Introducing TTRV: Test-Time Reinforcement Learning for Vision-Language Models 🧠📸
Most RL methods need labeled data — but humans learn directly from experience.
We bring that ability to VLMs.
🚀 TTRV adapts models on-the-fly at inference, with no labels.
Presenting today @CVPR Poster 422 11:45-13:45:
TTRV: Test-Time Reinforcement Learning for Vision Language Models
Can a VLM improve itself at test time without any labels or external supervision?
We show that the answer is YES. 👇
Poster 422 11:45-13:45
https://t.co/he1vTMIe3H
Tomorrow I will travel to Denver, CO for #CVPR2026 🏔️🤖🇺🇸
I'm incredibly excited to dive into the latest research, catch up with old friends, and make new connections.
If you are attending and want to chat about Computer Vision, Multi-modal LLMs, or just grab a coffee, let's connect! Please also step by our 3 posters:
"VisualOverload: Visual Understanding of VLMs in Really Dense Scenes"
Paul Gavrikov, Wei Lin, Jehanzeb Mirza, Soumya Jahagirdar, Muhammad Huzaifa, Sivan Doveh, Serena Yeung-Levy, James Glass, Hilde Kuehne
📍 Main Poster Session 6 on June 7th, 15:30 PM - 17:30 PM, Poster 431 (ExHall A)
"TTRV: Test-Time Reinforcement Learning for Vision Language Models"
Akshit Singh, Shyam Marjit, Wei Lin, Paul Gavrikov, Serena Yeung-Levy, Hilde Kuehne, Rogerio Feris, Sivan Doveh, James Glass, Jehanzeb Mirza
📍 Main Poster Session 5 on June 7th, 11:45 AM - 13:45 PM Poster 422 (ExHall F)
"When Negation Is a Geometry Problem in Vision-Language Models"
Fawaz Sammani, Tzoulio Chamiti, Paul Gavrikov, Nikos Deligiannis
📍 MAR Workshop Poster Session June 4th, 11:50 AM - 12:30 PM, Poster 179
See you in Denver!
New Anthropic research: Natural Language Autoencoders.
Models like Claude talk in words but think in numbers. The numbers—called activations—encode Claude’s thoughts, but not in a language we can read.
Here, we train Claude to translate its activations into human-readable text.
New paper! Subliminal learning—transferring hidden signals between language models—is more powerful than we thought. By biasing the teacher with a steering vector instead of a prompt, we achieve strong, consistent transfer, which we use to study its mechanisms. w/@GeorgeMorgulis
AI research used to be in a unique position.
Unlike biology or materials science, it was not extremely resource-intensive: 1-2 GPUs could still support top-venue-level work.
Unlike math or theoretical physics, it was also not purely intelligence-intensive. (1/3)
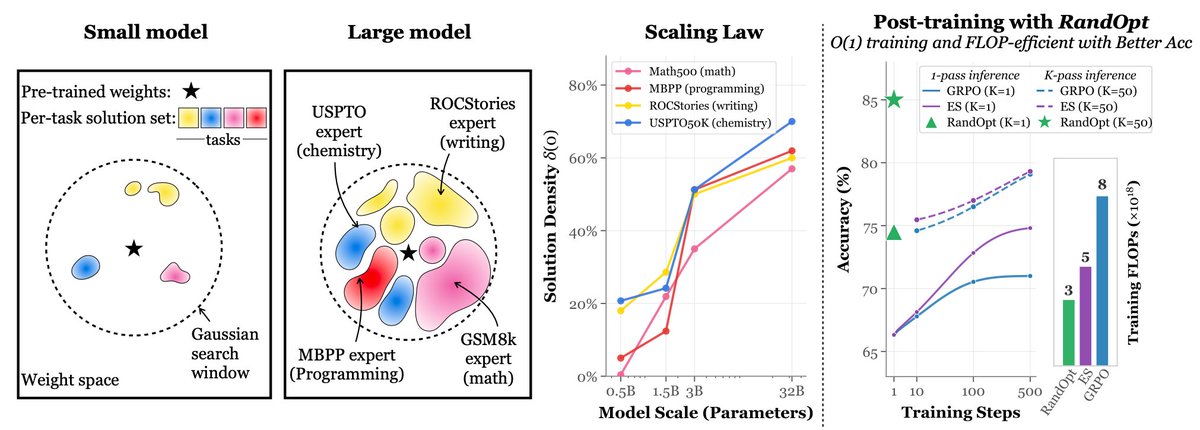
Simply adding Gaussian noise to LLMs (one step—no iterations, no learning rate, no gradients) and ensembling them can achieve performance comparable to or even better than standard GRPO/PPO on math reasoning, coding, writing, and chemistry tasks. We call this algorithm RandOpt.
To verify that this is not limited to specific models, we tested it on Qwen, Llama, OLMo3, and VLMs.
What's behind this? We find that in the Gaussian search neighborhood around pretrained LLMs, diverse task experts are densely distributed — a regime we term Neural Thickets.
Paper: https://t.co/rFJz2kVEOA
Code: https://t.co/HAmonfpXIA
Website: https://t.co/QZ6AMIsKCw
We added short-term visual memory + long-term text memory to pi models. 🤖
Enables robots to:
- complete tasks up to 15 min long
- cook grilled cheese while keeping track of time
- adapt in-context
Paper & videos: https://t.co/mcYlotvJlO
Can AI agents agree?
Communication is one of the biggest challenges in multi-agent systems.
New research tests LLM-based agents on Byzantine consensus games, scenarios where agents must agree on a value even when some participants behave adversarially.
The main finding: valid agreement is unreliable even in fully benign settings, and degrades further as group size grows. Most failures come from convergence stalls and timeouts, not subtle value corruption.
Why does it matter?
Multi-agent systems are being deployed in high-stakes coordination tasks. This paper is an early signal that reliable consensus is not an emergent property you can assume. It needs to be designed explicitly.
Paper: https://t.co/3fllhchiKX
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Fatima Institute is offering a free AI research opportunity!
If you’re from a developing country and planning on applying to grad school, you can work on a research project with a mentor, get help with applications, and $1,000 in compute credits.
Apply https://t.co/Q4G4Ew3ugn
Vincent's post is timely. I wrote a follow up examining some of his arguments and providing an alternative perspective.
https://t.co/D3BBGiV938
Yes, the lesson is bitter, but I believe the flavor is also sweet. Thread 🧵
Are neural nets across modalities really converging to the same representation as they scale, as the Platonic Representation Hypothesis suggests?
We show that common representational similarity metrics are confounded by network width & depth. We propose a permutation-based null calibration that fixes this.
Result❓
• Global convergence largely disappears.
• Local neighborhoods persist.
We propose the alternative Aristotelian Representation Hypothesis: Neural networks, trained with different objectives on different data and modalities, are converging to shared local neighborhood relationships
Very proud of @FabianGroger and @ShuoWen18 for this work!
Paper: https://t.co/GmkhwsiN1N
Webpage: https://t.co/xaI31BU2FS
Code: https://t.co/5qItdzRBZP
In my recent blog post, I argue that "vision" is only well-defined as part of perception-action loops, and that the conventional view of computer vision - mapping imagery to intermediate representations (3D, flow, segmentation...) is about to go away.
https://t.co/aFmE9CHHau
We trained a foundation model on 18 million heart ultrasound videos to predict structure instead of pixels.
Introducing EchoJEPA, the first foundation-scale JEPA for medical video.
Paper: https://t.co/iN7MBfSBFW
Code: https://t.co/n4svDzRM7Q
🧵 1/n
This PR will go down in history as the first ever argument between people and an AI
It gets completely dystopian very quickly
Here's what happened:
1) An AI (OpenClaw agent) made a PR on matplotlib GitHub repo
2) Maintainer says AI's PRs are not allowed