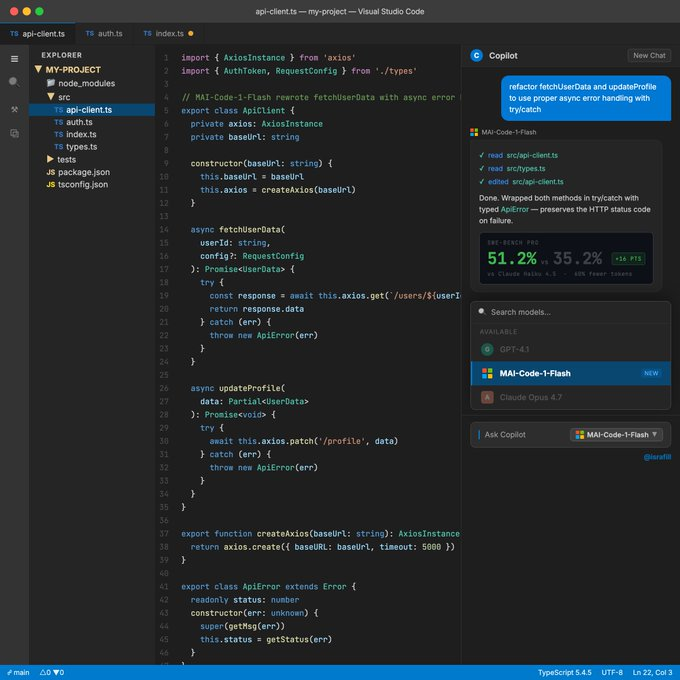
MICROSOFT JUST LAUNCHED THEIR OWN CODING AI INSIDE GITHUB COPILOT — AND IT IS COMPLETELY FREE STARTING TODAY.
Not rented from OpenAI.
Not built on OpenAI data.
Built by Microsoft. Trained inside Copilot's production environment. Rolled out to every Copilot tier right now.
It is called MAI Code 1 Flash.
Here is what makes it different from every other coding model in the picker:
- 60% fewer tokens on complex tasks versus comparable models.
- 85.8% on Microsoft's adversarial coding benchmark.
- 256K context window.
- Trained inside the environment it ships in rather than externally tested then handed over.
Here is the full setup in 6 steps:
Step 1: Create a free GitHub account at https://t.co/f2E5e1Cg7I
Step 2: Enable GitHub Copilot at https://t.co/ucLktYlQQ0 and select the free plan. No credit card required.
Step 3: Install the VS Code extension. Open VS Code, press Ctrl+Shift+X on Windows or Cmd+Shift+X on Mac, search GitHub Copilot, install the extension by GitHub.
Step 4: Sign in. VS Code will show a Sign in to GitHub prompt. Click it, approve in the browser, return to VS Code.
Step 5: Open Copilot Chat. Press Ctrl+Shift+I on Windows or Cmd+Shift+I on Mac.
Step 6: Select MAI Code 1 Flash from the model dropdown at the bottom of the chat panel.
Already have Copilot? Skip straight to Step 5.
Free coding model wars just got serious.
Bookmark this before you pay for another coding subscription.
Follow @cyrilXBT for every free AI coding tool the moment it drops.
We just published internal data on how much of Claude's development is already being done by Claude:
- Over 80% of all code merged into our codebase is now written by Claude
- It's been months since many researchers at Anthropic hand-wrote code
- The typical Anthropic engineer ships 8x as much code as they did in 2024
- On the most open-ended engineering tasks, Claude's success rate jumped from ~26% to 76% in 6 months
- When research sessions went off-track, Claude proposed a better next step than the human took 64% of the time
We're not at recursive self-improvement yet, but it could come sooner than most expect. I highly recommend reading the full blog post.
THIS IS VERY CONCERNING.
Anthropic just called for a global pause in AI development, warning that AI is getting close to improving itself without human help.
In April 2026, Claude ran a full AI research project completely on its own. Humans picked the topic. Claude came up with every experiment, ran every test, and delivered the results.
Two human researchers spent a full week on the same problem and got 23% of the way there.
Claude got 97%.
Claude Mythos Preview is now 52x faster than a skilled human at improving AI training code. The same task takes a human 4 to 8 hours. Claude does it better.
Claude already writes 80% of Anthropic's own code. Their engineers are getting 8x more work done than in 2024, not because they work harder, but because Claude does most of it.
In March 2024, Claude could handle a 4 minute task on its own. Today it handles 12 hour tasks. That number doubles every 4 months. Week long tasks are expected by 2027.
Anthropic warns once AI can build and improve its own next version without any human help, nobody knows how fast things move after that or if humans will still be able to control it.
JUST IN: Anthropic co-founder Jack Clark reportedly warned new recruits to “get hobbies that aren’t computers,” saying the company is building a “superhuman coder with nation-state hacking capabilities.”
AI just patched the firmware of a cheap AliExpress MP3 player.
Guy showed Codex a photo of the chip. Codex walked him through dumping the binary firmware via bootloader. Then it analyzed raw machine code, found the buggy sections, and generated a patched firmware.
Let that sink in. AI is reading raw machine code from an unknown chip and fixing it.
We're not just writing code anymore. We're repairing hardware with software the manufacturer never even shipped.
In 2 years nobody throws away broken gadgets — you just ask AI to fix them.
This guy built a local "video -> HLS -> R2" to pipeline, which is cool, but he uses an FFmpeg script to do it. The same task could've been achieved with Mediabunny in about ~10 lines of code, would not need a script, and would probably run 5x faster due to proper HW acceleration.
The thing is: it's not like he didn't use Mediabunny because he hated it. He probably just didn't know Mediabunny existed or that it could do this. Marketing really is hard!
Anthropic engineer showed how one person can run 5 AI agents, that code, test, review, and deploy at the same time.
In 30 minutes they built the whole thing live in one session.
Here's what they cover:
> when to use one agent vs a full team
> how to split work so agents don't step on each other > the exact framework for deciding what each agent handles
that's exactly why, I put together a guide on building agent teams that actually work.
full guide in the article below 👇
it’s in gemini, just create it in ai studio. oh, that’s for your personal google one account. for workspace you need gemini business. no, not gemini advanced, that’s ai pro now. unless you need ai ultra. oh agents? you do that in spark actually. no, not gemini api managed agents, that’s different. for coding use jules. unless you mean the agentic ide, that’s antigravity. no, that’s the old antigravity, download the new one. actually gemini cli is being deprecated, use antigravity cli. no the flash model is smarter than the pro model. unless you need pro. if it’s video, use flow. no, flow uses veo. no, nano banana is images. actually that’s in gemini now. unless you’re in search, then it’s ai mode. no, research is notebooklm. anyway it’s all very simple.
Chinese students are buying GPT-5.4/5.5 and Claude API access from Xianyu/Taobao proxy sellers for almost 96-97% cheaper
People are apparently burning 100M+ tokens a day for like $1 and vibecoding nonstop.
We’re introducing a new GitHub Certified: Agentic AI Developer (GH-600).
As AI agents become part of modern development workflows, this role-based certification focuses on how developers and teams operate, supervise, and integrate agents across the SDLC.
If you’re already working with tools like GitHub Copilot or exploring agent-driven workflows, we’d love your input.
Learn more and get involved. https://t.co/ruiYtlsYnj
🚨You can literally BUY GitHub Stars on Fiverr right now.
$0.45 per star.
A Carnegie Mellon study just exposed 6 MILLION fake GitHub stars across 18k repositories.
startups and open-source projects are raising REAL MONEY by flashing these fake numbers.
Langflow sitting on 148K stars… 48% fake.
Union Labs... 47% fake and has raised $16 MILLION so far
Left: the watermark GPT Image 2 embeds into every image it generates.
Right: SynthID, the fingerprint Google bakes into every Nano Banana and Gemini image.
Invisible to the human eye. Applied during generation, not added after. Designed to survive screenshots, crops, and compression.
Most people using these tools daily have no idea their output is fingerprinted at the pixel level. Every major AI image generator now tags what it produces, and the tag travels with the image wherever it ends up.
You can verify this yourself. Content Credentials Verify detects C2PA markers from OpenAI images. Gemini detects SynthID if you upload an image directly to it.
The images will keep getting more realistic. The identification tech is keeping pace.
PALO ALTO NETWORKS on MYTHOS: "In our testing, three weeks of model-assisted analysis matched a full year of manual penetration testing, with broader coverage."
how did we make kimi k2.6 nearly beat opus 4.7
"open source models are bad at coding" is not a model issue, it's the coding agent harness problem!
if you're using Claude Code to run open source models you ain't gonna make it. they don't want open models to win.
i had a weird week. same model (deepseek v4 pro) ran our internal eval beat opus 6/10 and (kimi k2.6) almost there 5/10.
same prompts, same checkpoints, same temperature. the only thing that moved was which upstream the gateway picked.
i think a lot of "open model bad at coding" is actually "open model on cold cache." when you say a model wins an eval, you're really saying (model + provider + cache state) wins an eval. the harness is the part that decides the second two.
context: i've been working on @CommandCodeAI's open-source path kimi k2.6, deepseek v4 pro, glm, qwen billions of tokens through a fanout of inference providers (building $1/mo Go plan for Command Code agent). by the end kimi k2.6 was hitting 5/10 against opus 4.7 and deepseek v4 pro 6/10 on the harder tool-heavy slices. four small plumbing changes did most of it. none of them touched the model.
a few things i learned that feel general:
1. the biggest single win was one http header.
closed models have prompt caching as a product. open models don't. what they have is prefix cache the inference server keeps the last N forward passes warm on a GPU's KV memory, and a request that shares a prefix with a recent one skips re-prefilling. it's compute-time, not product-tier, and it evaporates the second your request lands on a different node.
a coding agent is pure prefix-cache exploitation. a good system prompt: ~10k tokens, constant. tool list: constant. conversation: append-only. every turn except the very first should be a near-total cache hit. should be.
what we found: through lots of r&d and data wrangling, consecutive turns of the same conversation were getting load-balanced to different gpu pods. each one had to re-prefill our ~10k-token prefix from scratch. ttft was 6-8s. the model wasn't slow. the cache was being stolen from us by the load balancer.
the fix is one line. but working with several providers and load balancing it makes it as a soft pin same value, same pod (best effort). we already had a stable session id in the cli. we forwarded it.
```
ttft dropped from 6-8s to under 1s on cached turns. and it matters for evals too when the prefix-cache is warm, the model spends its whole budget on the new tokens. cold prefill on a small open model eats latency that on opus is invisible because anthropic's fleet has product-tier caching baked in. closed models eat the cost silently. open models eat it loudly and then we blame the model.
think of it like being in an hour long meeting and having coherent understanding of where we are in the conversation. if you had to re-brief yourself from notes every time you spoke, you'd be slow and forgetful. the model is the same.
at Command Code we're building the best coding agent harness for open source models (and closed too!). such a nice fix for our users. save them money, make them faster, and make the model look better for free.
2. canonical model id is the load-bearing abstraction.
we route the same model say `kimi-k2-6` through up to three providers in priority order. provideOne (p1) (lowest p50), then provideTwo (p2), then providerThree (p3). each one wants a different slug: `moonshotai/Kimi-K2-Instruct`, `moonshot/kimi-k2-6`, `@moonshot/kimi-k2-6`. each wants a different request shape (p2 wants `providerOptions.gateway`, p3 wants headers, p1 wants its own auth header).
the temptation is to fork the request shape per provider all the way through the agent loop. don't. we keep one canonical id (`kimi-k2-6`) flowing through the entire request billing, telemetry, evals, fallback. the slug translation happens at exactly one boundary: `getProviderModelId(provider, canonicalId)`, called inside `buildOSSLanguageModel`, called at the moment we hand bytes to the sdk.
this matters most on fallback. when p1 503s mid-stream and we walk to p2, we re-apply `applyEntryOptions(params, entry, canonicalId)` gateway options get rebuilt for the new entry, the message array stays untouched, the canonical id is unchanged. in our usage logs every kimi call is `kimi-k2-6` regardless of which gpu actually served it. evals don't lie about which model you tested.
if you've ever tried to debug "did this turn go to p2 or p3," you know why this matters. caching ergonimics in this are state of art engineering. i've had most fun as an engineer building this.
3/ capability flags need per-provider negotiation.
we ask the gateway for `zeroDataRetention: true` and `disallowPromptTraining: true`. these are request-level, not per-upstream the gateway is all-or-nothing on each. if any provider in our whitelist (`order`) lacks a flag, the gateway refuses with `NoNonTrainingProvidersError` and the request just dies.
initial code path: hardcode both flags on. broke for half our models, because, e.g., novita is no-training but not zdr, fireworks is zdr but not no-training (these change month to month check current capability table, not this list). gateway refused everything.
the fix was to drop each flag independently based on whether anyone in the whitelist lacks it:
(`buildGatewayOptions`, same file.) request goes through with whichever guarantees the intersection of providers actually supports. you don't get to ask for a property that doesn't exist on the set you're routing over.
this is the same shape as the tool-input repair stuff from last week when you hit a wall, the question to ask is "what's the minimal contract this set of upstreams can actually honor in common," not "how do i force my preferred contract through."
not so happy with this, still working out the quirks, and want to enable ZDR vs cost management easy for our users.
4/ the funniest bug was a thinking-mode regression.
deepseek v4 pro, multi-turn through the p2, started 400ing every continuation: "the reasoning_content in the thinking mode must be passed back to the api."
what was happening: the gateway-side converter applies r1's reasoning-stripping logic to v4. r1 returns `reasoning_content` and you have to echo it back. v4 doesn't, and you don't. the converter strips it, the upstream rejects the absence, every multi-turn dies on turn 2.
(`getReasoningProviderOptions`.) deepseek v4 pro now runs as a non-thinking model end-to-end. converter has nothing to drop. multi-turn works.
we lose reasoning. that costs us a couple of points on hard one-shot puzzles. but coding agents are not one-shot puzzles they're 40-turn loops where turn-2-doesn't-400 matters more than chain-of-thought on turn-1.
later we figured out how to teach the open models what's wrong in their toolCalls while repairing the calls runtime, yesterday i made a detailed thread on this, if you're curious.
zoom out:
four things, none of them about the model:
- keep prefix cache hot across a conversation and providers and open models (job of a harness, not the model or provider).
- one abstraction (canonical id at the request layer, slug translation at the sdk boundary) so fallbacks are invisible to billing and evals.
- one filter (drop capability flags independently against per-upstream support sets) so the gateway doesn't refuse on a property mismatch.
- one workaround (disable thinking on a single provider prefix) for an upstream sdk bug that breaks multi-turn. teach the model how to fix its tool calls in deterministic ways instead of just sending it errors which results in a silent failure.
the model didn't get smarter. the harness stopped throwing away its work between turns.
a closed-model harness can be lazy about all four of these because anthropic and openai eat the cost server-side their caching is built in, their model id is unambiguous, their capability flags are consistent, their tool contracts have been pretrained on. an open-model harness can't be lazy about any of them, and if it's lazy about one, the model "loses" an eval/vibe check it would otherwise have won.
deepseek v4 pro now beats opus 4.7 6/10 on our internal evals. kimi k2.6 hits 5/10. nothing about the weights moved.
imo if your open model is "bad at coding," in most cases you're using the wrong coding agent harness that doesn't care about your model and is super generic across hundreds of models or only cares about the closed models with product-tier caching.
you can try all these fixes, they're live.
I almost killed my company on Friday.
$90,000. One Azure bill. Gone.
Let me tell you what happened because I think founders need to hear this.
We built an amazing document intelligence system at Whisperit. It analyzes our customers' files: PDFs, Word docs, scanned documents, using OCR. It works beautifully and user love it.
But we had a bug.
A small email with a zip file. Inside the zip, a PDF. Some weird edge case that created an infinite loop in our code. The virtual machine would crash, restart, and try to reprocess the same document. Again. And again. And again.
We pay more than one cent per page processed.
You can imagine what happened next.
I saw the graph and my stomach dropped. An exponential spike. The kind of curve you want to see on your revenue chart (!!) not your cloud bill. The forecast for next month said $400,000+.
I thought: this must be a mistake.
Emergency 🚨. Check everything. It wasn't a mistake.
The worst part? We had a warning. Back in November we had a $25K unusual spike. We fixed it. Added upload limits. I thought we were safe.
But I never set a spending cap on Azure. Never set up alerts for unusual usage. I knew I should. I just didn't do it.
I went through every stage:
Denial → "this can't be right"
Anger → screaming at myself
Shame → feeling small, really small
Tears → first time in a long time
I cried that evening. Not because of the money, because I imagined having to close Whisperit. My team. Everything we built. Gone because of one missing setting and my stupidity.
The week had been incredible. New version shipping. Lots of new users. Sales going well. Migration going well. Growing the team responsibly. And then Friday hit like a truck.
Remember my last post about mistakes? Yeah. We're still making them. Bigger ones.
$90,000 is the price of a NICE car. Paid for a bug and a missing checkbox.
Here's what I'm doing RIGHT NOW so this never happens again:
1. Hard spending limits on every cloud service — no exceptions
2. Alerts at 50%, 80%, 100% of expected spend
3. Circuit breakers in our processing pipeline — if a document fails 3 times, it stops
4. Weekly cloud cost review — not monthly, weekly
5. Every API endpoint gets a budget ceiling
If you're a founder reading this:
Go set your spending limits. Today. Right now. Before your next meeting. Before your next coffee. It takes 10 minutes and it could save your company.
We move fast. That's our superpower. But speed without guardrails is a bomb with a timer.
I know what doesn't kill you makes you stronger.
I really hope this one doesn't kill me.
Still standing. Barely. Building. 🚀