1/ 🧵 Meet Tapered Language Models (TLMs):
Modern language models (transformer, recurrent, memory-based) are a stack of *identical* layers. A uniform parameter distribution across depth, inherited from the 2017 transformer and rarely questioned.
Turns out it's leaving free performance on the table.
Perplexity drops 16.28 → 14.44 (same params, same compute) 👇
📣📣 Meet Qwen-AgentWorld — a native language world model that simulates 7 agent environments (MCP, Search, Terminal, SWE, Web, OS, Android) within a single model. Environment modeling is the training objective from day one, not a post-hoc adaptation.
🤔 LLMs are trained to be better agents — better at acting in environments. But nobody has trained them to model the environments themselves.
🗺️ Our roadmap: investigate how language world modeling can push the boundaries of general agent capabilities, along two routes:
1️⃣ Build a foundation model for environment simulation — outperforming Claude Opus 4.8 and GPT-5.4 on AgentWorldBench
2️⃣ Investigate how world modeling enhances agent training:
🔬 Controllable Sim RL (agentic RL with LWM as environments) surpasses training in real environments
🧠 Learning to predict environments (LWM warm-up) makes agents stronger — remarkably, even without any agent-specific training, this predictive knowledge transfers to agentic tasks with zero fine-tuning
📑 Paper: https://t.co/Jx2l5RKq71
📖 Blog: https://t.co/7tVcKyhsx2
��� GitHub: https://t.co/B5Lvb1UZCn
🤗 HuggingFace: https://t.co/Kw3QBL1TM5
🧩 ModelScope: https://t.co/YBnGYgMWWI
🚀New work on credit assignment in multi-step reasoning RL post-training🚀
Introducing Self-Reset Policy Optimization (SRPO): i) localize the first wrong reasoning step, ii) reset to that step, iii) learn from counterfactual continuations from there – no external supervision.🧵
My teacher and friend Dimitri Bertsekas passed away earlier this month. I wrote about his broad contributions to the field of numerical optimization and his deep impact on my writing and research. https://t.co/CIDI9C31Tj
What if attention wasn't about matching tokens, but operating in function space?
Glad to share our #ICML2026 paper:
📄 Functional Attention: From Pairwise Affinities to Functional Correspondences
w/ @Jiefang_Xiao@GaoMaolin@stevenygd Daniel Cremers
📄 https://t.co/rhn9NtwrBm
1/8 🧠 Think the deepest layer of an LLM is always the best for output? Think again! Our latest paper by Qwen Team reveals the "Alignment Tax" hiding in your final layers. Post-training can violently perturb terminal tokens away from rigorous logic! 🧵 ↓
I really like this paper on why predicting latents is more data-efficient than predicting tokens.
In Next-Latent Prediction Transformer (https://t.co/d0Jzdduhtk), we provide a different argument on why predicting your own next latent can improve data-efficiency.
Predicting the next latent h_{t+1} gives you a rich learning signal about ALL future latents, and future tokens. This is because h_{t+1} is trained to predict h_{t+2}, h_{t+2} is trained to predict h_{t+3}, and so on... As such, predicting the next latent gives denser gradient signals than one-hot token predictions :)
I talk more about this in my blog: https://t.co/jSsDYndDn8
⭐ VibeThinker-3B is released — a dense 3B model for frontier-level verifiable reasoning.
🚀 Reasoning: 94.3 on AIME’26, 76.4 on IMO-AnsBench, and 80.2 Pass@1 on LCB v6; with CLR, AIME‘26 improves to 97.1 and IMO-AnsBench to 80.6.
💻 OOD Coding: On recent unseen LeetCode weekly contests, VibeThinker-3B passes 123/128 (96.1%) first-attempt Python submissions.
⚡ Efficiency: Only 3B parameters, yet reaching the performance range of much larger top-tier reasoning models.
🧠 Perspective: Small models are not just cheaper substitutes. In parameter-dense domains with clear verification signals, SLMs offer a path to frontier-level reasoning that complements traditional Scaling Law.
Model : https://t.co/94A14zpqCV
Github: https://t.co/32so5P6C7L
Paper: https://t.co/UDd264RsZb
#AI #LLM #Reasoning #OpenSource #SmallModel
Next week I am teaching a tutorial on efficient LLM inference at the Machine Learning Summer School 2026 in NYC, hosted this year at Columbia University. The slides are below. There are about 150 of them, which sounds small, given how far the field has come.
Ok, so here is my take on the Fable ban, sovereign AI, Sarvam, etc.
The event is interesting as it has implications from many perspectives.
For AI users, it is clear that you should not confuse access with ownership, or adoption itself as advantage. And if the most significant tech differentiator you are leveraging has external control loops, then you have to accept you are vulnerable.
For AI talent, it is now a precedent that you would be *seen* aligning to national interests more than company interests. And even if its just a whim for now, this trend will be hard to reverse as the world gets more automated…
For AI labs, their offerings will be stratified - general purpose AI would be available as utility, but frontier AI would be gated. This is a fantastic business model for labs - *democratized* AI sucks in all the data liquidity of the world which is locked in higher margin frontier offerings.
I think for the world to be a better place, all three of the above are bad vectors. We need to have more countries and companies owning their own destinies. And in the post AI world, that means being able to use and improve AI systems within their own perimeters - what one may call Sovereign AI.
At Sarvam, Sovereign AI in India was the founding thesis a couple of years back, and continues to remain the core operating principle. From our vantage point, it is super clear that India will build, leverage, and create massive business value and societal impact with sovereign AI. The following is precisely how we at Sarvam are contributing to make that happen.
Really like this simple and elegant idea for self-improvement where a reward model is available. No RL needed, just on-policy distillation loss where teacher = same LLM as student, but teacher is given student's answer and its scalar reward.
Given a generalist model, how do we turn it into a specialist for the task we care about?
We give a *provable* answer in our ICML 26 paper with @ffeng01, Yuke Li, Shaoan Xie, @sirbayes , and @kunkzhang
https://t.co/SEYJ8i4cfZ
OPD is on-policy, but its supervision is still post-hoc and one-step.
The student generates a rollout. The teacher then supervises that fixed trajectory token by token.
Our new paper argues that this can fail at the wrong scale.
When the prefix itself is broken, the problem is not only which tokens to reweight, clip, or truncate. The problem is the trajectory.
We propose Trajectory-Refined Distillation (TRD): refine the student rollout under teacher guidance before distillation.
with @ryanxhr Yichuan Ding @yayitsamyzhang
Paper: https://t.co/DKkKL5zj69
New blog post: On-Policy Distillation — Promise, Pitfalls, and Prospects.
OPD combines on-policy rollouts with dense teacher supervision.
But it is not a free lunch.
I discuss three failure modes and introduce our new paper.
https://t.co/xU35CqoMi3
We've always intuited that verification is easier than generation. Chen's new work shows that explicitly training for it unlocks massive self-improvement:
📈 14× boost in test-time refinement on hard reasoning
🚀 30% gain beyond the RL plateau at training time
I am sad to hear of the passing of Dimitri Bertsekas. This one hurts.
Dimitri had a big effect on my career, from inspiring research topics to writing one of my tenure letters.
A long thread on memories of Bertsekas and some of his works that influenced me the most.
Scaling RL to long horizons remains a major challenge.
Long-horizon Q-learning (LQL) prevents compounding bootstrapping errors by bounding the difference in value over long horizons.
It shows large gains over 1-step TD and n-step returns!
Paper: https://t.co/OTk3M6cz8p
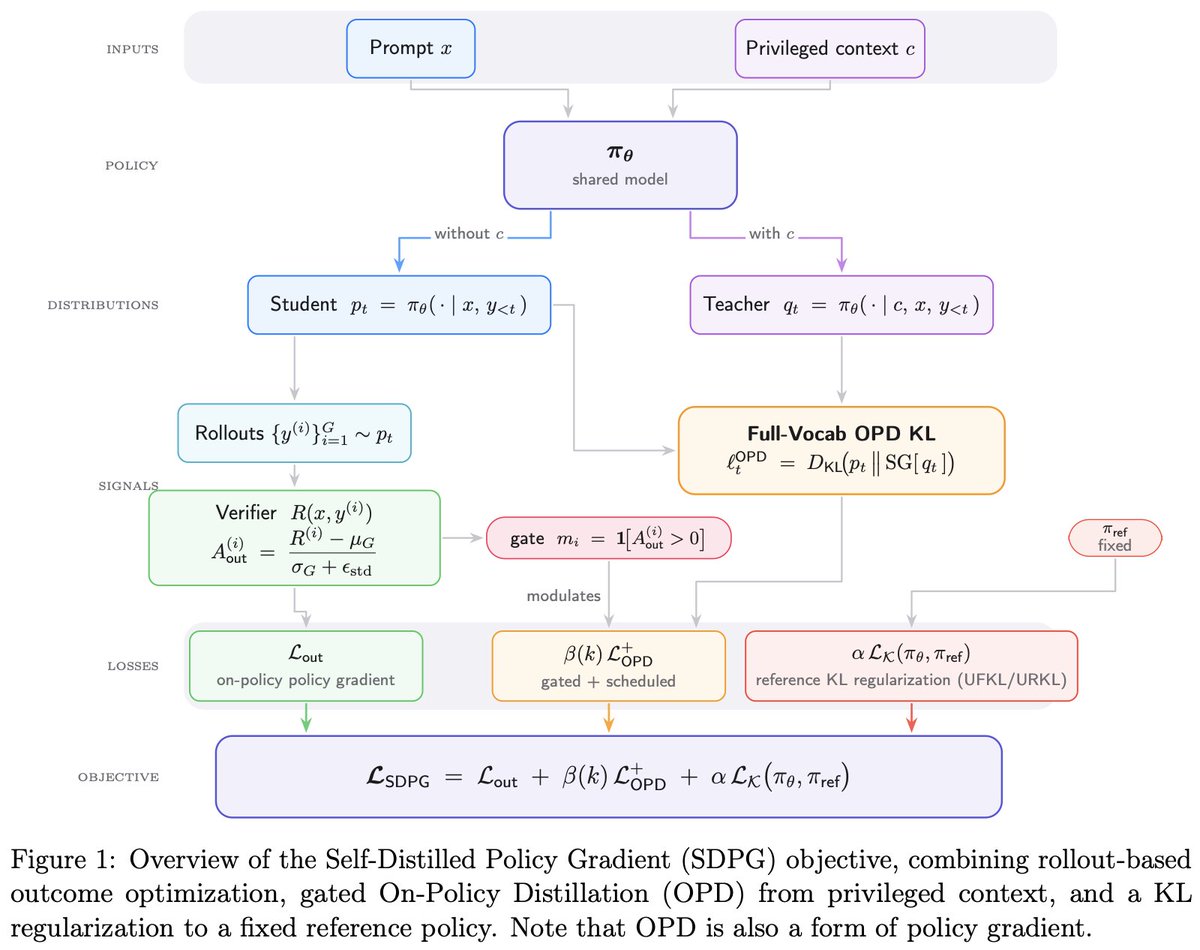
Introducing Self-Distilled Policy Gradient.
Token-level rewards, credit assignment, self-distillation.
RL and distillation are converging toward the same idea:
Policy gradients, it always has been, it always will be.
https://t.co/RJeRFUTeyz
MAI-Thinking-1 is out!
Excited to share what we are building and how climbing from scratch (no distillation) actually works: simple recipes, rigorous science, self-distillation, patience, and great infra.
Check out our tech report has the full story of our RL climbs.
https://t.co/aLW40sWz4d
🚀 How should LLMs sample on hard reasoning problems during post-training and inference where direct rollouts rarely produce a correct answer?
Best-of-N (e.g., GRPO) and tree search share two limitations:
🔻 Verification signals are sparse
🔻 Candidates stay within the model's own distribution
We introduce BES: Bidirectional Evolutionary Search — a search framework that couples forward candidate evolution with backward goal decomposition.
✅ Works for both post-training and inference.