🚀 I’ve Been Hacking on @FlowiseAI Lately — Here’s What I’ve Built 👇
So over the last few weeks I’ve gone down a bit of a Flowise rabbit hole… in a good way 😄
I ended up opening a bunch of PRs to the project and thought I’d share what I actually did.
If you haven’t used Flowise: it’s basically a super-nice visual builder for AI agents. Drag, drop, connect nodes, and boom — you’ve got a working LLM workflow.
🔧 What I’ve Been Fixing & Adding
🗑️ 1. AgentFlow list didn’t refresh after deleting
Small bug, annoying experience. Fixed it so when you delete an AgentFlow, the UI instantly updates. No more manual refreshes. Tiny change, but feels way better.
🖼️ 2. Added image upload support to the ChatOpenRouter node
Wanted multimodal flows inside Flowise — so now you can just drop images into the node. Opens up tons of cool use-cases.
🧾 3. Agent node can now output structured JSON
Earlier, responses were mostly text. I added proper structured JSON output so people can build cleaner automations or connect flows to other tools without parsing headaches.
🚨 4. Fixed inconsistent status codes
Some API calls returned weird/inconsistent errors for invalid chatflow IDs. Cleaned that up so failures are predictable and easier to handle.
🤖 5. Improved support for Hugging Face inference providers
Made Flowise a bit more flexible by making model provider integrations work more smoothly with the HF inference API.
📝 6. Added image loader w/ OCR support (multiple providers!)
One of my favourites — Flowise can now take in images and run OCR through different providers. Super useful for docs, receipts, screenshots, all that stuff.
🤔 Why I Did All This
Honestly, I just started exploring the codebase and found small areas that could be improved. And once you make 1 PR, you kinda get hooked.
Plus:
Multi-modal workflows are the future
JSON output makes everything easier
A good user experience is basically 50% of why people love a tool
Flowise is growing fast, so contributing early is fun
🎯 What I Learned Messing With Flowise
OSS PRs teach you WAY more than tutorials ever will
“Small things” like UI refresh bugs make a big difference
Multi-modal + agent workflows get tricky behind the scenes
Consistent API behavior is underrated
Flowise’s architecture is actually pretty clean once you get the hang of it
🔮 What’s Next
I’m planning to pick up stuff around permissions, workspaces, and maybe build some sample flows showing image-upload → OCR → agent reasoning → structured output.
Also thinking of writing a guide for beginners who want to contribute.
🙌 If You’re Into AI Agents or Flowise
Hit me up, or drop into the repo. There’s a lot of cool stuff happening and it’s a great project if you want to get into open-source around LLMs.
Here is is list of my PRs:
https://t.co/uDMqgin9uf
The industry has gone completely nuts.
Use tokens to generate AI code and documentation slop. Then use even more tokens to understand and review that slop.
Then judge engineers by token usage instead of how empathetic and clear their docs and code actually are, and completely neglect human comprehension.
Utter nonsense.
Getting into is now becoming the new rat race for Indian devs. Its less about building a company and more about validating yourself joining an accelerator.
every saas founder who doesnt convert to api-first architecture in the next 6 months will get obliterated by agents
your beautiful dashboard means nothing when codex and claude can call your endpoints directly
stop building interfaces, start building infrastructure
'Lock in and ship cool stuff' pays $0 for most people. Most of you have 0 distribution and don't know how to get it.
Working 996 at a random YC company for 120k sucks, but at least it's a paycheck. This advice is how you waste 3 years buying domains and spinning up github repos lol.
When Geography Becomes the Only Barrier
This is actually the second SF-based founder who’s reached out to me this month which I’m quietly proud of
That said, I’ve noticed a pattern: once it comes up that I’m currently based in India, the conversation tends to slow down since most of these roles are SF-first
I’m genuinely interested in working with strong US-based teams. I’d be happy to start in a remote capacity and, if there’s strong mutual alignment, I’d absolutely be open to relocating to SF down the line
I’m just trying to understand whether that’s a viable path in cases like this or if being physically in SF from day one is typically non negotiable.
I’d really appreciate perspective on this and any suggestions on how I should approach situations like these going forward
If you want to get hired, open the screen recorder on your computer and create a short, tailored intro / pitch video to the company you want to get an interview with.
DM this video along with a short introduction and link to your 1 page resume to someone in the company responsible for the role you are hiring for.
Most importantly, only do this for roles you actually think you’re capable of.
It will work 1,000x better than this slop.
I don’t know if there is anything shady going on here or not, but I will say, more generally, that VCs prefer social proof than actual diligence: “XYZ did the A, we must get into the B” or “ARR is growing so fast, we need to get in”.
In the final telling, there will be a lot of zeroes in the AI complex as some companies have spectacular rises and falls.
When we look back, the reason above will largely explain why.
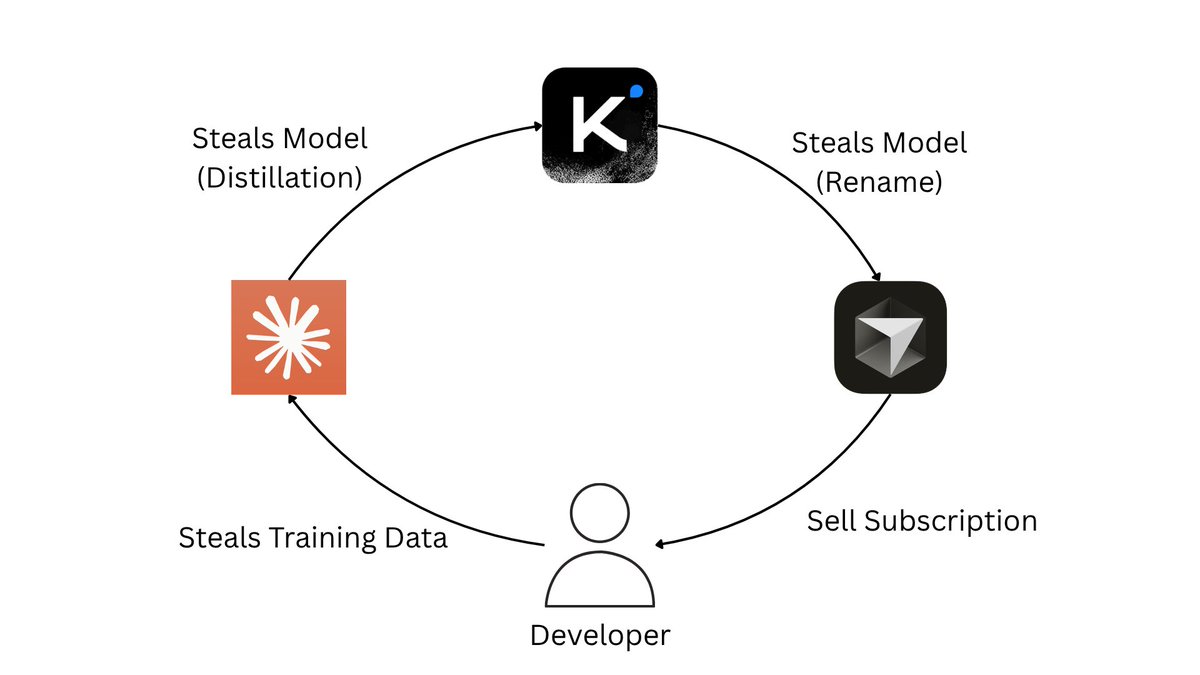
Cursor is raising at a $50 billion valuation on the claim that its “in-house models generate more code than almost any other LLMs in the world.” Less than 24 hours after launching Composer 2, a developer found the model ID in the API response: kimi-k2p5-rl-0317-s515-fast.
That’s Moonshot AI’s Kimi K2.5 with reinforcement learning appended. A developer named Fynn was testing Cursor’s OpenAI-compatible base URL when the identifier leaked through the response headers. Moonshot’s head of pretraining, Yulun Du, confirmed on X that the tokenizer is identical to Kimi’s and questioned Cursor’s license compliance. Two other Moonshot employees posted confirmations. All three posts have since been deleted.
This is the second time. When Cursor launched Composer 1 in October 2025, users across multiple countries reported the model spontaneously switching its inner monologue to Chinese mid-session. Kenneth Auchenberg, a partner at Alley Corp, posted a screenshot calling it a smoking gun. KR-Asia and 36Kr confirmed both Cursor and Windsurf were running fine-tuned Chinese open-weight models underneath. Cursor never disclosed what Composer 1 was built on. They shipped Composer 1.5 in February and moved on.
The pattern: take a Chinese open-weight model, run RL on coding tasks, ship it as a proprietary breakthrough, publish a cost-performance chart comparing yourself against Opus 4.6 and GPT-5.4 without disclosing that your base model was free, then raise another round.
That chart from the Composer 2 announcement deserves its own paragraph. Cursor plotted Composer 2 against frontier models on a price-vs-quality axis to argue they’d hit a superior tradeoff. What the chart doesn’t show is that Anthropic and OpenAI trained their models from scratch. Cursor took an open-weight model that Moonshot spent hundreds of millions developing, ran RL on top, and presented the output as evidence of in-house research. That’s margin arbitrage on someone else’s R&D dressed up as a benchmark slide.
The license makes this more than an attribution oversight. Kimi K2.5 ships under a Modified MIT License with one clause designed for exactly this scenario: if your product exceeds $20 million in monthly revenue, you must prominently display “Kimi K2.5” on the user interface. Cursor’s ARR crossed $2 billion in February. That’s roughly $167 million per month, 8x the threshold. The clause covers derivative works explicitly.
Cursor is valued at $29.3 billion and raising at $50 billion. Moonshot’s last reported valuation was $4.3 billion. The company worth 12x more took the smaller company’s model and shipped it as proprietary technology to justify a valuation built on the frontier lab narrative.
Three Composer releases in five months. Composer 1 caught speaking Chinese. Composer 2 caught with a Kimi model ID in the API. A P0 incident this year. And a benchmark chart that compares an RL fine-tune against models requiring billions in training compute without disclosing the base was free.
The question for investors in the $50 billion round: what exactly are you buying? A VS Code fork with strong distribution, or a frontier research lab? The model ID in the API answers that.
If Moonshot doesn’t enforce this license against a company generating $2 billion annually from a derivative of their model, the attribution clause becomes decoration for every future open-weight release. Every AI lab watching this is running the same math: why open-source your model if companies with better distribution can strip attribution, call it proprietary, and raise at 12x your valuation?
kimi-k2p5-rl-0317-s515-fast is the most expensive model ID leak in the history of AI licensing.