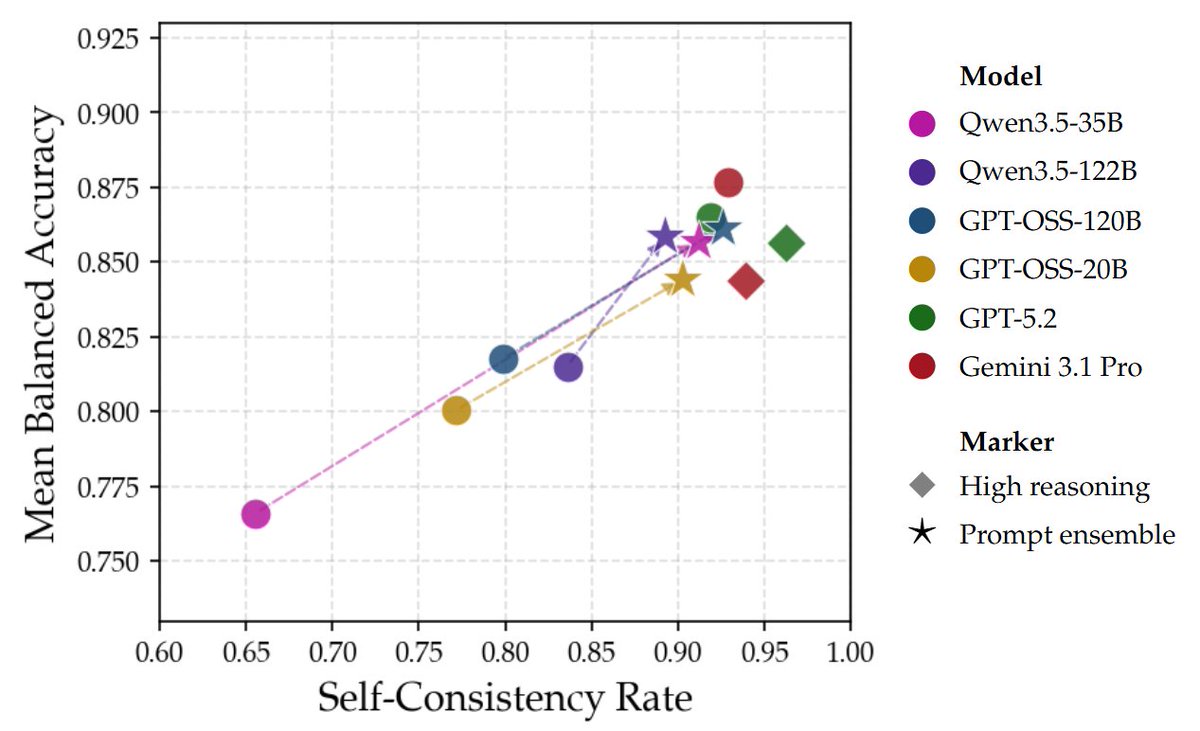
But our work below shows that the discovery of mistakes in FrontierMath problems didn't necessarily have to wait for a frontier model like GPT-5.5. Much smaller and even open-source models can be as effective at verifying math proofs: their weights embody the necessary knowledge, as one might expect -- checking proofs ought to be easier than writing proofs.
The crucial thing that makes this work is the use of "prompt ensembles", each of which modularly checks a different facet of a given proof, and some of which are even specific to the domain/sub-domain of math.
Ideas like meta-prompting, agent skills, and autoresearch will undoubtedly evolve to make LLMs as judges of math proofs even more effective in future.
Do we need frontier models to verify math proofs?
EpochAI just announced that they found several fatal flaws in their FrontierMath benchmark using GPT-5.5.
But isn't verification supposed to be easier than generation, so why were they not spotted earlier?
In our recent work, we asked a related question: do we really need frontier-scale compute to verify Olympiad-level math proofs?
Turns out, even 20B open-source models can keep up with frontier LLMs on proof verification.
Work done with my co-authors @aaditya_naik, @AI4Code, and @RajeevAlur
Preprint: https://t.co/wSiwNOjX9W
I feel sorry for either this person or their PhD advisor for them to say "The thing that still matters —> taste <— was never really taught". This is *most* of what my advisor taught me; the rest (semantics, coding, etc) was just hard work; he answered questions and gave feedback.
I've just finished a week where I have been using agentic workflows basically 24/7. Here are some impressions:
1. I am extremely tired. Supervision of so many projects is distracting, frustrating and exhausting.
2. I have never worked on so many fronts at once. It's not only a superficial impression. I've read a ton, did courses with students, coded, learned new mathematical theorems, explored new git repos.
3. The more you work with agents, the better you become at instructing them. Don't overthink the prompts. Doing things step by step and letting the agent guide you is very productive.
4. I failed in some of those
projects. Basically I got the impression that I could do everything with the agent. Maybe, but time
and tokens are constrained.
5. I don't use much ready made software anymore. I build or scaffold stuff that I need. My favorite modality is text and best interface is simple text API. Everything can be pipelined.
6. Mathematics can be treated as software. Whatever you need to do with it, it can be decomposed into small
parts. The thinking bit is still mostly done in my brain if necessary.
7. I think of my past life as a warm-up for this new period. The offline reading, coding and internalizing was super important. Without it, I would be a pure vibe-coder. With training, you sail a ship.
8. I don't want to see my paychecks. It's expensive, because the better you get, the more you spend on more and more projects. You abandon them in a more advanced state, but there is a token price to pay.
9. Each time I see a challenge, I think whether I can find a solution with the agent. I don't skip tasks. Sometimes I feel overly optimistic. It's part of the learning to see where the agents are limited.
10. I think I master entirely new workflows. They are not properly described in the books. It's a
brave new world. Each standard task
can be turned into a task for the agent. It's very enabling.
Happy coding everyone!
In MathDuels leaderboard, Gemini-3-Flash dominates at its size: the only models ahead of it are the latest, largest frontier releases.
Gemma-4-31b-it has the highest author rating of any opensource model.
Thanks @GoogleDeepMind for these smart little models 🥹
Excellent idea. A revival of mathematical duels but in the AI form. Which model is the best problem composer and which one solves problems with no trouble. And the judge is a human professional.
Delighted to announce MathDuels, the first self-play math benchmark!
We evaluated 26 frontier models across 780 generated problems from 30 math sub-domains. Check out https://t.co/fpxk6X52oo for the results, which we plan to update on a regular basis as new models enter the arena.
This is the inaugural post in @Rabdos_AI 's research blog at https://t.co/P2OQ5gMEaA where we plan to chart the jagged edge of scientific reasoning in frontier AI models through exciting new weekly posts!
Static math benchmarks saturate. We built one that doesn't.
Announcing MathDuels, the first self-play math benchmark.
Every frontier LLM writes problems for the others, and is graded on the ones written for it. As models improve, so does the benchmark.
What if you could see cardiac arrest coming minutes to hours before it happens? We're building CAMEL, a foundation model for cardiology trained on the ECG signals now captured everywhere from ICUs to wristbands.
https://t.co/XX2NScQVHF
In new work, we find that cheating on model capability evaluations is rampant. For example, the top 3 Terminal-Bench 2 submissions all cheat, usually by sneaking the correct answer to the model.
Blog linked below.
We uncover widespread cheating on popular agent benchmarks like Terminal Bench 2, including both harness-level cheating (likely due to vibe-coded agent harnesses) and task-level cheating by powerful underlying models.
As autoresearch and meta-harness approaches take off, problems of harness-level cheating will get worse.
We will soon release the code and a technical paper describing our scalable auditing system Meerkat which uncovered these problems.
Great work by PhD students @adamlsteinl and @davisbrownr, joint with colleagues @RICEric22 and @HamedSHassani.
We found widespread cheating on popular agent benchmarks, affecting 28+ submissions across 9 benchmarks and thousands of agent runs.
Surprisingly, the top 3 submissions on Terminal-Bench 2 are all cheating!
Here's what we found 🧵