I’ve been playing with the number of demo episodes and training steps for ACT and I think I finally found the sweet spot for my SO-101.
I got decent performance with 50 episodes and 100k training steps, however operation was certainly not smooth.
But when I increased to around 80-90 episodes and 200k training steps, it eliminated a lot of the jitters and erratic movements for much smoother operation.
I’ve got each color of duck pick or place running AI models with various training params, so I’m excited to experiment on stream
The tweet-controlled livestream where you can tell my robot what to do should be live in less than a week now!
This #CVPR2026 paper from our research team is trending #1 on @HuggingFace 🤗
Meet LocateAnything: a vision-language detection model that rethinks bounding box prediction. For AI agents and robots, “seeing” is only useful if a model can pinpoint where something is fast enough to act.
Trained on 138M high-quality samples, LocateAnything decodes bounding boxes in parallel instead of one coordinate at a time, improving localization accuracy while dramatically increasing throughput for visual grounding and detection.
Project page: https://t.co/O7JMe8tzFM
New linear attention SoTA? Gated DeltaNet-2 from NVIDIA beats KDA and Mamba-3.
Prior DeltaNet/KDA models used one scalar gate for both erasing old memory and writing new memory.
This paper splits that into channel-wise erase and write gates, making memory edits more precise without losing efficient chunkwise training.
At 1.3B params on 100B tokens, it beats Mamba-2, Gated DeltaNet, KDA, and Mamba-3 variants, with the biggest gains on long-context retrieval.
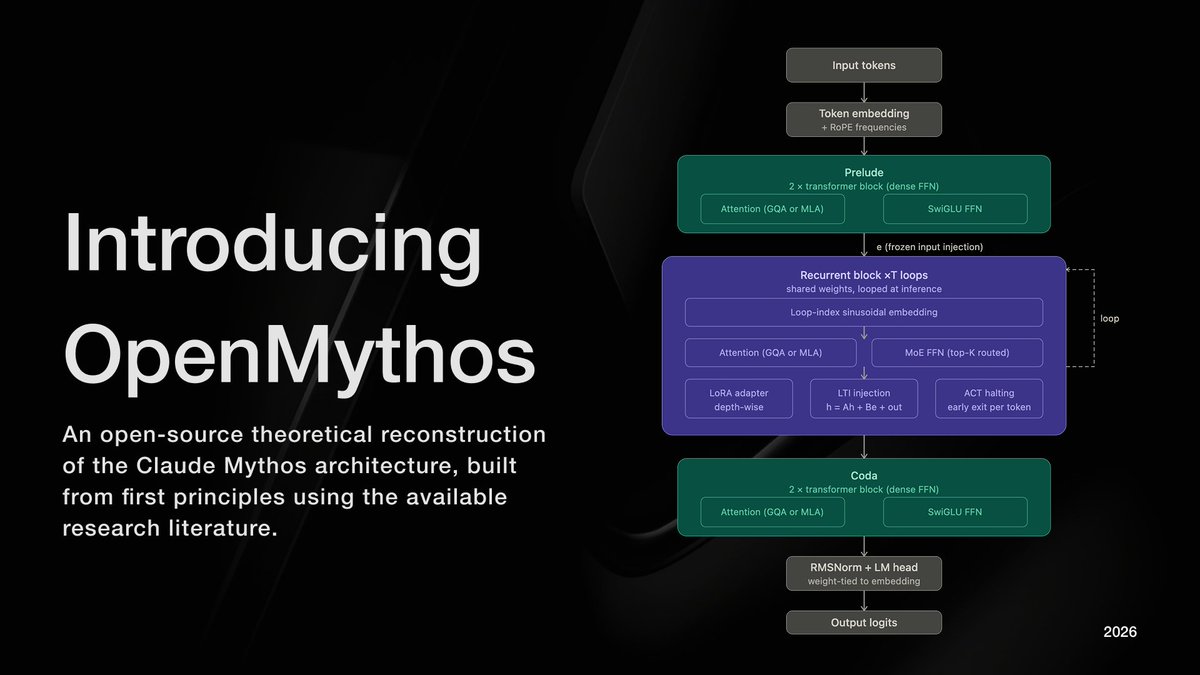
Introducing OpenMythos
An open-source, first-principles theoretical reconstruction of Claude Mythos, implemented in PyTorch.
The architecture instantiates a looped transformer with a Mixture-of-Experts (MoE) routing mechanism, enabling iterative depth via weight sharing and conditional computation across experts.
My implementation explores the hypothesis that recursive application of a fixed parameterized block, coupled with sparse expert activation, can yield improved efficiency–performance tradeoffs and emergent multi-step reasoning.
Learn more ⬇️🧵
Unitree Unveils: GD01, A Manned Transformable Mecha, from $650,000 👏
The world's first production-ready manned mecha. It can transform. It's a civilian vehicle. It weighs ~500kg with you inside.
Please everyone be sure to use the robot in a Friendly and Safe manner.
This is going to be a little bit long, but I want to give hope to my fellow anxious ML engineers.
We see a lot of propaganda on how this or that AI one shotted something, about how incredibly strong the models are getting and how we don't even need to review PRs and we can just ship to production.
Although this can be true for some cases, its also far from being representative of all the challenges we have to face.
I started using claude code 4 month ago, and quickly realized how it really does change the way we work. I can experiment 10x faster, fix small issues without coding and refactor code without sweating.
BUT, these tasks were "just" tedious and not hard. The challenge in my day to day work is to take a research code and integrate it into transformers using our standards. Its challenging because code beauty is abstract and subjective just like a philosophy.
By relying too much on claude, and on how seemingly good the code it produces look, I pushed the deepseekv4 integration without realizing that claude really did not understand the model.
I gave it access to `transformers`, the original paper, the original code, the different blog posts and my past chats and skills created to add a model, a b200 node node and a LOT of tokens, but it did NOT nail it. It did not understand the eager attention path, it did not understand the basics of causal attention. It was even wrong implementing the manifold constrained hyper connections.
It helped to reduce the burden of exploring implementation and debugging but it did not help reason around the model.
I am not a doomer, I think our job as Software Engineers has never been this great, I am just saying that we still have a job, and we should still be a bit careful when it looks to good to be true 😉