Traditional RAG sucks because it promises "relevant chunks" but in fact returns "similar chunks".
Relevancy requires reasoning.
Introducing ReAG - Reasoning Augmented Generation
How to Scale Your Model
Google DeepMind just released an awesome book on scaling language models on TPUs.
This is gold!
Worth checking you are an LLM developer.
Language Models Use Trigonometry to Do Addition
"We first discover that numbers are represented in these LLMs as a generalized helix, which is strongly causally implicated for the tasks of addition and subtraction, and is also causally relevant for integer division, multiplication, and modular arithmetic. We
then propose that LLMs compute addition by manipulating this generalized helix using the “Clock” algorithm: to solve a + b, the helices for a and b are manipulated to produce the a + b answer helix which is then read out to model logits. "
Woow a fully open source reasoning model on par with OpenAI o1 just released
Deepseek R1 even outperforms Claude 3.5 Sonnet and o1-mini in almost all benchmarks.
You can already use it for free (see below)
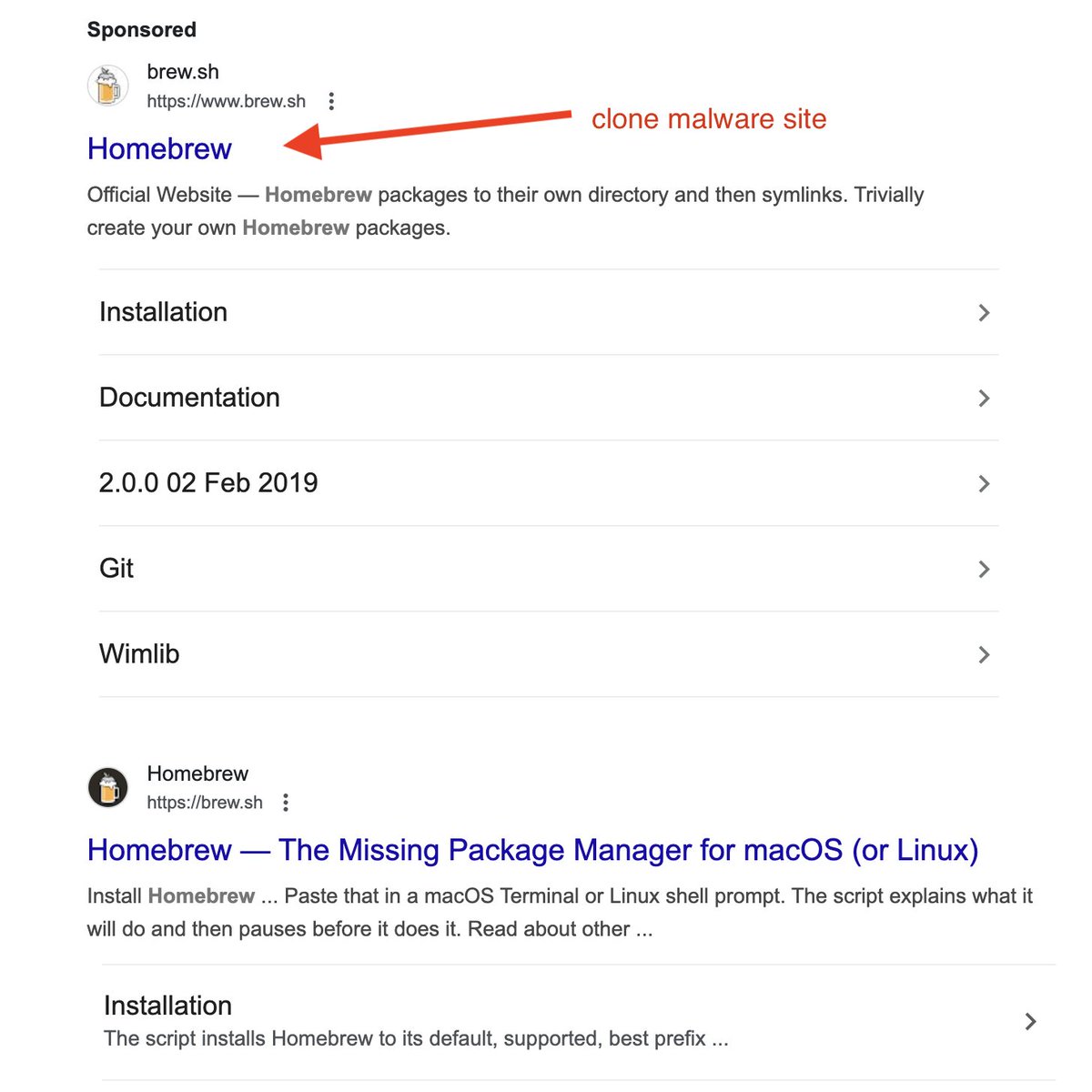
⚠️ Developers, please be careful when installing Homebrew.
Google is serving sponsored links to a Homebrew site clone that has a cURL command to malware. The URL for this site is one letter different than the official site.
🌻kotaemon
An open-source clean & customizable RAG UI for chatting with your documents
Built with both end users and developers in mind. You can use off the shelf, or easily customize
https://t.co/nKSe4sBYHM
Optimizing LLM-based Multi-Agent Systems
Presents a novel framework, OPTIMA, to enhance both communication efficiency and task effectiveness in LLM-based multi-agent systems through LLM training.
Proposes an iterative generate, rank, select, and train paradigm with a reward function to improve performance, token use, and communication efficiency. Integrates Monte Carlo Tree Search-inspired techniques for DPO data generation to encourage diverse exploration.
OPTIMA shows consistent improvements over single-agent baselines and vanilla MAS based on Llama 3 8B, with 2.8x performance gain with less than 10% tokens on tasks requiring heavy information exchange.
Useful Prompting technique.
Simply ask the LLM to re-read the question - significantly boosts LLM reasoning across diverse tasks and model types. 💡
Repeats question input twice in prompt, unlocks latent reasoning potential
**Problem** 🤔:
Decoder-only LLMs with unidirectional attention struggle with nuanced reasoning tasks due to limited global understanding of input questions.
**Key Insights from this Paper 💡**:
• Re-reading (RE2) input enhances reasoning by improving question comprehension
• Enables "bidirectional" understanding in unidirectional LLMs
• Compatible with existing thought-eliciting prompting methods
• Effective across various LLM types and reasoning tasks
**Solution in this Paper** 🔍:
• Introduces RE2 (Re-Reading) prompting method:
- Repeats question input twice in prompt
- Enhances input understanding before reasoning
- Allows tokens to attend to full context in second pass
• Compatible with Chain-of-Thought and other prompting techniques
• Applicable to zero-shot, few-shot, and self-consistency settings
**Results** 📊:
• Consistent improvements across 14 datasets and 112 experiments
• Effective for both instruction-tuned (ChatGPT) and non-tuned (LLaMA) models
• Increases n-gram recall between generation and input question
• Most effective when reading question twice
MemLong utilizes an external retriever for retrieving historical information which enhances the capabilities of long-context LLMs.
It consistently outperforms other SoTA LLMs on long-context benchmarks and can extend the context length on a single 3090 GPU from 4k up to 80k.
RAGEval
Proposes a simple framework to automatically generate evaluation datasets to assess knowledge usage of different LLM under different scenarios.
It defines a schema from seed documents and then generates diverse documents which leads to question-answering pairs. The QA pairs are based on both the articles and configurations.
It seems that this benchmark can help with more reliably evaluating the knowledge usage ability of LLMs and avoids confusion regarding the source of knowledge (parameterized or retrieval).
Direct Preference Optimization (DPO) has become one of the go-to methods to align large language models (LLMs) more closely with user preferences.
If you want to learn how it works, I coded it from scratch: https://t.co/VioT1zVn68
Few #Bitcoin traders understand this:
If you want to long BTC with leverage. DON'T buy futures, buy spot BTC with margin.
EXPLAINER
(1) Buying futures can be fulfilled by any counter trader who has USD collateral, together you are minting new synthetic BTC to the supply which creates a bearish environment.
(2) When buying spot with margin (borrowed USD), only BTC holders can sell it to you. This creates a supply shortage and a very bullish environment.
BONUS
In a bull market it's much cheaper to fund a long position with borrowed USD or USDT than with calendar futures or perps.
Attention Instruction: Amplifying Attention in the Middle via Prompting
Key findings:
1. LLMs lack relative position awareness
2. We can guide LLM to a specific region with position-based indexing
Paper: https://t.co/G7u2lr2QOv
Thanks to: @mengzaiqiao and @nigelhcollier
Cool paper proposing a graph-based agent system to enhance the long-context abilities of LLMs.
It first structures long text into a graph (elements and facts) and employs an agent to explore the graph using predefined functions guided by a step-by-step rational plan. The agent accesses coarse graph components and detailed text, takes notes, and reflects until enough information has been gathered to generate an answer.
This approach helps to effectively and reliably generate answers to questions. Claims to consistently outperform GPT-4-128k across context lengths from 16k to 256k.
You can never sleep on the power of graph or tree structures which in this case helps to capture long-range dependencies and multi-hop relationships within long text. Similar to other tree structures I have reported in the past paper tweets, the agents now get to leverage enriched information to solve tasks.
Large Language Models Must Be Taught to Know What They Don't Know
abs: https://t.co/Y8mZli388Y
Prompting is not enough for LLMs to produce accurate estimates of its uncertainty of its responses, but can be finetuned with as little as 1000 examples and outperform baselines for estimating LLM uncertainty.