5 years ago Google and Facebook spun up "next billion users" initiatives to capture new users from India and Brazil. Soon we'll see the "next trillion users", but the "users" will live in data centers
As a daily @claudeai user, Chat Log is my top feature request to help navigate long conversations. I built a concept with Claude Code to imagine what this feature could look like. Love to hear if you all face the same challenge!
Check it out @mikeyk@AnthropicAI
Oracle's earnings report is absolutely wild
Remaining Performance Obligations—
• Estimated: ~$180 billion
• Reported: $455 billion
"Most of the revenue in this 5-year forecast is already booked in our reported RPO."
I'm closely watching single-node compute engines. Single-node data processing is not new, but recent creative products are making it more accessible for data teams.
Distributed engines like Spark, Trino, Redshift, and Snowflake handle large volumes. For slicing subsets or fast prototyping, single-node engines offer speed without the cost of scale.
@_hex_tech integrates this in notebooks, connecting to warehouses for big pulls, then using DuckDB for subsequent cells.
@dbt_labs Fusion engine compiles models to SQL, enabling single-node testing before hitting the warehouse.
On the open source side, engines like DuckDB and DataFusion provide fast compute for data that fits on one machine.
As I see more teams looking to cut data platform costs and move faster, this could be a smart option to consider, in addition to optimizing their primary engines for ETL and query serving.
Could Salesforce dominate the data market? Benioff claims they're targeting Databricks and Palantir (each ~$4B ARR).
In May, Salesforce acquired Informatica for $8B, providing ETL/data prep. They also own Tableau (query engine + visualization), MuleSoft (integration), and AgentForce (AI agents + activation).
Still - despite their aggressive pursuit of a full data stack, Salesforce is rarely seen as a key player in the modern data landscape.
A major challenge is that data teams want to extract data from silos like Salesforce into platforms they can own and curate. Building a comprehensive data platform requires significant focus and technical depth, as shown by Databricks, Snowflake, and Palantir becoming massive businesses despite competition from the hyperscalers.
But if Salesforce can figure it out, their strength in downstream data activation and ability to sell into enterprises could make them a dark horse to win a solid share of the data market.
Ready to scale your data science and ML? Choosing the optimal technology is key. My new blog post cuts through the noise and provides a practical guide to scaling your Python workflows, empowering you to do more, faster and cheaper.
Read the blog here:
https://t.co/pSiHzZ0ww2
Everyone talks about Apache Spark, but is it really the best engine for AI? 🤔 I spent hours researching the engines powering scalable machine learning and data science so you don't have to! (1/...)
This is for the data scientists and ML engineers who are:
- Writing Python code to analyze data
- Training and tuning machine learning models
- Performing scientific or geospatial analysis
- Analyzing unstructured data like text, images, and videos
(2/...)
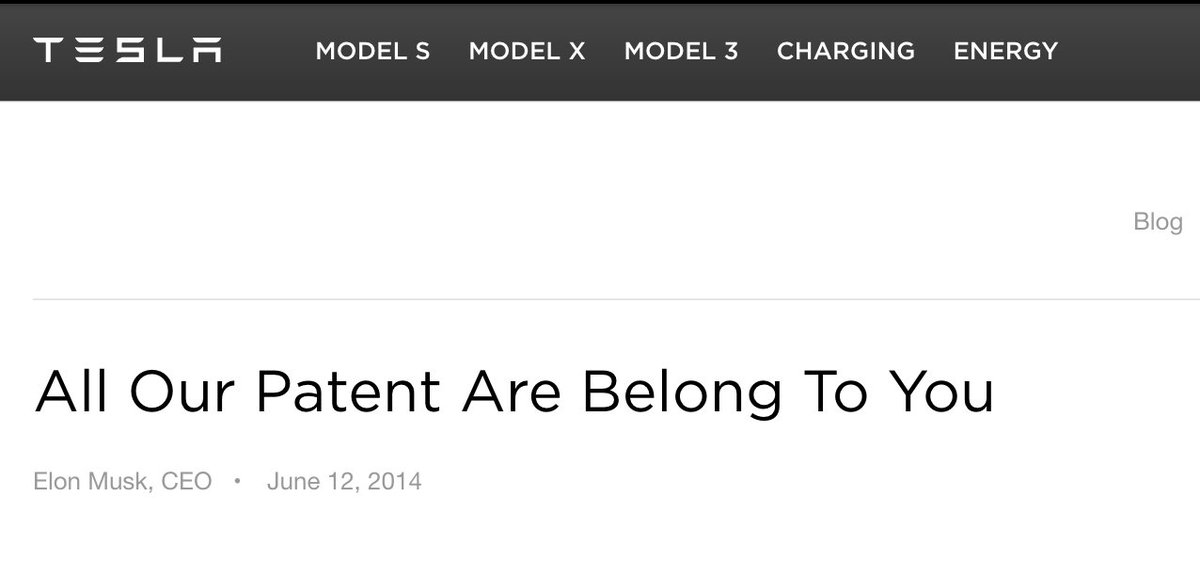
In 2014, @elonmusk open sourced all of Tesla's patents, with the goal of expanding the electric vehicle market. Since then, annual EV sales have grown from 0.3 million to over 14 million (>4,000% increase). We are about to witness the same for AI.