@AlexShtf@SimiStern@isaacinthesky I think something key is prompting with enough details and always forcing the agent to save MD files that you can use as knowledge transfer from the agent to you.
With that approach it’s a lot easier to structure and know the internals
I've been vibecoding a version of #habbo, and I've got to say it's coming along pretty well
This has been done using mostly Codex 5.3 xhigh.
Very impressive.
Misleading. The bigger the model, the longer it’ll take per token. We could be talking about hours per token.
Yes it’s great to split layers, but can’t possibly be used for a real experience or a replacement to GPU.
Don’t believe everything you read!
"I don't have a GPU" is officially dead 🤯
You can now run 70B model on a single 4GB GPU and it even scales up to the colossal Llama 3.1 405B on just 8GB of VRAM.
AirLLM uses "Layer-wise Inference." Instead of loading the whole model, it loads, computes, and flushes one layer at a time
→ No quantization needed by default
→ Supports Llama, Qwen, and Mistral
→ Works on Linux, Windows, and macOS
100% Open Source.
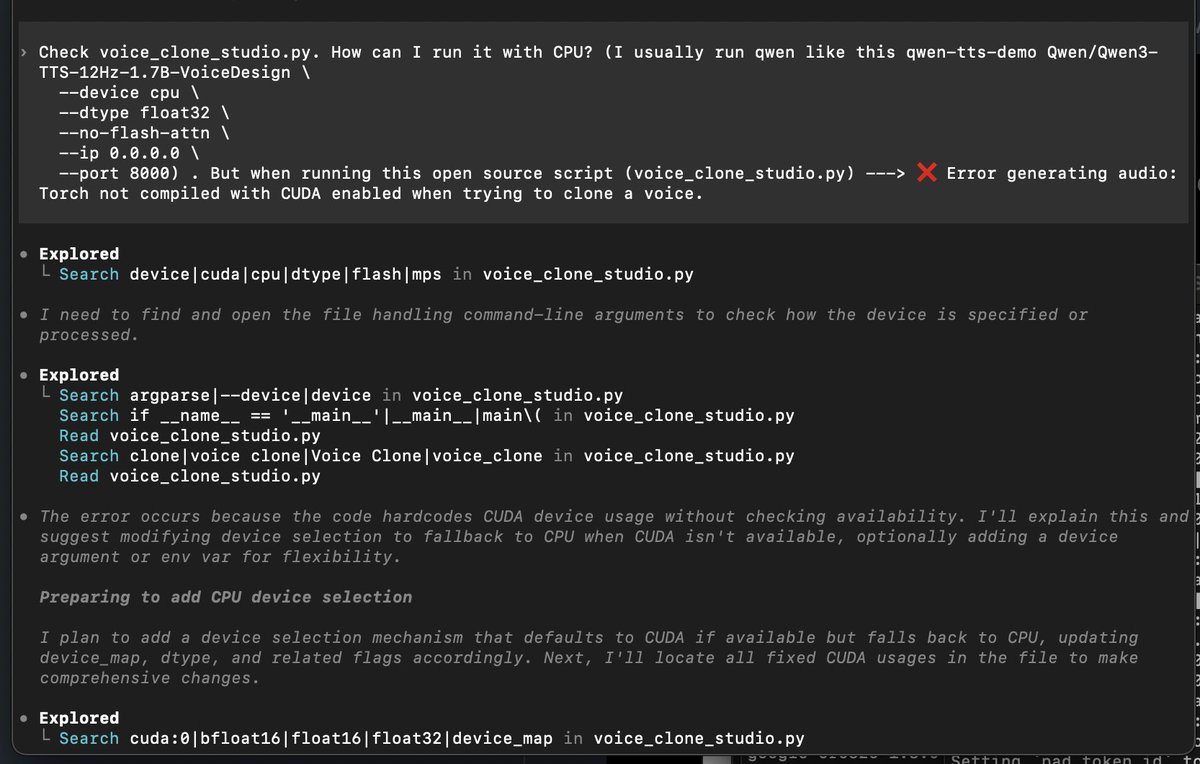
Qwen-3 TTS is way better than I expected.
After a bit of tweaking, I:
- Ran it locally on an M1 Mac
- Modified Voice-Clone-Studio using @OpenAI Codex
- Cloned a voice in ~5 minutes
The audio is genuinely indistinguishable from reality.
@_MehdiSharifi_@eachlabs I’ve seen a lot of generations with JSON prompting. Is there an objective measure to JSON being more successful in its results or is it just control illusion?
From my own testing, it seems you can achieve the same with markdown ?
1/ Why?
Nodra is built on top of @Cloudflare’s Pingora. As a huge fan of the developer tooling by Cloudflare, I wanted to explore if we could create Vercel but for ingress, and that’s what @nodracloud intends to do.
1/ Ingress should be declarative and standardized. We built Nodra to handle the infrastructure complexity so you don't have to.
Waitlist is open: https://t.co/SogtRE1oVW
Here is what it does 🧵🧵