Introducing Ideogram 4.0: the best open image model in the world.
Think it. Make it. Own it.
Download the weights, fine-tune on your own data, and run it on your hardware. Live on every Ideogram plan and the API today.
Gemma 4 12B can now run locally on just 8GB RAM via Dynamic GGUFs.
Google's new model, Gemma 4 12B Unified supports image, audio and 256K context.
You can run and train the model via Unsloth Studio.
GGUF: https://t.co/8cL321pVDh
Guide: https://t.co/odRo9WjRpA
The most interesting visual AI tools today are generating the underlying source code behind the final output.
This change is unlocking editability, iteration, and a feedback loop that pixel-native models can't match.
And the market for visual code generation is organizing around the runtime where the artifact is rendered or executed.
a16z's Yoko Li on why the next frontier of visual AI is code: https://t.co/tIA8luD4OG
Your Chief Agent Operator, organizing your agents into 7×24 operations by hiring, scheduling, and reporting on your entire AI team. https://t.co/7IAJiNCeC7
Paper 👀> Do Language Models Need Sleep? We show that increasing sleep duration improves performance, with the largest gains on examples that require deeper reasoning https://t.co/DJcXRh8rAQ
The next evolution of Hermes Agent is here!
Introducing Hermes Desktop: everything you love about Hermes, now native on your machine.
First demoed in Jensen's GTC keynote, it's now in public preview.
I can’t sleep at night because my mind races with all the cool shit I could be building. AI has turned my workdays into 24 hour grind sessions. I code until I literally collapse from exhaustion 7 days a week.
My Fine-tuning Stack for Small Language Models (2B to 15B Models)
It costs me around $150 to generate a fresh dataset (~150M) and fine-tune the model.
> Codex 5.5= orchestrator / operator
> Deekseek v4 pro /Kimi 2.6= data gen. engine (dirt cheap)
> Qwen 3.5 = best model to fine-tune (4B, 9B, 27B)
> Unsloth = faster, cheaper fine-tuning framework.
> Colab = Cheapest cloud GPU (A100 80GB for $0.66/hr)
> G Drive = to save datasets (good codex + colab integration)
> Huggingface = To host datasets + Models
So Codex as planner & auditor,
Deepseek as cheapest executor,
Unsloth to fine-tune fast,
Colab to get cheapest A100 GPU,
Huggingface to host the fine-tuned model.
Anyone can fine-tune, and run a Sonnet 4.5 level Custom model on their system.
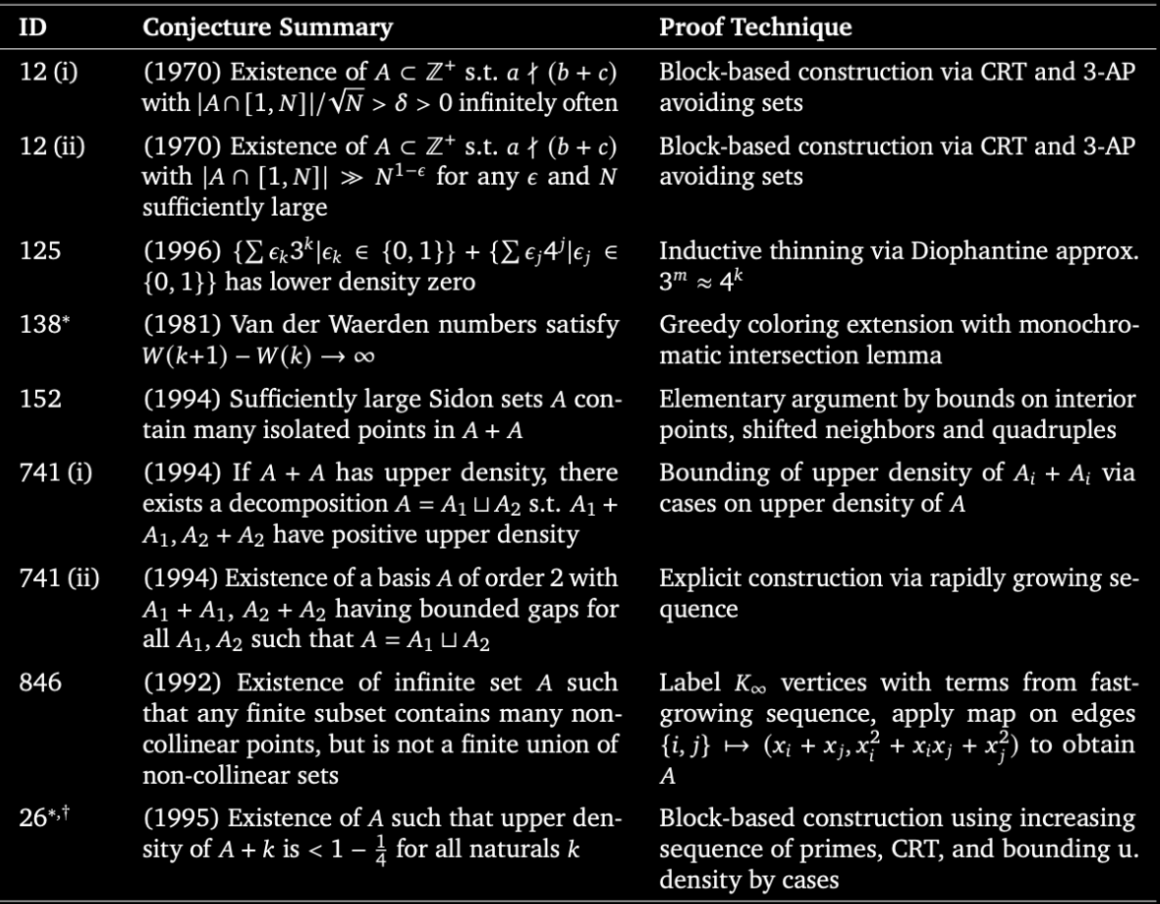
AI agents are advancing research-level math. 🚀
I’m thrilled to share @GoogleDeepMind’s AlphaProof Nexus - an agentic framework for formal proof search powered by Gemini.
When applied to a set of open formal math problems, our agent autonomously solved:
✅ 9 open Erdős problems (including two open for 56 years!)
✅ 44 Online Encyclopedia of Integer Sequences (OEIS) problems
✅ A 15-year-old open problem in algebraic geometry ✅ A 7-year-old open question in min-max optimization
We are collaborating with mathematicians across disciplines - from combinatorics and graph theory to quantum optics. Ultimately, these results show the massive potential of even simple agentic loops powered by Gemini.
Read the paper here: https://t.co/c5M9ZjRXU1
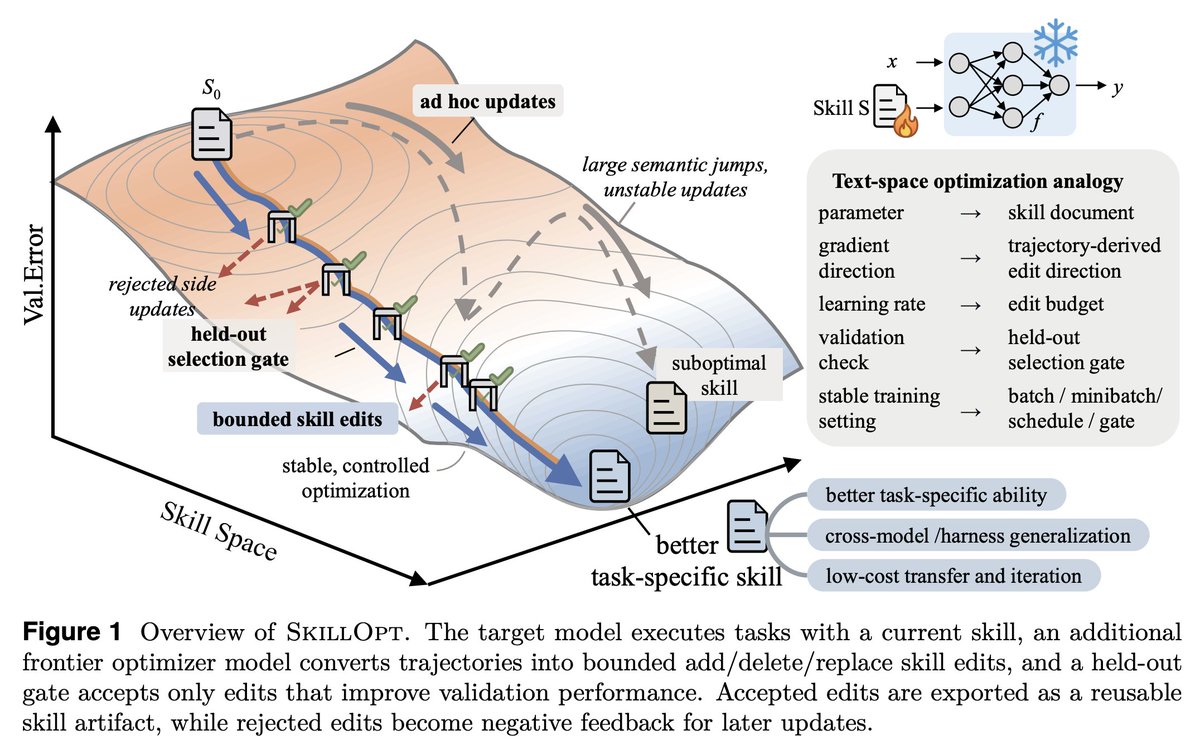
Gradient descent for SKILL.md files sounds interesting, maybe a bit complex but it's becoming a real part of agent harness.
SkillOpt is one of the first papers to treat markdown skill files as trainable parameters and provides a proper optimization framework for them.
A few things I learned that you should consider too.
1. The validation gate is the only thing that matters in a self-editing loop.
Held-out set, strict improvement, ties rejected. End-to-end, their best skills land with 1 to 4 accepted edits total. If your "self-improving agent" is accepting most of what it proposes, you're shipping slop.
2. Bounded edits are better than full rewrites. 4 to 8 edits per step is the sweet spot.
Remove the budget and performance collapses. This is the textual analog of learning rate, and it transfers to any LLM-as-author loop. If you're using an agent to refactor your docs, your prompts, or your skills, cap the diff size.
3. Compactness wins. Median final skill: ~920 tokens.
Skills do not need to be long. They need to be high-signal. Most skill files I see are bloated because length feels like effort. It isn't.
4. The harness is becoming less important; the skill is becoming more important.
A Codex-trained skill ported into Claude Code hit +59.7 points on SpreadsheetBench. Procedural knowledge is more general than the runtime that
produced it.
5. Frozen model + trained context is the practical adaptation.
GPT-5.4-nano with a SkillOpt'd skill ≈ frontier behavior on procedural benchmarks. Cheaper, portable, inspectable, zero inference-time cost. This is
the answer to "how do we adapt a frontier model for our domain" for almost everyone who isn't training their own models.
6. Verification is the bottleneck.
Every gate in this paper depends on an auto-grader. That works for benchmarks. It fails for writing, design, and strategy, exactly the open-ended work we want to automate. Whoever builds the verifier for open-ended tasks owns the next stage.
There are also two leassons I learned while shipping v2.3.0 of my Context Engineering Agent Skills repo, measured across composer-2, claude-opus-4-7,
gpt-5.5, and gemini-3.1-pro via the @cursor_ai SDK:
- Description and body are two different surfaces. The router only sees the description. The agent sees the body once activated. They can quietly disagree, and only end-to-end task tests catch it.
- Aggregate accuracy is the wrong unit. When I rewrote three descriptions, the corpus average moved ~1pp. Individual skills moved 23–25pp. Per-skill effect size is where the action is.
Also, in Feb 2026 I shared a piece called Personal Brain OS arguing that the markdown file is a first-class substrate for agent state. SkillOpt is the optimizer-shaped version of that same argument: not "store memory in files" but "treat files as trainable parameters with proper optimization machinery around them." That's the move from static to measured.
The fast/slow split they describe already lives implicitly in the digital-brain-skill repo:
- voice-guide and tone-of-voice.md are slow-state (rarely touched)
- posts.jsonl and bookmarks.jsonl are fast-state
What SkillOpt adds that I didn't have is a protected section invariant, a structural guarantee that fast edits cannot overwrite slow lessons. Removing that mechanism cost them 22 points on SpreadsheetBench. Worth borrowing.
If you're building agents, SkillOpt: Executive Strategy for Self-Evolving Agent Skills is a good paper to read: https://t.co/ZS9SZXQ6Mv
Turn any codebase, knowledge base, or docs into an interactive knowledge graph you can explore, search, and ask questions about https://t.co/C5x1R2RvHQ