🧵 Your DiT, faster
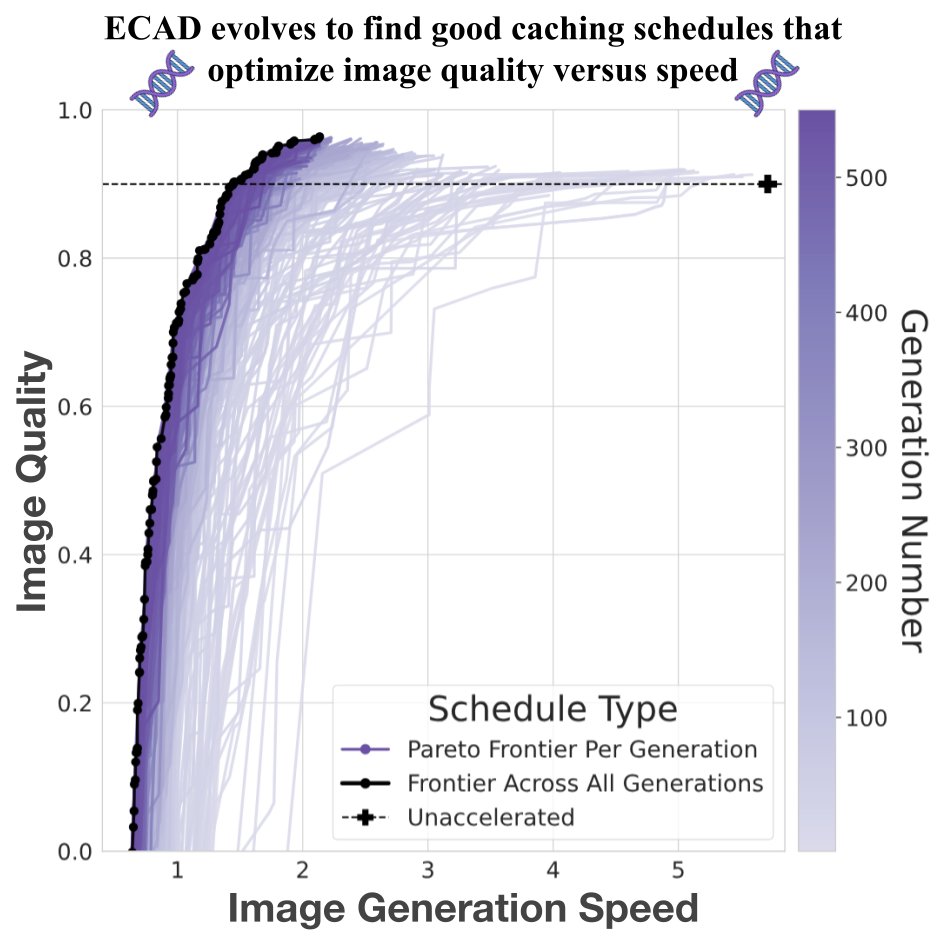
Introducing ECAD: we reframe diffusion model caching as multi-objective optimization and evolve Pareto-optimal schedules via a genetic algorithm—achieving 4.47 FID gain at 2.58× speedup, with no retraining or tuning.
🔗 https://t.co/RBF5SuguTd
#MachineLearning
We’re looking forward to presenting UPLiFT at #CVPR2026! Efficiently extract pixel-dense features from pretrained backbones like DINOv3.
We’ll be at the final poster session on Sunday (6/7) from 3:30-5:30pm at Poster 474, so please come by!
Website: https://t.co/Wng5ZfzjGA
@LunjunZhang Agreed on this. I'm very bullish on using EAs in particular in areas that gradients are expensive / impossible to commute and RL would be slow or unstable (see my paper ECAD). Combining them is super clever :)
Excited to announce that UPLiFT has been accepted to #CVPR2026!
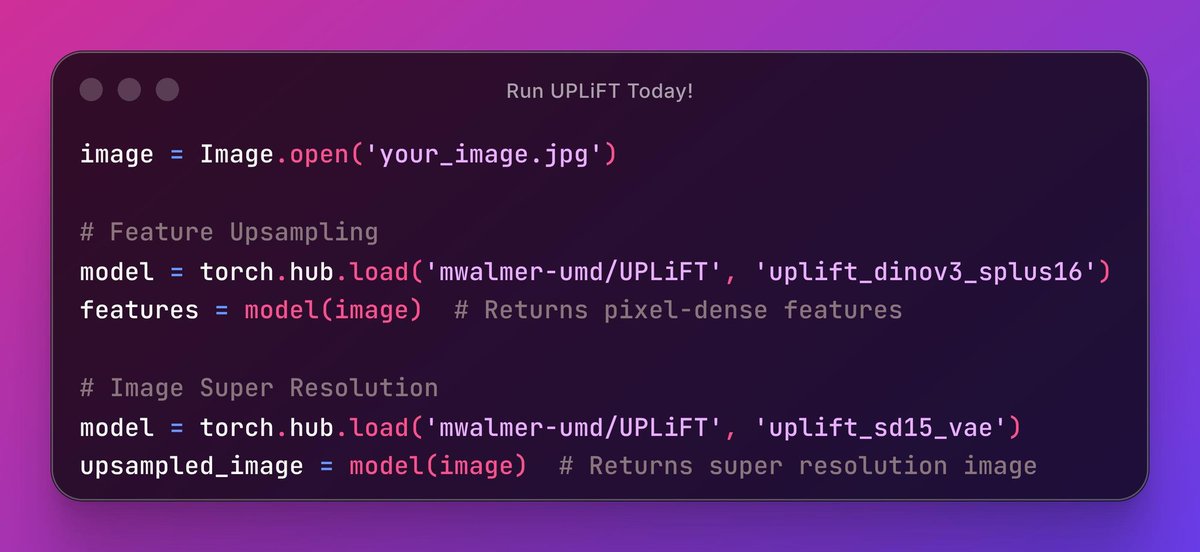
You can also try out UPLiFT right now to extract pixel-dense DINOv3 features with our pretrained models linked below!
Code: https://t.co/slgetOBNPO
Paper: https://t.co/9IqMewyZeG
Website: https://t.co/MJ78gJpXAJ
@massiviola01 Yes! We have a low memory mode that is super efficient in memory, but adds some latency (by running some operations in sequence rather than in parallel). We will add this to the released code repo this weekend! Thanks for your interest in our work 😁
🎉 Thrilled to share that my first research paper has been accepted to #ICLR2026! 🎉
I’ll be attending in person in Rio and would love to connect with others! 🇧🇷
🧵 Your DiT, faster
Introducing ECAD: we reframe diffusion model caching as multi-objective optimization and evolve Pareto-optimal schedules via a genetic algorithm—achieving 4.47 FID gain at 2.58× speedup, with no retraining or tuning.
🔗 https://t.co/RBF5SuguTd
#MachineLearning
Super excited to announce our paper! Upsample any latents (DINO, VAE, etc.) in linear time (compared to quadratic cross attention).
Our models are all available on Hugging Face and Torch Hub with just one line of code!
(please star the GitHub repo 🥺)
https://t.co/vHqlDxPTMe
We’re excited to announce UPLiFT, our lightweight, pixel-dense feature upsampler. UPLiFT boosts feature density, preserves semantics, and has better efficiency scaling than recent SOTA methods. See all links in the thread below.
Coauthors: @_sakshams_@AnirudAgg@abhi2610
🧵[1/6]
@HrishbhDalal@MatthewWalmer@_sakshams_@abhi2610 Agreed, but even without a larger size, I'm of the opinion that using a modern VAE and multi scale image generator for training (FLUX, maybe?, which has larger latents) would achieve really strong image super res, super efficiently.
We’re excited to announce UPLiFT, our lightweight, pixel-dense feature upsampler. UPLiFT boosts feature density, preserves semantics, and has better efficiency scaling than recent SOTA methods. See all links in the thread below.
Coauthors: @_sakshams_@AnirudAgg@abhi2610
🧵[1/6]
@prodarhan@IamKyros69 Only if you first reconceptualize diffusion caching as a multi-objective optimization problem and apply a genetic algorithm to find an optimal speed quality trade-off to do inference with
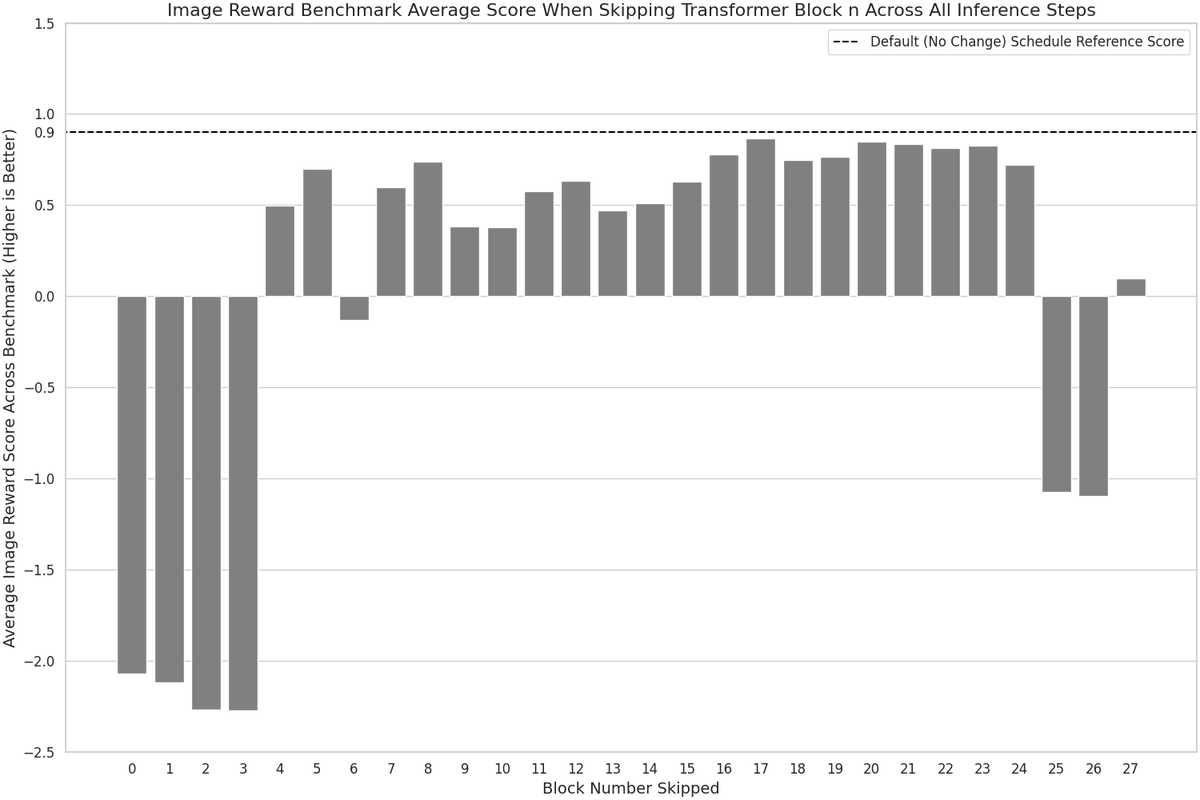
@psandovalsegura Super interesting! Also seeing computational redundancy in DiTs. Some tokens cache well across timesteps (arXiv:2410.05317) and some entire blocks can be skipped (hasty plot). Maybe they could be pruned like your attention heads? Though uncertain of its practical application haha




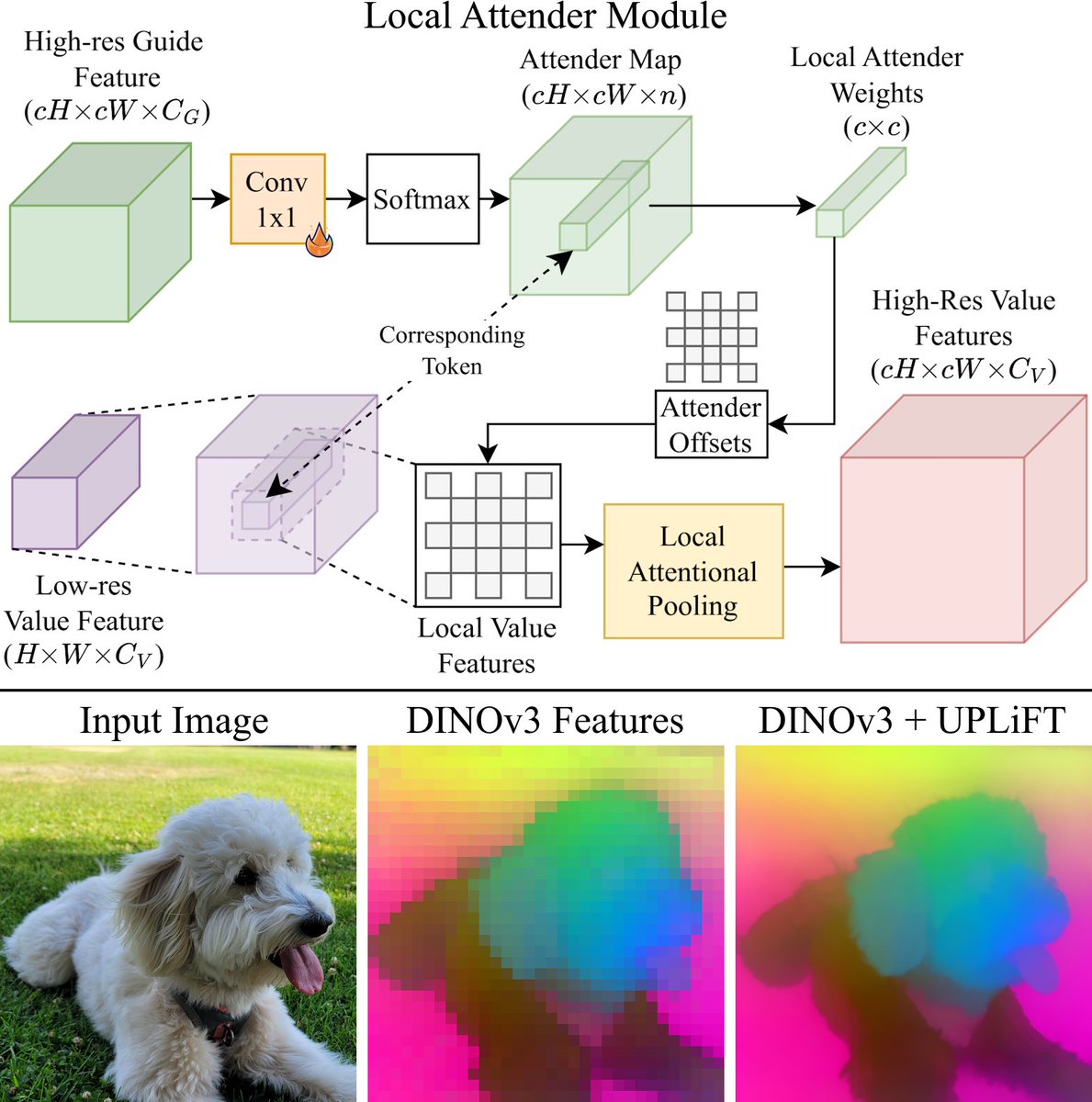

![MatthewWalmer's tweet photo. We’re excited to announce UPLiFT, our lightweight, pixel-dense feature upsampler. UPLiFT boosts feature density, preserves semantics, and has better efficiency scaling than recent SOTA methods. See all links in the thread below.
Coauthors: @_sakshams_ @AnirudAgg @abhi2610
🧵[1/6] https://t.co/kjwnKzaGkt](https://pbs.twimg.com/media/G_r4xoMXMAA7CVf.jpg)