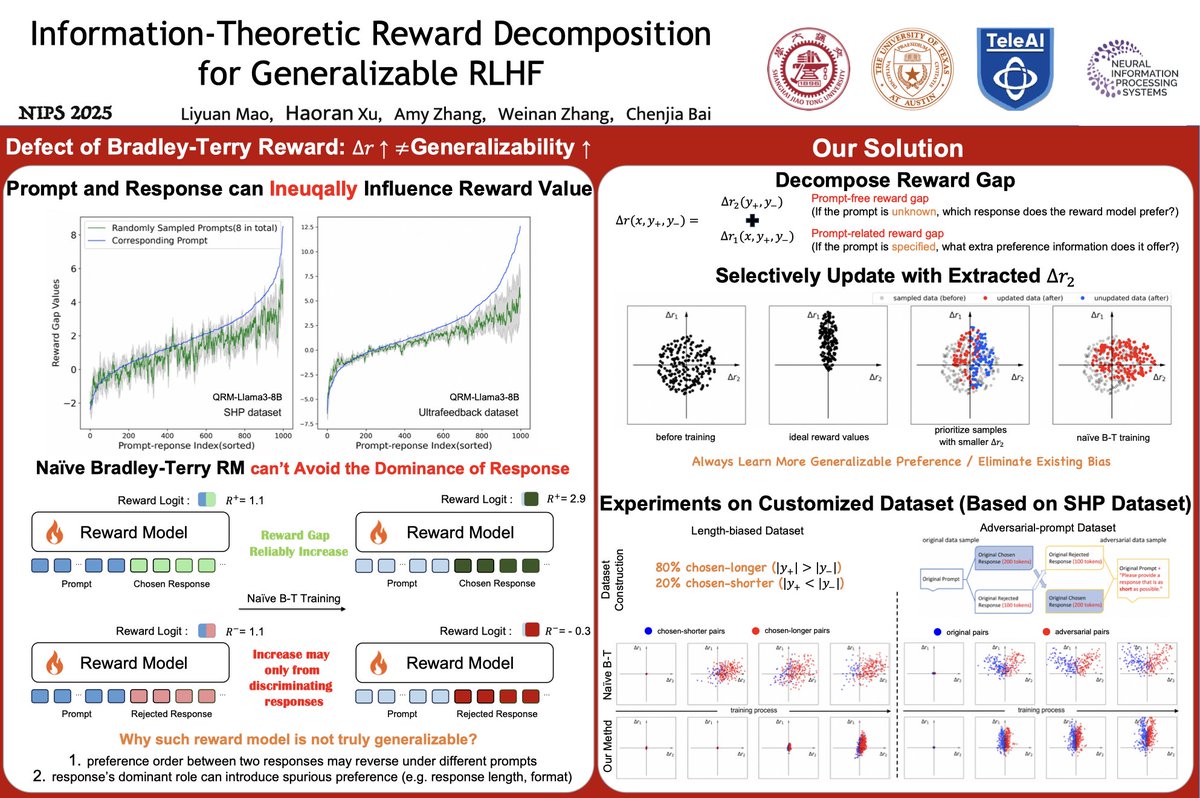
Both offline RL and LLM RL fine-tuning can be formulated as behavior-regularized RL problems.
We propose Value Grdient Flow (VGF), a new scalable and sample-efficient paradigam that treats behavior-regularized RL as an optimal transport problem.
https://t.co/ydvILyec8p 🧵[1/7]
Both offline RL and LLM RL fine-tuning can be formulated as behavior-regularized RL problems.
We propose Value Grdient Flow (VGF), a new scalable and sample-efficient paradigam that treats behavior-regularized RL as an optimal transport problem.
https://t.co/ydvILyec8p 🧵[1/7]
@linghui35877581 In our paper we only tried the offline setting, i.e., the RLHF setup. Generally offline RL could also still be used with the development of advanced off-policy LLM RL algorithms.
@ryanxhr has developed this very nice work framing offline RL as an optimal transport problem, with SOTA results on offline RL benchmarks and LLM RL tasks. Check it out, and chat with him at ICLR!
Both offline RL and LLM RL fine-tuning can be formulated as behavior-regularized RL problems.
We propose Value Grdient Flow (VGF), a new scalable and sample-efficient paradigam that treats behavior-regularized RL as an optimal transport problem.
https://t.co/ydvILyec8p 🧵[1/7]
This is joint work w/ @KaiwenHu856, Somayeh Sojoudi, @yayitsamyzhang.
Paper: https://t.co/kSwwR6gNKz.
Code: https://t.co/E10cvkva0Z.
A nice walkthrough: https://t.co/OaVWpT2N9s.
I will present VGF at @iclr_conf and can't wait to see you all at 🇧🇷. 🧵[7/7]
I will be at #NeurIPS2025 from 12/3 to 12/7 to present two papers. Come to chat everything about RL!
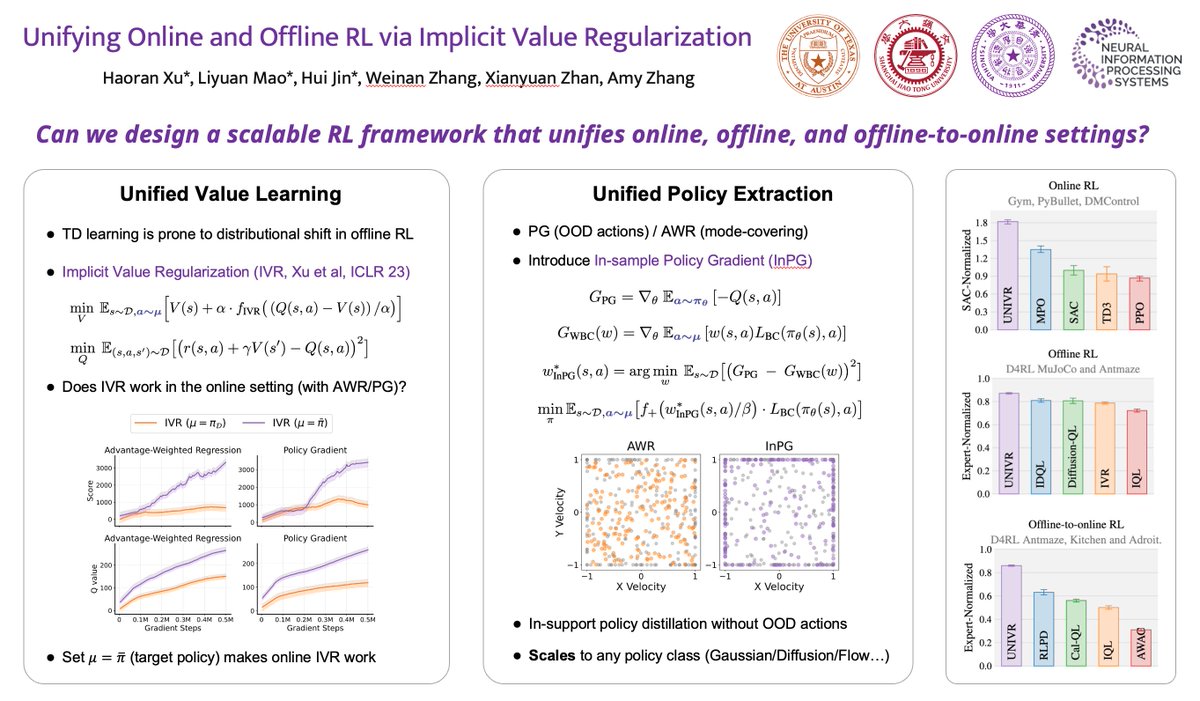
1️⃣ Unifying Online and Offline RL via Implicit Value Regularization
🗓️ Thu, Dec 4, 11:00 AM – 2:00 PM, Exhibit Hall C, D, E #303
Excited to announce @amazon's new AI PhD Fellowship Program supporting 100+ students across 9 universities like Carnegie Mellon, MIT & Stanford. Fellows will be paired with senior scientists working in related fields, plus receive financial support and AWS credits for research. Learn more: https://t.co/KNTcYI83Gm
⚠️ Reminder! Submissions for @RL_Conference's RL beyond Reward Workshop are due May 30 (AoE)!
We are brewing an interesting program and seeking innovative research work in reward-free RL. All papers are welcome, from exploratory abstracts to complete research papers.
I will miss #ICLR2025 but come to check our work on a new perspective of solving Reinforcement Learning using discriminator-weighted imitation learning.
@ShuozheL and @yayitsamyzhang will present it during today’s poster session.
I will miss #ICLR2025 but come to check our work on a new perspective of solving Reinforcement Learning using discriminator-weighted imitation learning.
@ShuozheL and @yayitsamyzhang will present it during today’s poster session.
Come to check our work on a new pre-training objective for LLM based on the transformer architecture, led by Edward!
https://t.co/7ZfUPOwh1l
More work around BST will come out, stay tuned!
introducing the belief state transformer: a new LLM training objective that learns (provably) rich representations for planning
bst objective is satisfyingly simple: just predict a "previous" token alongside the next token
come by our ICLR poster this thursday to chat!
The Belief State Transformer https://t.co/1xuRIU0PYT is at ICLR this week. The BST objective efficiently creates compact belief states: summaries of the past sufficient for all future predictions. See the short talk: https://t.co/nkYp7KxMZc and @mgostIH for further discussion.
























![ryanxhr's tweet photo. For online RL finetuning, VGF solves several hard tasks that previous methods could not. 🧵[6/7] https://t.co/wGyl0QngZV](https://pbs.twimg.com/media/HGXQj_HWwAAIxpV.jpg)