We have been building the "virtual lab" mentioned in (https://t.co/n1wGYsiNGL) and letting agents iterate on it. It will be important for measuring RSI progress and for accelerating automated safety research
Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. https://t.co/OVVPJO7VQx
We've set up @AISecurityInst's Inspect platform as a lightweight remote eval service: Postgres-backed job queue, Dockerized API + worker pool, remote submission, and the existing Inspect web UI for viewing runs. It keeps the core Inspect workflow intact, but makes it practical to run many evals on a shared
host. It acts like @METR_Evals vivaria, but has Inspects awesome tooling. Link below:
We're releasing 'ai-sft' on @huggingface: a 34GB supervised fine-tuning dataset for training models on AI research tasks. 2.7M examples spanning research code generation, scientific QA, and technical problem solving, built from our research-focused data collections. Each example includes structured fields for task family, grounded context, source tracing, loss weighting, and quality flags. Train/val splits included. Link below:
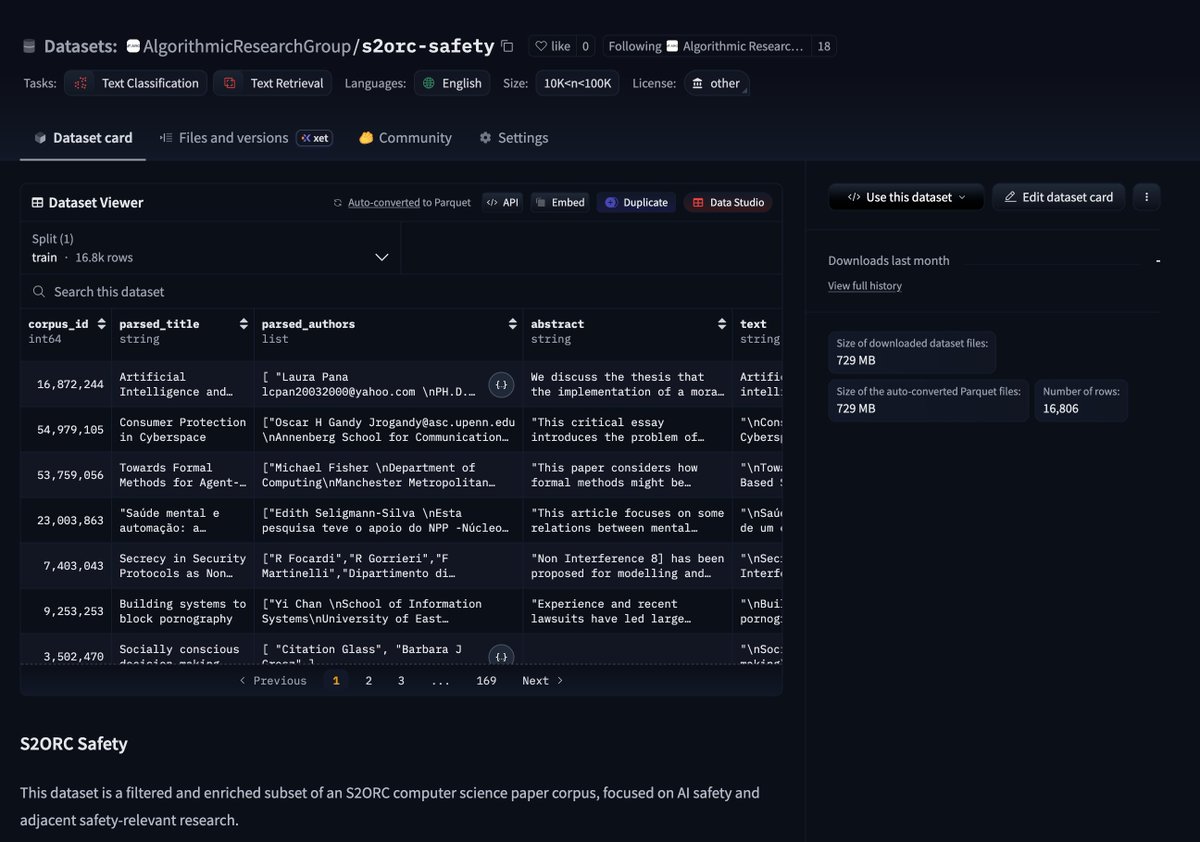
We're releasing 's2orc-safety' on @huggingface: a AI safety slice of our s2orc-enriched dataset with 16,806 papers across jailbreaks, prompt injection, red teaming, model security, privacy, robustness, alignment, and more.
Each paper is enriched with structured fields for reproducibility, safety taxonomy, experimental details, practicality, normalized model/dataset/metric names,
code-link metadata, and more. Link below:
AlgorithmicResearchGroup's GitHub Sponsors profile is live! You can sponsor us to support AlgorithmicResearchGroup's open source work 💖 https://t.co/SCiLc99Etn
These tasks are tough - we think a broad, open-ended set of research tasks mined from real world repos is the best way to measure progress in automated research. Link below:
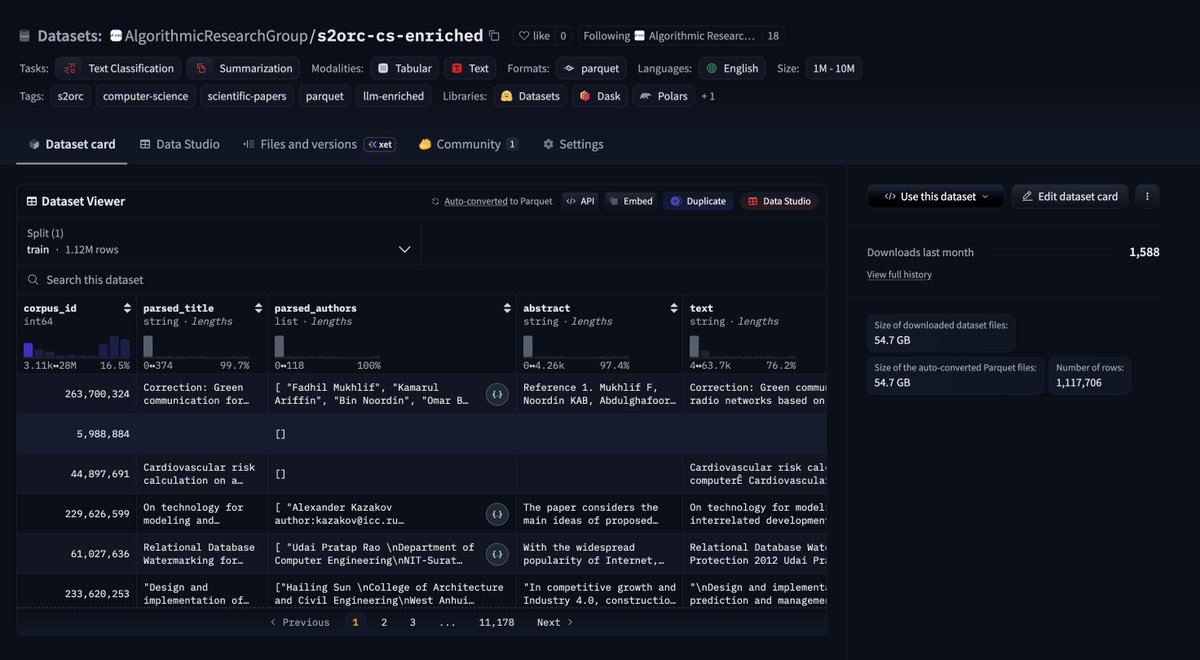
We're releasing S2ORC CS Enriched, a dataset of 1.1 million computer science papers from Semantic Scholar's S2ORC corpus with LLM-generated enrichment fields added to every row.
The base dataset has the full paper text, abstracts, authors, references, citation counts, and venue metadata. We added structured enrichment columns on top: paper summaries, classification, methods used, results, models, datasets, metrics, limitations, and GPU compute details where reported.
The enrichment makes it possible to do things that are hard with raw paper text alone, like filtering for papers that used a specific method, or finding papers that report GPU hours, or building training data for models that need to understand the structure of research papers rather than just their text.
1,118 parquet files, 44 GB total. Available on @huggingface
https://t.co/Mp2s7suxEE
We're excited to release HF agent - a multi-agent @huggingface model-selection and fine-tuning system that investigates current options, searches the web and Hugging Face, and produces Markdown recommendation reports with citations and code snippets. Link below
This was a fun weekend little side project to help navigate the open source repos. Uses the web and HF apis to make suggestions, provide code snippets and more. Reports are saved to @huggingface buckets, and it serves up a Spaces static site for your reports